机器学习-Unity 3D平衡球[转载]
最近,Unity宣布推出Unity Machine Learning Agent(ML-Agent),将游戏引擎连接到谷歌TensorFlow等机器学习框架中。通过深度强化学习算法,让非玩家角色(NPC)通过不断尝试和犯错,变得更有创造性和策略性。
在游戏开发的过程中,既不能让玩家因过于简单而无聊,也不能因难度太高丧失玩家兴趣。Unity开发者Arthur Juliani表示,Unity的ML-Agent将帮助增加游戏的可玩性。

研究者和开发者可使用ML - Agents SDK将由Unity编辑器创建的游戏和模拟程序转换成可训练智能代理的环境。在这个环境中,只需一个简单的Python API即可使用深度增强学习、演化策略或其他机器学习方法对智能代理进行训练。测试版版的Unity ML – Agents已作为开源软件发布,其中包含了一套示例项目和基线算法用作新手入门。有关机器学习代理工具的github地址, 请访问这里。
环境配置:
Python是机器学习常用的语言,TensorFlow就使用它作为主要开发语言。作为解释语言,它不需要进行编译,对于机器学习所需要的大量原型化和迭代处理有相当高的效率。而且Python开发生态成熟,有许多库可供使用。通过pip(Python Package Index)工具,你可以安装各种基于Python的库。
安装项目所需Python库和工具
安装Jupyter Notebook
Jupyter Notebook是一个开源的Web应用程序,可以让你创建和共享包含实时代码,方程式,可视化和说明文本的文档。 用途包括:数据清理与转换,数值模拟,统计建模,机器学习等等。
输入 pip3 install jupyter 安装Jupyter Notebook。

安装NumPy NumPy是Python语言的开源数学扩展库。支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
输入 pip3 install numpy 安装 NumPy。

安装Pillow
Pillow是PIL(Python Imaging Library,Python图像库)的一个分支,提供了对于开发者许多比较友好和直观的功能。
输入 pip3 install pillow 安装 Pillow。

安装docopt docopt是Python的命令行参数解析器,其基于多年来用于描述程序界面的帮助信息而设计的,因此可以给开发者清晰的输出体验。
输入 pip3 install docopt 安装 docopt 。

安装TensorFlow TensorFlow是现今非常流行的使用数据流图进行数值计算的开源软件库。图中的节点代表数学运算, 而图中的边则代表在这些节点之间传递的多维数组(张量)。这种灵活的架构可让你使用一个 API 将计算工作部署到桌面设备、服务器或者移动设备中的一个或多个 CPU 或 GPU。 TensorFlow 最初是由 Google 机器智能研究部门的 Google Brain 团队中的研究人员和工程师开发的,用于进行机器学习和深度神经网络研究, 但它是一个非常基础的系统,因此也可以应用于众多其他领域。
输入 pip3 install tensorflow 安装 TensorFlow。

在任何学习环境下都有的三种主要对象是:
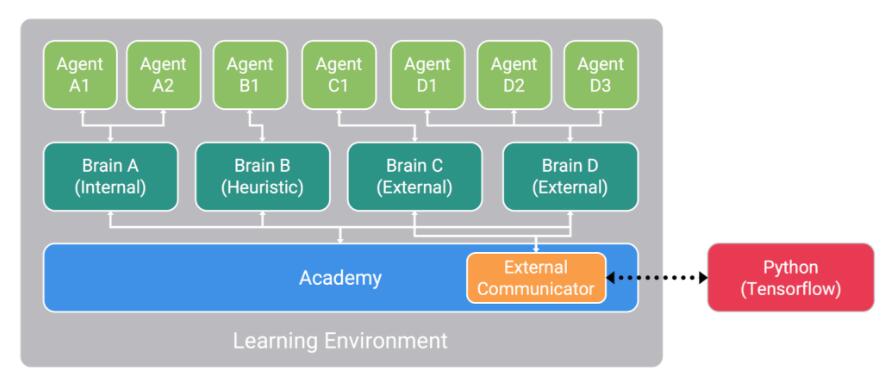
Agent:
每个代理都可以拥有一组独有的状态和观察,在环境中采取独有的行为,并在环境中获得独有的奖励。一个代理的动作由与之相联的大脑决定。
Brain:
每个大脑都定义了一个特定的状态和动作空间,并负责决定每个关联的代理将采取哪些行动。当前版本支持将大脑设定为以下四种模式之一:
-
CoreBrainExternal.cs 动作决策由TensorFlow(或你选择的ML库)决定,我们的Python API负责打开套接字进行通信
-
CoreBrainInternal.cs 动作决策由一个已训练模型决定,该模型使用TensorFlowSharp嵌入项目。
-
CoreBrainPlayer.cs 动作决策由玩家输入决定。
-
CoreBrainHeuristic.cs 动作决策由手工编码(Decision.cs)的行为决定。
Academy:
一个场景中的学院对象也包含了在环境中所有作为子对象的大脑。每个环境都包含单个学院对象,该对象从以下这些方面定义了环境的范围:
引擎配置-在训练和推理模式下,游戏引擎的速度和渲染质量。
跳帧-在每个代理做出一个新的决定之间要跳过多少引擎步骤。
全局迭代长度-单次迭代的持续时间。到时间后,所有代理都将被设置为完成。
所有连接着设置为外部模式大脑的代理,它们的状态和观察都会被外部通信器(External Communicator)收集,并通过我们的Python API与你选择的ML库进行通信。将多个代理设置到单个大脑,可以以批处理方式进行动作决策,从而在系统支持的情况下获得并行计算的优势。
设置Unity环境
运行启动Unity 2017.1,在Unity中打开unity-environment文件夹。在启动窗口中,选择Open,并在弹出的文件浏览窗口中,选择unity-environment,点击Open。
注意:如遇见弹出警告信息为”Opening Project in Non-Matching Editor Installation”,请直接忽略。
打开项目后,在Project窗口,定位到文件夹Assets/ML-Agents/Examples/3DBall/,双击Scene文件的图标,载入所有环境资源。
点击菜单Edit -> Project Settings -> Player,选中Resolution and Presentation里的Run in Background属性。
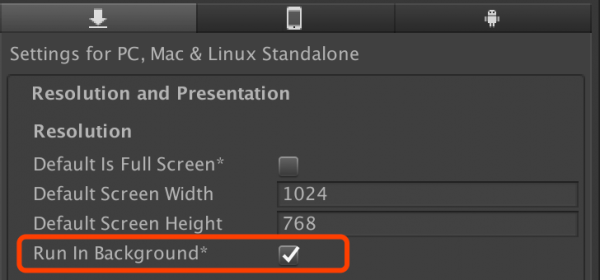
将Resolution and Presentation中的Display Resolution Dialog属性,选择Disabled。
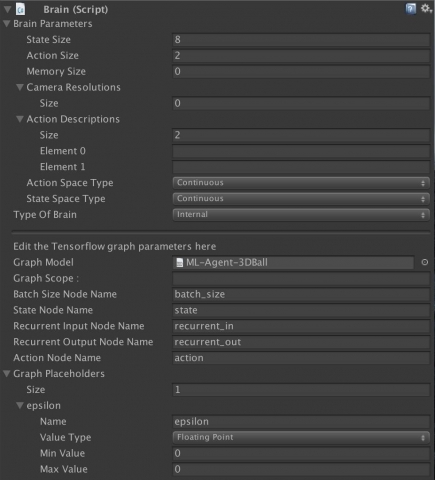
在左边的场景层级窗口中,展开Ball3DAcademy游戏对象,并选中它的子对象Brain3DBrain,在右边的检视窗口中查看属性。
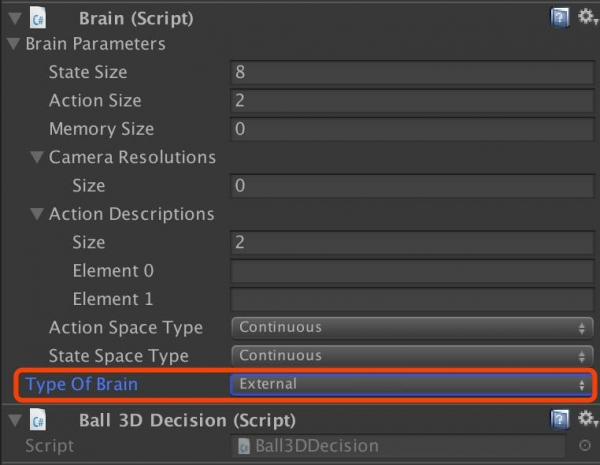
注意:该对象的Type of Brain设置为External。
点击File -> Build Settings,选择构建的目标平台。可以勾选Development Build来记录调试信息。
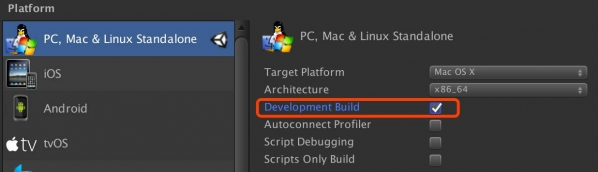
点击Build,保存环境文件到python文件夹中
用强化学习训练大脑
测试Python API
要启动jupyter,在命令行中输入:jupyter notebook。在浏览器中打开localhost:8888,访问notebook文件。
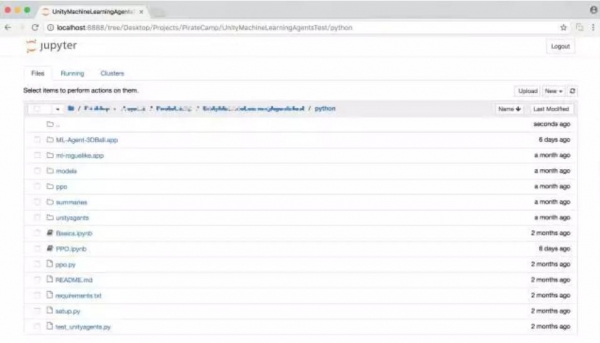
若要确保你的环境和Python API正常运行,你可以在上述窗口中打开python/Basics Jupyter notebook。这个笔记本文件包含一个Python API的简单演示。在这个笔记本文件中,请记得把env_name变量赋值为你刚刚生成的那个文件名
用PPO训练模型
下一步我们训练代理,让它在平台上平衡小球的位置,我们会使用一个叫做近端策略优化(Proximal Policy Optimization),简称PPO的强化学习算法。这个算法经过实验,证明是十分安全、高效且比其他强化学习算法实用性更强的,所以我们选择这个算法来作为Unity机器学习代理的示例算法。
如果想要了解更多关于近端策略优化算法的信息,请参阅OpenAI发布的博客文章:
https://blog.openai.com/openai-baselines-ppo/
要在Ball Balance环境中训练代理,请按以下步骤操作:
-
在Jupyter中打开python/PPO.ipynb
-
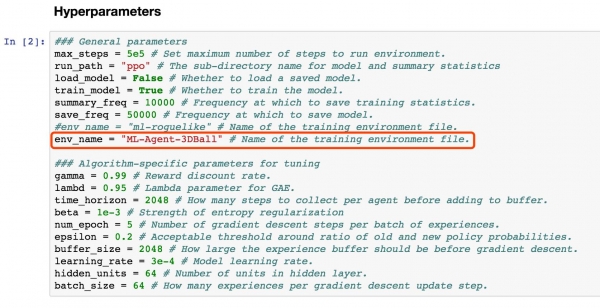
修改env_name的值为刚刚生成的环境文件的文件名
-
按自己需求修改run_path目录
-
运行PPO.ipynb的代码,注意不要运行”Export the trained Tensorflow graph.”这行文字后的代码。
观察训练过程
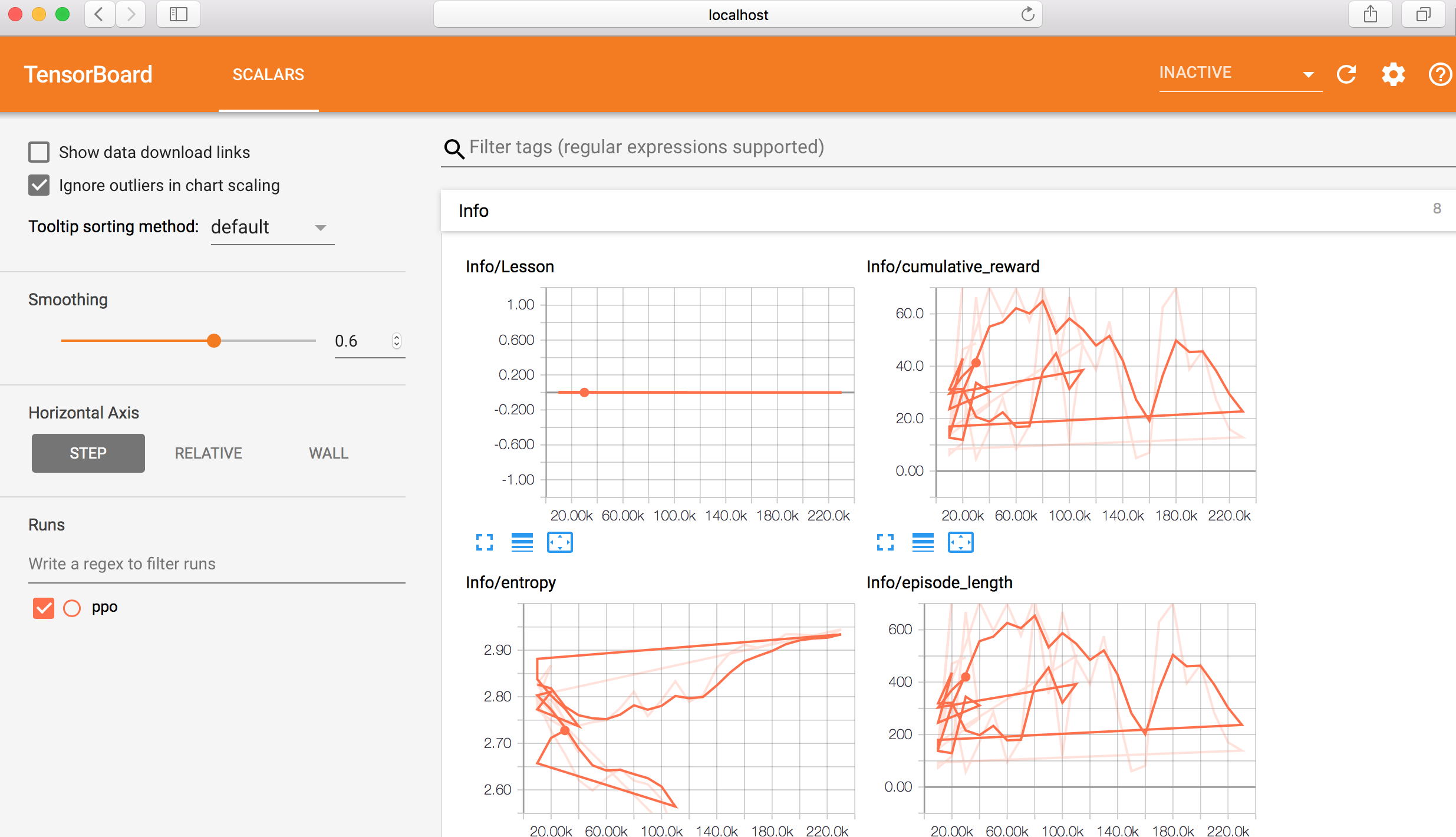
要更仔细地观察训练过程,你可以使用Tensorboard。在命令行中,切换到前面提到的python文件夹下,输入:tensorboard –logdir=summaries

从Tensorboard上,你会看到以下6个变量的统计数据:
Cumulative Reward:所有代理各自的平均累计奖励。在成功的训练过程中,这个变量应该会增大。
Value Loss:数值函数更新时的平均损失。这关系到模型是否能预测每个状态下的数值。在成功的训练过程中,这个变量会减小。
Policy Loss:策略函数更新时的平均损失。这关系到策略(决定行为的过程)的变化大小。在成功的训练过程中,这个变量的大小会减小。
Episode Length:设定环境下,所有代理中每个事件的平均长度。
Value Estimates:代理所访问的所有状态下的平均数值估计。在成功的训练过程中,这个变量数值会增大。
Policy Entropy:这个变量告诉你模型的决定随机度有多大。在成功的训练过程中,这个变量会缓慢减小。如果它减小得太快,beta hyperparameter应该会增大。
将训练好的模型载入Unity环境
当训练过程显示的平均回报为75或更大时,并且模型已经保存过后。你可以通过中止执行代码来停止训练。,现在你就已经有训练好的TensorFlow模型。你必须将保存的模型转换为Unity可使用的格式,这样就可以直接通过以下步骤载入到Unity项目中。
配置对TensorFlowSharp的支持
因为对TensorFlowSharp的支持目前还处于实验阶段,默认情况下它是被禁用的。要打开它,你必须按如下步骤操作。
请注意Internal Brain模式只在完成以下步骤后才能使用。
确保使用的是Unity 2017.1以上版本。
确保TensorFlowSharp插件已导入到Assets文件夹中。包含这个插件的插件包可以在这里下载(https://s3.amazonaws.com/unity-agents/TFSharpPlugin.unitypackage)。双击打开该文件,导入到Unity中。
菜单选择Edit -> Project Settings -> Player。
在Inspector检视窗口中对于你选择的所有平台(PC, Mac, Linux Standalone, iOS ,Android)这样操作:打开Other Settings; 在Scripting Runtime Version属性中选择Experimental (.NET 4.6 Equivalent);在Scripting Defined Symbols属性中,加入ENABLE_TENSORFLOW。