强化学习-游戏AI Trainning (三)
记得半年前,我介绍过强化学习的算法,比如说Q-learning, sara, DQN. 今天我们来介绍两种新的强化学习的算法Policy Gradient。 相较于之前的方法,今天的两种方式更加深入的使用深度神经网络。
本文对应到github工程代码地址:https://github.com/huailiang/bird
git clone https://github.com/huailiang/bird
#切换到PolicyGradient
git checkout PolicyGradient
#切换到ppo分支
git checkout ppoIntroduce
- Policy Gradient
Policy gradient 是 RL 中另外一个大家族, 他不像 Value-based 方法 (Q learning, Sarsa), 但他也要接受环境信息 (observation), 不同的是他要输出不是 action 的 value, 而是具体的那一个 action, 这样 policy gradient 就跳过了 value 这个阶段. 而且个人认为 Policy gradient 最大的一个优势是: 输出的这个 action 可以是一个连续的值, 之前我们说到的 value-based 方法输出的都是不连续的值, 然后再选择值最大的 action. 而 policy gradient 可以在一个连续分布上选取 action.
policy gradient 是一种基于 整条回合数据 的更新, 也叫 REINFORCE 方法. 这种方法是 policy gradient 的最基本方法, 有了这个的基础, 我们再来做更高级的。更新网络中的参数,具体的实现方式如下:
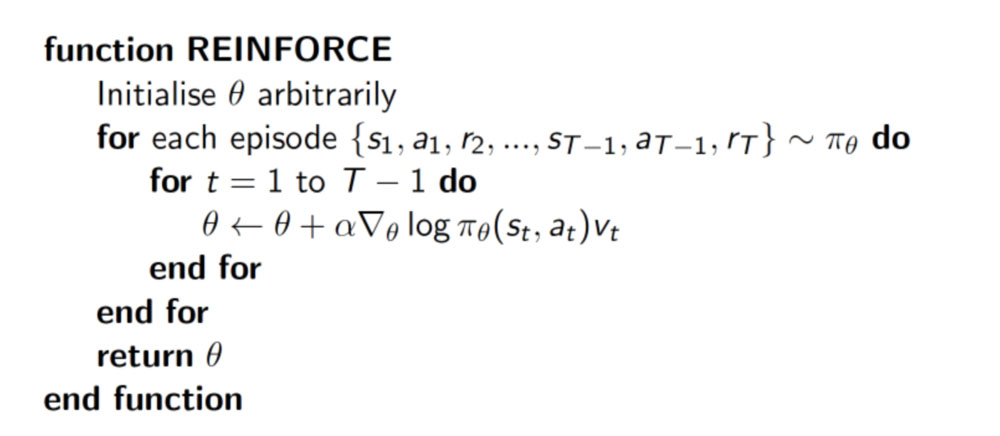
损失函数即:loss= -log(prob)*vt
今天我们的目的不是推导此公式是怎么得来的,而是利用此公式,来实现机器学习的目的。若你想详细了解算法详细的推导过程,可以参考这篇文章。
通过我们公式可以看到,当奖励(vt)越大的时候,在loss不断减少的情况下,prob发生的几率会越大。反之,奖励(vt)越小的情况,随着梯度,prob发生的机会也越小。
- PPO
PPO 是 OpenAI 发表的 Trust Region Policy Optimization,基于 Actor-Critic 算法。根据 OpenAI 的官方博客, PPO 已经成为他们在强化学习上的默认算法。
如果一句话概括 PPO: OpenAI 提出的一种解决 Policy Gradient 不好确定 Learning rate (或者 Step size) 的问题. 因为如果 step size 过大, 学出来的 Policy 会一直乱动, 不会收敛, 但如果 Step Size 太小, 对于完成训练, 我们会等到绝望. PPO 利用 New Policy 和 Old Policy 的比例, 限制了 New Policy 的更新幅度, 让 Policy Gradient 对稍微大点的 Step size 不那么敏感.
官方的paper对ppo有两种实现方式。分别是 KL penalty和Clip的方式。

PPO 是一套 Actor-Critic 结构, Actor 想最大化 J_PPO, Critic 想最小化 L_BL. Critic 的 loss 好说, 就是减小 TD error. 而 Actor 的就是在 old Policy 上根据 Advantage (TD error) 修改 new Policy, advantage 大的时候, 修改幅度大, 让 new Policy 更可能发生. 而且他们附加了一个 KL Penalty (惩罚项, 不懂的同学搜一下 KL divergence), 简单来说, 如果 new Policy 和 old Policy 差太多, 那 KL divergence 也越大, 我们不希望 new Policy 比 old Policy 差太多, 如果会差太多, 就相当于用了一个大的 Learning rate, 这样是不好的, 难收敛.
purpose
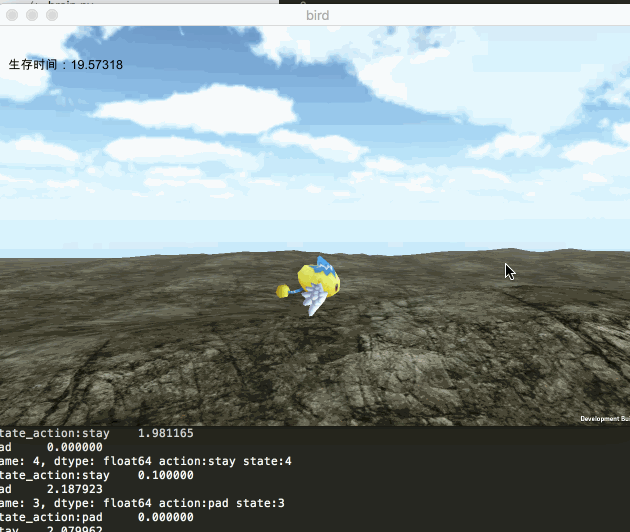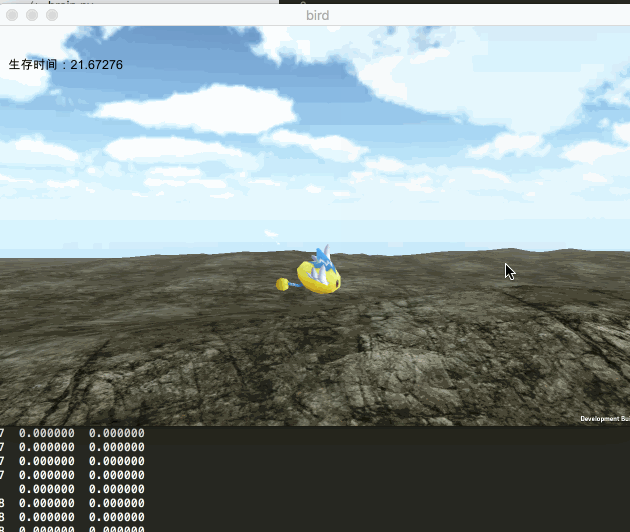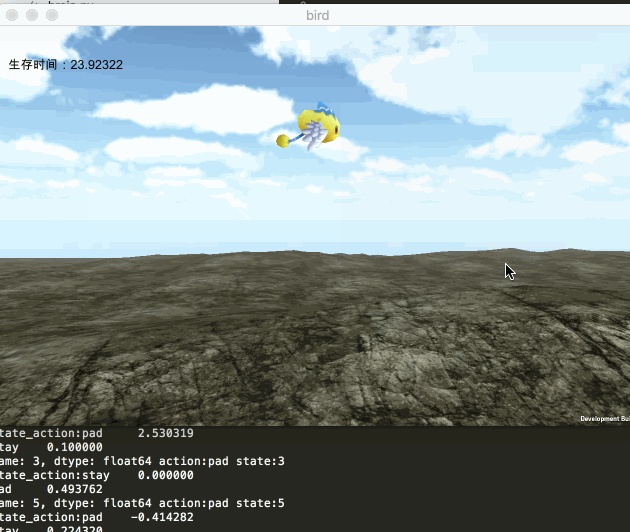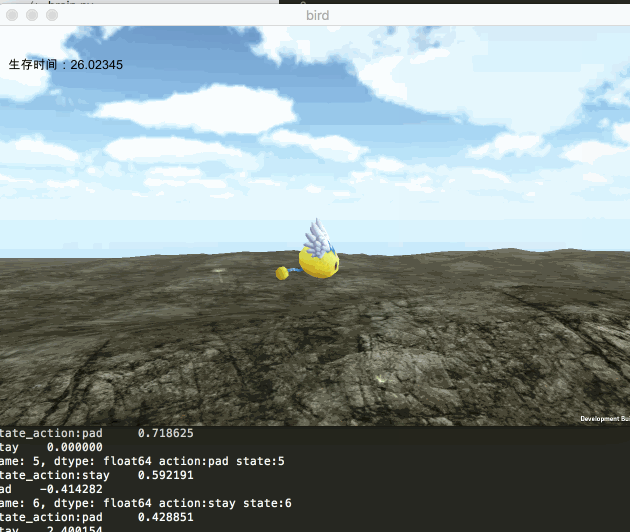
此次我们的目的,还是通过机器学习,使游戏中的小鸟宝宝学会飞翔。我们依旧采用unity来表现,而使用python来拟合神经网络,训练数据。二者之间通过socket来实现数据通信。最终实现的效果如下图所示:
Algorithm
- PolicyGradient
根据github提供的项目,切到PolicyGradient分支,在根目录找到PolicyGradients文件夹,所有的实现都在里面了。
我们使用两个全连接层(fc1,fc2)设计我们的神经网络,
with tf.name_scope('inputs'):
self.tf_obs = tf.placeholder(tf.float32, [None, self.n_features], name="observations")
self.tf_acts = tf.placeholder(tf.int32, [None, ], name="actions_num")
self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value")
# fc1
layer = tf.layers.dense(
inputs=self.tf_obs,
units=10,
activation=tf.nn.tanh, # tanh activation
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc1'
)
# fc2
all_act = tf.layers.dense(
inputs=layer,
units=self.n_actions,
activation=None,
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc2'
)我们根据之前说的policygradient的算法,来设计损失函数(Loss Function)。
即:loss= -log(prob)*vt
with tf.name_scope('loss'):
neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1)
loss = tf.reduce_mean(neg_log_prob * self.tf_vt) # reward guided loss
训练的过程就是减少loss,即沿着梯度下降的方向跟新网咯中的参数:
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss)
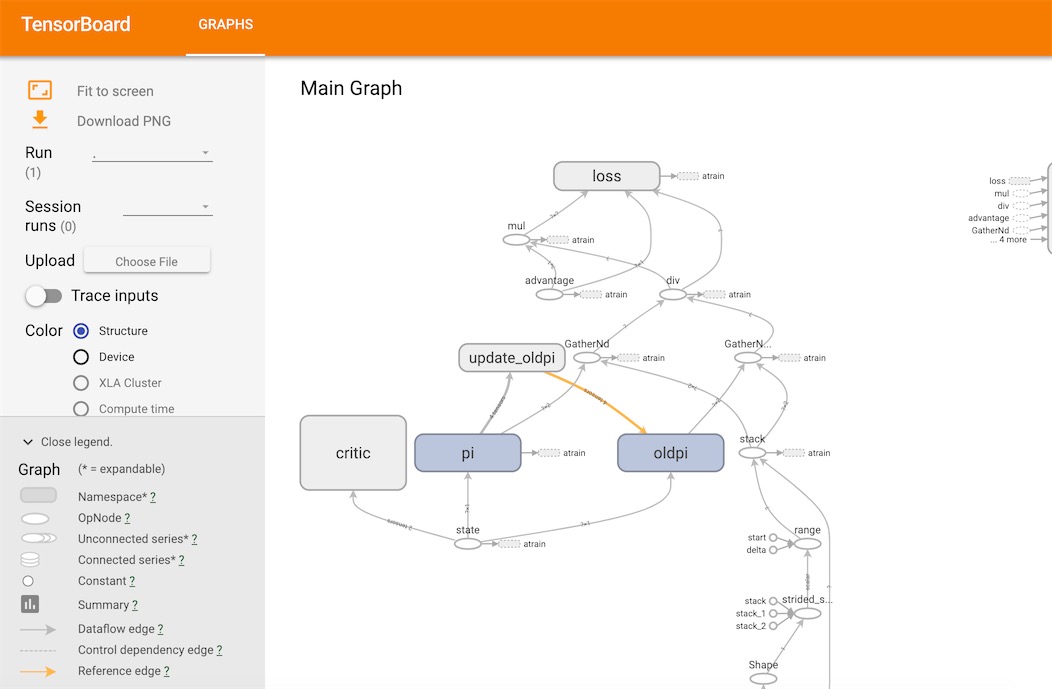
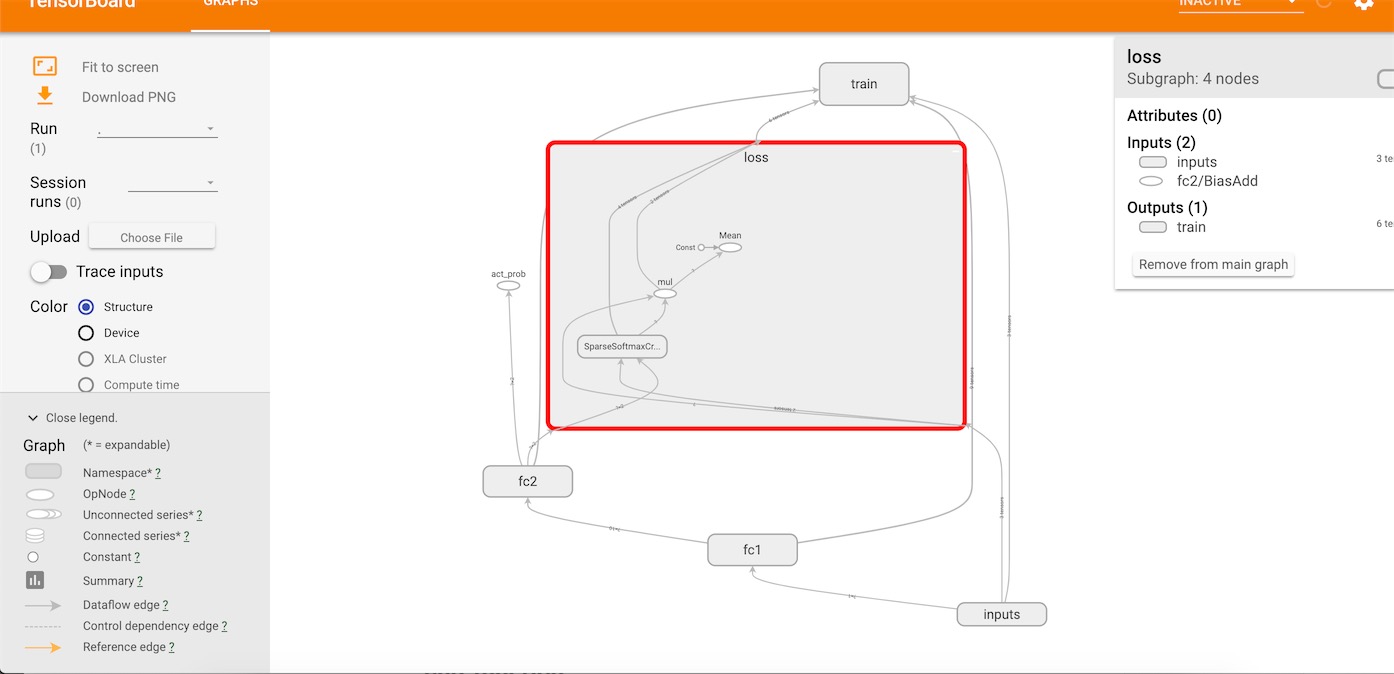
在tensorboard我们可以清楚看到整个网络的结构:
- PPO
根据github提供的项目,切到ppo分支,在根目录找到ppo文件夹,所有的实现都在里面了。这里采用的是官方paper介绍的第二种算法(clip)。看到网络设计上ppo的实现方式很多,有基于连续的,有基于离散的,还有采用多线程来更新网络的参数。
鉴于我们的设计目的是使小鸟学会飞翔,这里我们的实现方式采用的是离散的方式实现ppo。因为我们小鸟采取的动作就两种(fly or pad)。
根据OpenAI官方的Paper,我们设计我们的网络结构。 由于PPO是基于A3C,又是利用两个网络的接近程度来更新网络中的参数,所以这里至少有三个神经网络,即critic, actor1(pi), actor2(oldpi)。
我们实现如下:
#critic
with tf.variable_scope('critic'):
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
self.v = tf.layers.dense(l1, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor pi &oldpi
self.pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
# actor
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l_a = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
a_prob = tf.layers.dense(l_a, A_DIM, tf.nn.softmax, trainable=trainable)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return a_prob, params
我们根据pi和old pi之间测差异决定Loss:
a_indices = tf.stack([tf.range(tf.shape(self.tfa)[0], dtype=tf.int32), self.tfa], axis=1)
pi_prob = tf.gather_nd(params=self.pi, indices=a_indices) # shape=(None, )
oldpi_prob = tf.gather_nd(params=oldpi, indices=a_indices) # shape=(None, )
ratio = pi_prob/oldpi_prob
surr = ratio * self.tfadv # surrogate loss
with tf.variable_scope('loss'):
self.aloss = -tf.reduce_mean(tf.minimum( # clipped surrogate objective
surr,
tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
在tensorboard观察网络结构: