强化学习-游戏AI Trainning (二)
上一节我们介绍了如何 q_learning 强化学习算法, 但不好的地方是运算都在 Unity里,这节我们把 q_learning算法提取到 python 环境中,并且用 Sarsa算法实现一遍强化学习。所有本机的代码都可以在Github 下载。
完成本节内容,你需要本地有如下环境:
- Python2.x
- Pandas
- Numpy
- Tensorflow
Unity设置
本地作者使用的 unity 版本是2017.3, 我们需要导出 Unity mac 平台上的包,我们在导出之前需要做如下设置:
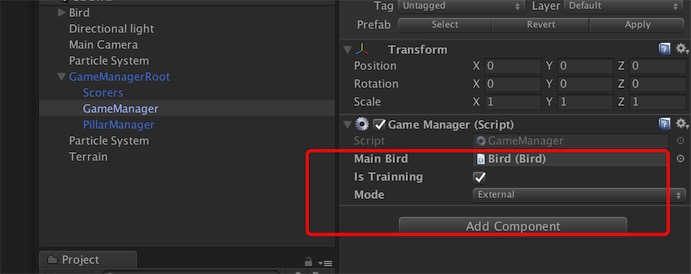
在 GameManager 的 GameObject 上的脚本设置:IsTrainning需要勾上,Mode 选择 External。
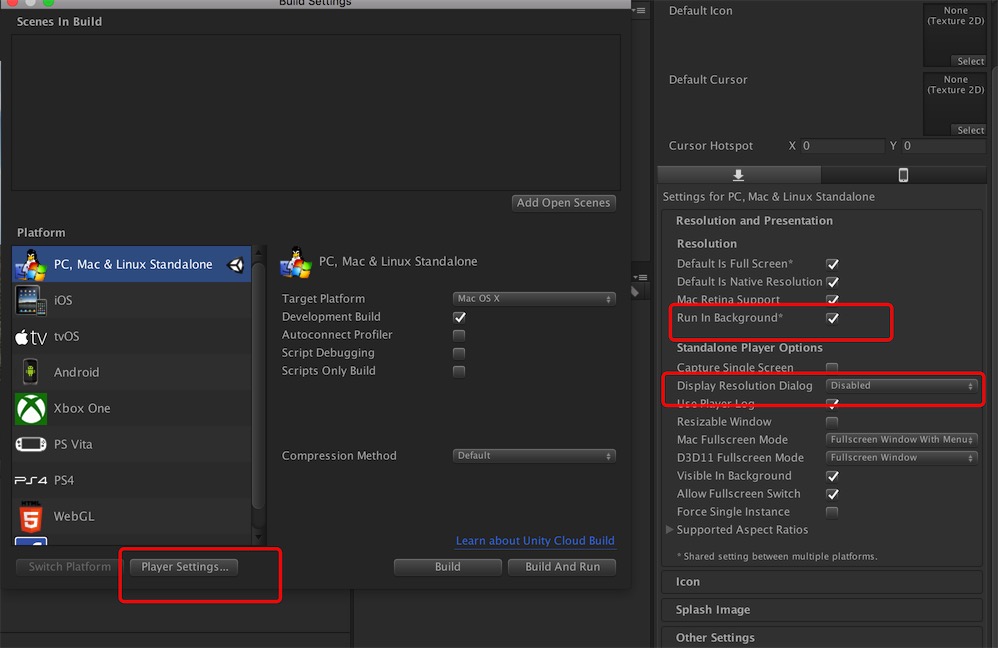
在 PlayerSetting 中需要做如下设置,Run in Background 需要勾上, Display Resoluyion Dialog 选择 Disabled。
选择 build,导出一个 app, 导出的位置对应的/Python目录,并且导出的文件名一定要命名为 bird,这个变量名我们会在 python 使用到。最终的相对目录如下图所示,这个 bird.app 由于大小的原因没有上传到 github,如果读者需要的话,请自行导出。
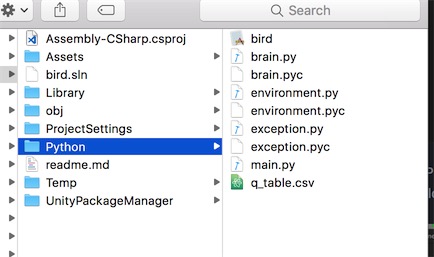
上图同时展示了我们 python 的目录结构,下面我们对几个文件做简要的说明:
-
brain.py
用于q_learning的算法实现
-
environment.py
与 Unity 交互,主要是 Socket
-
exception.py
用于处理异常
-
main.py
启动入口 在这里启动一个 Environment
python 和 c#的交互是通过 Socket 来通信的,这里开了一个默认的端口-5006,关于python 和 c#如何TCP通信的,这里有个简单的GitHub工程,读者可以自行点击学习。
在environment.py 中实现了UnityEnvironment类。
在它的构造函数中,做了以下几件事情:
- 使用atexit注册一个进程退出的函数,在退出的时候关闭 socket
import atexit
atexit.register(self.close)
def close(self):
logger.info("env closed")- 由模块subprocess开启一个子进程用来启动 unity 导出来的包,这里考虑 Linux, Windows, Macos 三种平台的包,考虑的比较全面。
import subprocess
proc1 = subprocess.Popen([launch_string,'--port', str(self.port)])- 建立 Socket, 用于监听的 Unity 侧发过来的参数,设置好超时时间。
self.port = base_port
self._buffer_size = 10240
self._loaded = False
self._open_socket = False
logger.info("unity env try created, socket with port:{}".format(str(self.port)))
try:
# Establish communication socket
self._socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self._socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self._socket.bind(("localhost", self.port))
self._open_socket = True
except socket.error:
self._open_socket = True
self.close()
raise socket.error("Couldn't launch new environment "
"You may need to manually close a previously opened environment "
"or use a different worker number.")
self._socket.settimeout(60)
try:
try:
self._socket.listen(1)
self._conn, _ = self._socket.accept()
self._conn.settimeout(30)
except socket.timeout as e:
raise UnityTimeOutException(
"The Unity environment took too long to respond. Make sure {} does not need user interaction to "
"launch and that the Academy and the external Brain(s) are attached to objects in the Scene."
.format(str(file_name)))
- 解析 socket 发过来的参数,同时初始化 Brain, 在 Brain 中构建一张 q_table。
p = self._conn.recv(self._buffer_size).decode('utf-8')
p = json.loads(p)
self._data = {}
self._global_done = None
self._log_path = p["logPath"]
self._alpha = p["alpha"]
self._epsilon = p["epsilon"]
self._gamma = p["gamma"]
self._states = p["states"]
self._actions = p["actions"]
self._brain = QLearningTable(self._actions,self._states, self._alpha,self._gamma,self._epsilon)
self._loaded = True
self._recv_bytes()
logger.info("started successfully!")
except UnityEnvironmentException:
proc1.kill()
self.close()
raise
在 brain.py中实现了 q_learning和 Sarsa的 reinforcement算法, 二者在根据 state 做选择的是一样的,差别就是二者学习的过程,即更新 q_table 的方式。 q_learning在下一个 state_ 的选择的是action 值最大的 q 值来算 q_target, 而 sarsa是根据 下一个 state_和下一个action_来算 q_target。class RL是基类,显现了二者共同的choose_action,export,而QLearningTable和SarsaTable都继承 RL,并实现了各自的 learn(),即更新 q_Table 的方法。具体的代码实现如下:
import numpy as np
import pandas as pd
import os
class RL(object):
def __init__(self, _actions, _states, learning_rate=0.01, _gamma=0.9, _epsilon=0.9):
self.actions = _actions
self.lr = learning_rate
self.gamma = _gamma
self.epsilon = _epsilon
self.states = _states
self.step = 0
self.csv = "q_table.csv"
self.state_num = len(self.states)
self.action_num = len(self.actions)
self.q_table = pd.DataFrame(np.zeros((self.state_num,self.action_num)), columns=self.actions, index = self.states)
print self.q_table
def choose_action(self, observation):
# action selection
if np.random.rand() < self.epsilon:
# choose best action
state_action = self.q_table.loc[observation, :]
state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
action = state_action.idxmax()
print "state_action:"+str(state_action)+" action:"+str(action)+" state:"+str(observation)
else:
# choose random action
action = np.random.choice(self.actions)
self.step = self.step+1
if(self.step%10==0):
print self.q_table
return action
def learn(self, *args):
pass
def export(self):
print "brain export"
self.q_table.to_csv(self.csv)
# off-policy
class QLearningTable(RL):
def __init__(self, actions, states, learning_rate=0.01, _gamma=0.9, _epsilon=0.9):
super(QLearningTable, self).__init__(actions,states, learning_rate, _gamma, _epsilon)
def learn(self, s, a, r, s_):
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
# on-policy
class SarsaTable(RL):
def __init__(self, actions, states, learning_rate=0.01, _gamma=0.9, _epsilon=0.9):
super(SarsaTable, self).__init__(actions, states, learning_rate, _gamma, _epsilon)
def learn(self, s, a, r, s_, a_):
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, a_]
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update在 Unity 侧,我们使用ExternalEnv.cs 与 python 交互,所有通信的数据结构都定义在ExternalData.cs 中。
我们使用ExternalEnv中,我们在 socket建立起来就会把 q_learning 需要的参数同步到 python, 比如说:
//迭代概率
paramerters.epsilon = epsilon;
//衰减因子
paramerters.gamma = gamma;
//学习率
paramerters.alpha = alpha;
//日志位置
paramerters.logPath = this.save_path;
游戏每15帧触发一个心跳-Tick, 每个心跳做一个决定和更新一次 q_table,这些数据都是通过 socket 连接起来的。然后根据 python 返回的 action 去表现。
public override void OnTick()
{
int state = GetCurrentState();
if (last_state != -1)
{
UpdateState(last_state, state, last_r, last_action);
}
bool action = choose_action(state);
GameManager.S.RespondByDecision(action);
}运行 main.py,最后的表现如下图所示:
深度神经网络
我们学会了利用q_learning来做游戏强化学习,并能提取出来再外部训练,我们继续深入学习使用DQN神经网络来训练我们的模型。首先,你需要本地有如下环境:
- Python
- Pandas
- Numpy
- matplotlib(可选)
- Tensorflow
- Jupyter notebook(可选)
DeepQNetwork
Deep Q Network 的简称叫 DQN, 是将 Q learning 的优势 和 Neural networks 结合了. 如果我们使用 tabular Q learning, 对于每一个 state, action 我们都需要存放在一张 q_table 的表中. 如果像显示生活中, 情况可就比那个迷宫的状况复杂多了, 我们有千千万万个 state, 如果将这千万个 state 的值都放在表中, 受限于我们计算机硬件, 这样从表中获取数据, 更新数据是没有效率的. 这就是 DQN 产生的原因了. 我们可以使用神经网络来 估算 这个 state 的值, 这样就不需要一张表了。
为了使用 Tensorflow 来实现 DQN, 比较推荐的方式是搭建两个神经网络, target_net 用于预测 q_target 值, 他不会及时更新参数. eval_net 用于预测 q_eval, 这个神经网络拥有最新的神经网络参数. 不过这两个神经网络结构是完全一样的, 只是里面的参数不一样。最终运行的Graph在tensorboard上可视化的结果如下图所示:
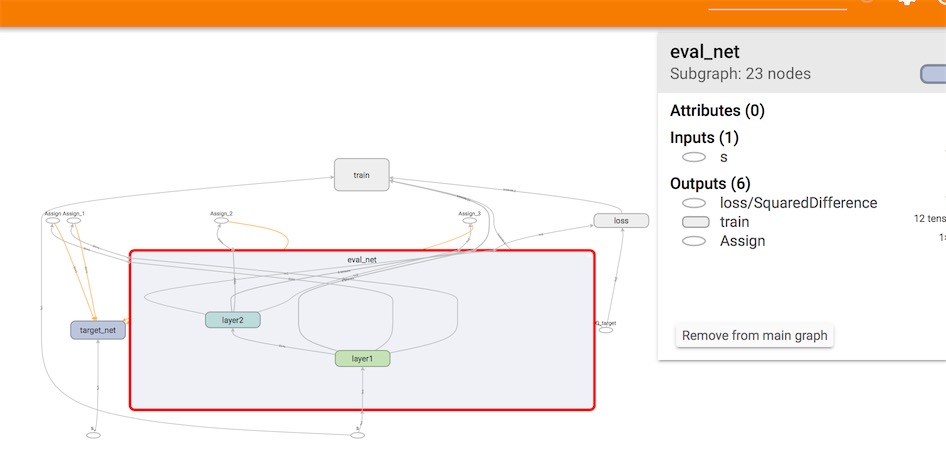
项目设置
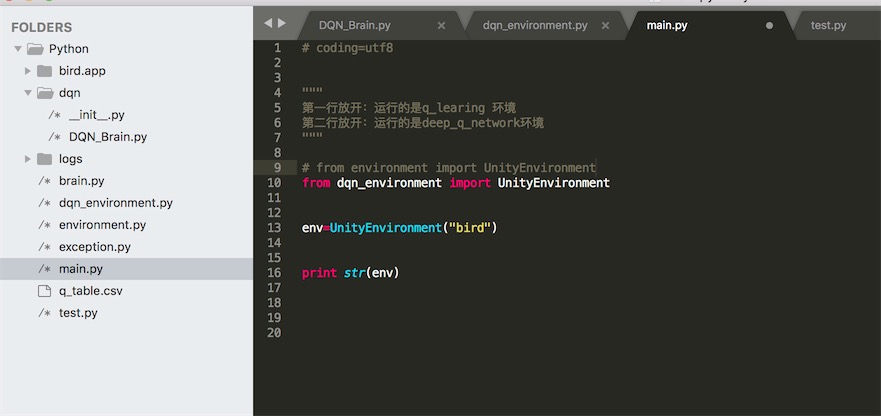
所有的代码都上传到github,需要联系的同学可以到github下载到本地练习。训练的时候你需要将Unity导出mac或者windows的安装包,注意安装包需导出到Python目录之下。Python的main.py需要做如下设置, from的模块选择的是dqn_environment,而不是environment:
如果你安装了jupyter notebook的话,在terminal,cd到python所在的目录,,然后输入:
jupyter notebook之后你可以在notebook里选择main.ipynb,进入主页:
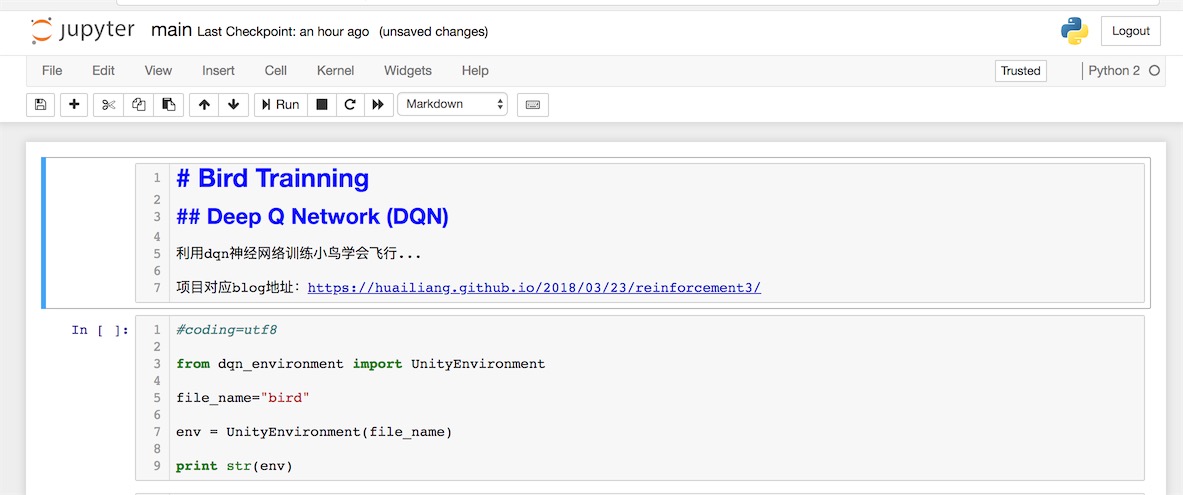
选择cell,Run就可以了。
eval_net用来训练模型,他的输入端是agent的状态值(state),输出的是得来的action对应的不同状态的数组,我们根据最大的q值选取相应的action
def choose_action(self, observation):
# print observation
observation = observation[np.newaxis]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)更新memory,在learn的过程中,我们每步我们都会在q_eval的memory储存信息,只是五步同步一次到q_target。实际运行的时候,在替换q_target之后,小鸟的智能明显提高了。
def _to_learn(self,j):
state_ = j["state_"]
state = j["state"]
action = j["action"]
rewd = j["rewd"]
if action == True:
action = 0 #"pad"
else:
action = 1 # "stay"
state=self.TransBrainState(state)
state_=self.TransBrainState(state_)
self.RL.store_transition(state,action,rewd,state_)
if self.step > 20 and self.step % 5 == 0 :
self.RL.learn()
self.step=self.step+1而在q_target神经网络的输入端,就是之前跟q_learning一样,包含如下信息:
- state 当前agent的状态
- state_ 下一步agent的状态
- reward 当前agent采取动作获的奖励
- action 当前agent采取的动作
我们使用的神经网络输出得到的实际值和预估值做平方差再求均值来计算损失函数。
# 说明:
tf.squared_difference(x,y,name=None)
# 功能:计算(x-y)(x-y)。
# 输入:x为张量,可以为`half`,`float32`, `float64`类型。# 计算损失函数
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
# 根据损失函数训练模型
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)我们可以在若干步之后,打印出loss的变化,实现如下:
def plot_cost(self):
import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
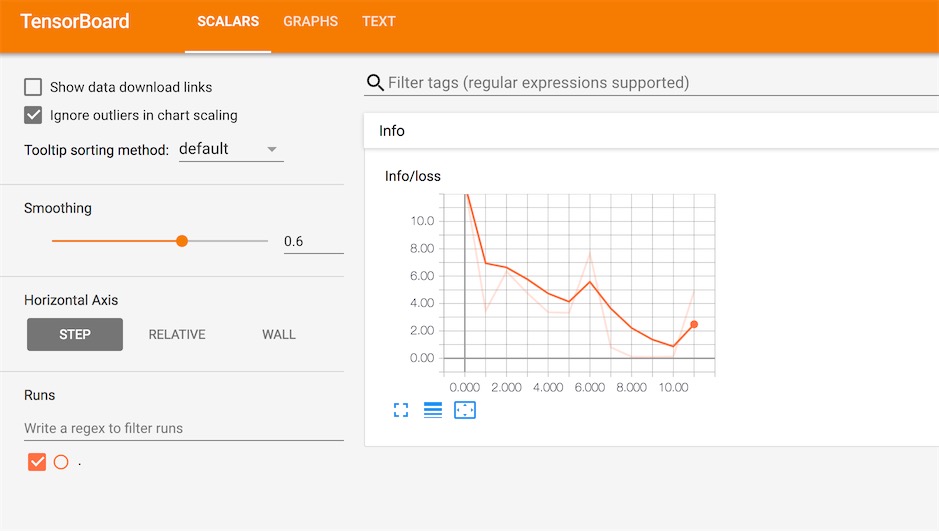
plt.show()结果
我们在tensorboard里观察数据的变化:
在terminal中cd 到对应的python目录,如果游戏已经运行了一段时间了,你可以看到本地多了一个logs的目录,这个本地生成对应的tensorboard的日志文件。
然后在终端界面输入:
tensorboard --logdir=logs/接着在浏览器里输入http://localhost:6006/ 就可以看到我们设置的变量和一些值得变化了:
如传入nn的一些参数可以在Text一栏可以观察到:
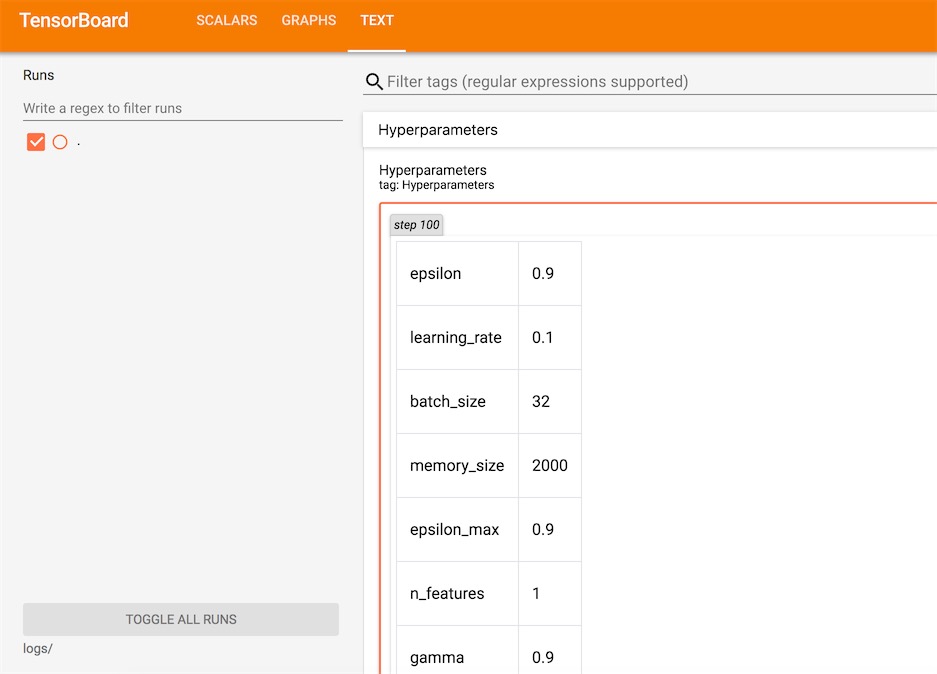
比如loss损失函数的变化: