Python扒取网络图片
就像一个黑客,随意扒取别人的资源为己用,想想就知道是一件多么酷的事儿,好像全世界的图片都是我的一样。
首先安装 BeautifulSoup。
beautifulsoup就是一个非常强大的工具,爬虫利器。
beautifulSoup “美味的汤,绿色的浓汤”
一个灵活又方便的网页解析库,处理高效,支持多种解析器。
利用它就不用编写正则表达式也能方便的实现网页信息的抓取。
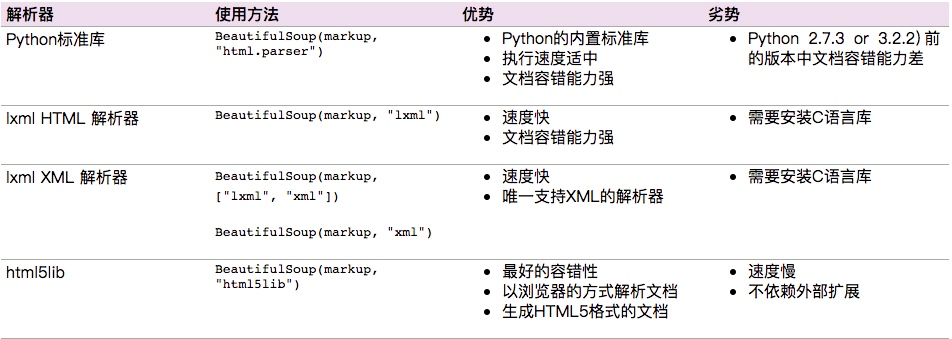
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
基本使用
标签选择器
在快速使用中我们添加如下代码:
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)通过这种soup.标签名 我们就可以获得这个标签的内容
这里有个问题需要注意,通过这种方式获取标签,如果文档中有多个这样的标签,返回的结果是第一个标签的内容,如上面我们通过soup.p获取p标签,而文档中有多个p标签,但是只返回了第一个p标签内容
-
获取名称
当我们通过soup.title.name的时候就可以获得该title标签的名称,即title
-
获取属性
print(soup.p.attrs['name'])
print(soup.p['name'])上面两种方式都可以获取p标签的name属性值
- 获取内容
print(soup.p.string)结果就可以获取第一个p标签的内容:
The Dormouse’s story
-
嵌套选择
我们直接可以通过下面嵌套的方式获取
print(soup.head.title.string)下面代码就是展示了利用 BeautifulSoup 扒取《国家地理》里的精美图片。我们可以设置最大的链接页面 max=5. 所有扒取的图片都存在跟nationalgeographic文件夹下。
# coding=utf-8
import os
import shutil
import requests
from bs4 import BeautifulSoup
from urllib import urlretrieve
max=5
dest = "./nationalgeographic/"
URL = "http://www.nationalgeographic.com.cn/animals/"
"""
扒取之前,先清理干净本地目录
"""
def clear():
if os.path.exists(dest):
shutil.rmtree(dest)
os.makedirs(dest)
"""
扒取下载图片
"""
def download(addr):
# 用global关键字来进行说明该变量是全局变量
global max
html = requests.get(addr).text
soup = BeautifulSoup(html,"lxml")
print soup.title
imgs=soup.find_all('img')
for img in imgs:
url=img['src']
file=url.split('/')[-1]
if url.startswith("http") and url.endswith("jpg"):
# urlretrieve(url,dest+file)
print url
r=requests.get(url,stream=True)
with open(dest+file,'wb') as f:
for chunk in r.iter_content(chunk_size=128):
f.write(chunk)
links=soup.find_all('a')
for link in links:
url=link['href']
# print url
if max >0 and url.startswith("http"):
download(url)
max=max-1
if __name__=="__main__":
clear()
download(URL)当我们使用urlretrieve下载图片的时候,发现有的图片下载不下来,使用requests.get(url,stream=True)可以比较完整的下载图片。

我们也可以多进程下载,这样可以加快下载速度。
代码实现类似这样:
import multiprocessing as mp
import threading as td
if __name__=="__main__":
for i,categorie in enumerate(categories):
clear(categorie)
logging.info(categorie)
#使用多进程
p=mp.Process(target=download,args=(categorie,))
p.start()
# p.join()在使用多进程的时候,在 for 循环中调用 jion 的时候,发现并不能触发多进程,实际上只有一个进程,另一个进程可能在等待。
还有就是 args是一定是()元组,当参数只有一个时候,记得加一个逗号。否则会包参数不对的 error.
在 Unix 平台山,当某个进程终结之后,该进程需要被父进程调用 wait,否则进程成为僵尸进程(Zombie). 所以有必要对每个 Process对象调用 join() 函数。
对于多进程的使用,我们强烈建议使用进程池,详情请参考这篇文章