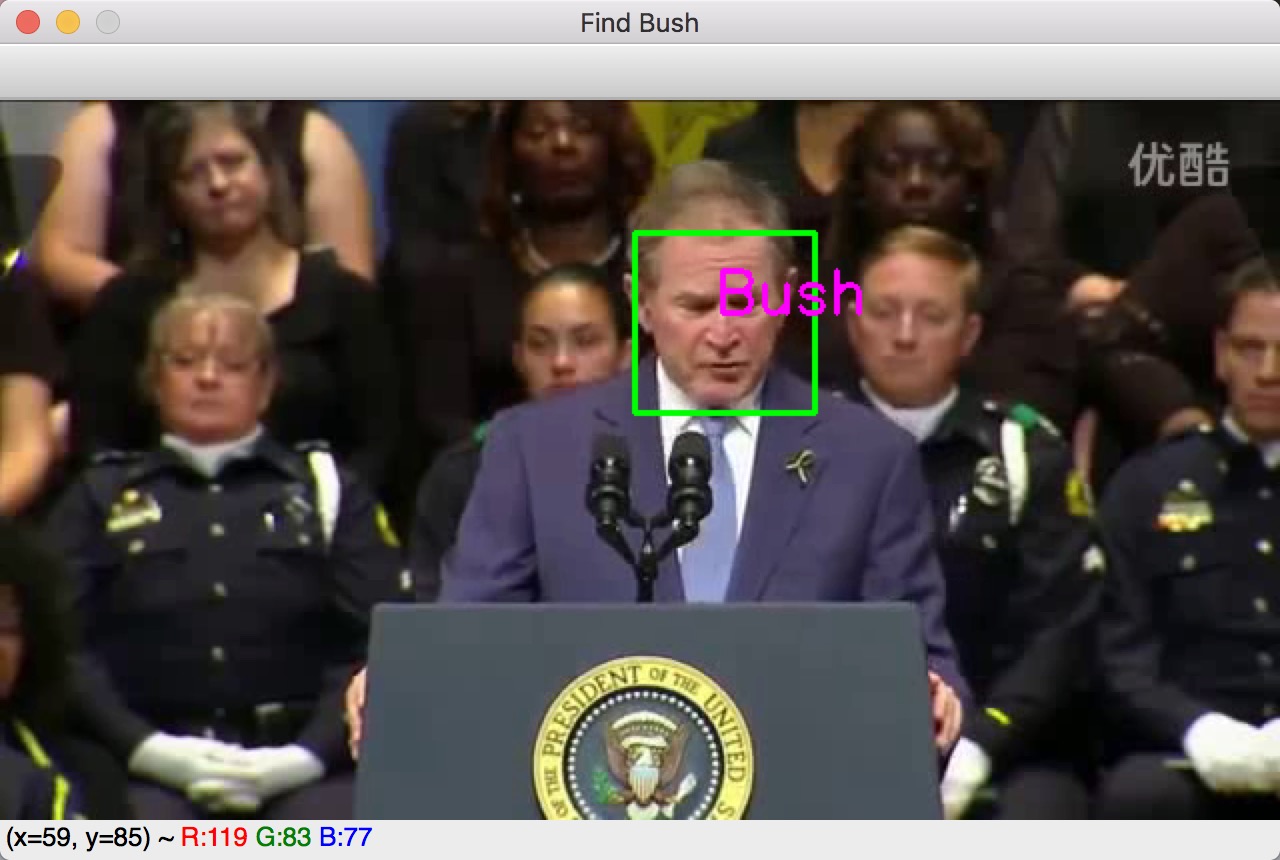
提取视频特征进行人脸识别
最近在麦子学院观看美国犹他州立大学的彭亮博士的《机器学习》的视频的系列。不错,就是跟我名字一字之差的彭亮,哈哈,世界巧合的事还真多。不过视频中他演示的《卧虎藏龙》的视频能够人脸识别周润发和章子怡,还真是激起了我的好奇心。不过好在现在互联网这么发达,什么东西只要想学,很多都能找到答案。
本文所用到的技术:
- Keras
- OpenCV
所有用到的技术都已上传到github, 读者可以根据自己的需求下载查阅。下载地址:
https://github.com/huailiang/video-face-recognition
Keras
如果说 Tensorflow 或者 Theano 神经网络方面的巨人. 那 Keras 就是站在巨人肩膀上的人. Keras 是一个兼容 Theano 和 Tensorflow 的神经网络高级包, 用他来组件一个神经网络更加快速, 几条语句就搞定了. 而且广泛的兼容性能使 Keras 在 Windows 和 MacOS 或者 Linux 上运行无阻碍.Keras 是建立在 Tensorflow 和 Theano 之上的更高级的神经网络模块, 所以它可以兼容 Windows, Linux 和 MacOS 系统。
鉴于keras极简的api,本次我们使用keras来搭建一个CNN网络模型,基于tensorflow。之前有一篇文章专门介绍CNN,不懂cnn的同学可以去看看。

OpenCV
OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
OpenCV的作用以前还是小看了,最近网易游戏在GDC发布的AirTest自动化测试的工具就是基于OpenCV. 有些人还用OpenCV实现了微信小游戏《跳一跳》自动刷分,虽说里面使用了很多随机的算法,但还是腾讯官方不知道使用了什么算法,居然能检测到作弊,然后给屏蔽掉评分。
本次利用openCV获取每一帧的所有脸部位置,然后截取脸部部分,传递给我们的CNN模型。cnn模型其实就是一个图片分类器,根据传递过来的图片,经过大量的训练,得到一个分类值(对应的标记label)。获得对应的标记之后,在通过OpenCV gui特性画一个方框,把名字标记在人脸处。

素材获取
因为需要训练需要大量的人脸素材,此次项目中所有使用的素材都是来源于UMASS(马萨诸塞大学)的一个对外的网站,这里你可以获取大量的预处理好的关于人脸素材,下载地址:http://vis-www.cs.umass.edu/lfw/。

由于每个人的对应的素材(图片张数)大小不一,我们这里截取了几位数量较多的名人图片的素材来当本地的训练集,比如说美国前任总统George_W_Bush,大概有四五百张。不过其他人好像还是少了点,比如说选择的Laura Bush( George_W_Bush‘s Wife), 犹如素材较少,出现了训练的时候表现很好,测试的时候出错的情况(过拟合-over fit).
而且我们专门写了一个python脚本用来删除那些图片数量较少的名人文件夹:
import os
import shutil
path="/Users/huailiang.peng/Downloads/lfw_funneled/"
alllist=os.listdir(path)
print len(alllist)
for item in alllist:
fpath=os.path.join(path,item)
print fpath
if os.path.isdir(fpath):
cnt = len(os.listdir(fpath))
print("{0} len: {1} ".format(str(item),str(cnt)))
if cnt<18:
shutil.rmtree(fpath)我们的视频素材是从youtube 随便找的一个关于Geoger Bush的演讲视频,貌似清晰度有点问题,不过也不影响我们训练的过程,谁关心呢。
关于训练集和测试集的构建, 我们从UMASS下载的图片集中最终选取了八位名人的图片做八分类,他们分别是:
- Bill_Clinton
- George_W_Bush
- Gerhard_Schroeder
- Junichiro_Koizumi
- Laura_Bush
- Serena_Williams
- Tony_Blair
- Winona_Ryder
项目按文件路径加载图片集,并根据文件夹的名称划给相应的标签, 代码实现如下:
images = []
labels = []
def read_path(path_name):
for dir_item in os.listdir(path_name):
#从初始路径开始叠加,合并成可识别的操作路径
full_path = os.path.abspath(os.path.join(path_name, dir_item))
if os.path.isdir(full_path): #如果是文件夹,继续递归调用
read_path(full_path)
else: #文件
if dir_item.endswith('.jpg'):
image = cv2.imread(full_path)
image = resize_image(image, IMAGE_SIZE, IMAGE_SIZE)
#放开这个代码,可以看到resize_image()函数的实际调用效果
#cv2.imwrite('1.jpg', image)
images.append(image)
# print path_name
if path_name.endswith("Bill_Clinton"):
labels.append(0)
elif path_name.endswith("George_W_Bush"):
labels.append(1)
elif path_name.endswith("Laura_Bush"):
labels.append(2)
elif path_name.endswith("Gerhard_Schroeder"):
labels.append(3)
elif path_name.endswith("Junichiro_Koizumi"):
labels.append(4)
elif path_name.endswith("Serena_Williams"):
labels.append(5)
elif path_name.endswith("Tony_Blair"):
labels.append(6)
else:
labels.append(7)
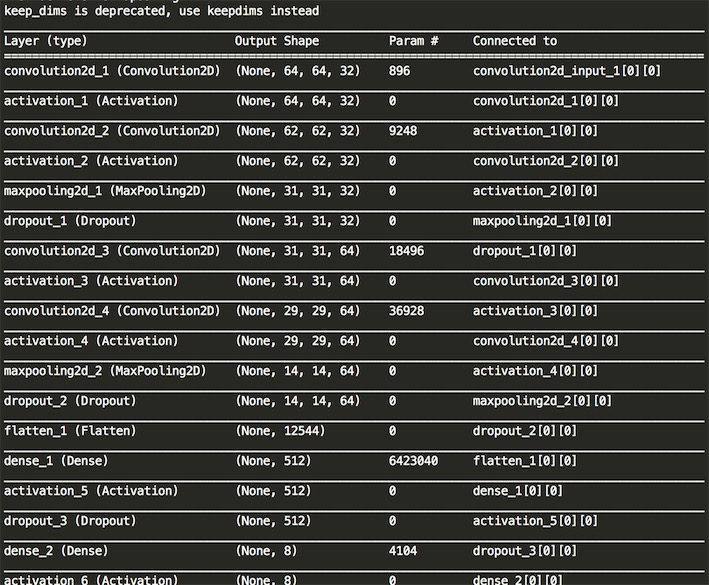
关于CNN网络的搭建,我们借助Keras的代码一共使用了十七层神经网络,统计一共使用了4次卷积,4次激励层,2次池化层,最后还包含全连接层和Dropout层、分类层。对应的代码如下:
def build_model(self, dataset, nb_classes=8):
# 构建一个空的网络模型,它是一个线性堆叠模型,各神经网络层会被顺序添加,专业名称为序贯模型或线性堆叠模型
self.model = Sequential()
# 以下代码将顺序添加CNN网络需要的各层,一个add就是一个网络层
self.model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape=dataset.input_shape)) # 1 2维卷积层
self.model.add(Activation('relu')) # 2 激活函数层
self.model.add(Convolution2D(32, 3, 3)) # 3 2维卷积层
self.model.add(Activation('relu')) # 4 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 5 池化层
self.model.add(Dropout(0.25)) # 6 Dropout层
self.model.add(Convolution2D(64, 3, 3, border_mode='same')) # 7 2维卷积层
self.model.add(Activation('relu')) # 8 激活函数层
self.model.add(Convolution2D(64, 3, 3)) # 9 2维卷积层
self.model.add(Activation('relu')) # 10 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 11 池化层
self.model.add(Dropout(0.25)) # 12 Dropout层
self.model.add(Flatten()) # 13 Flatten层
self.model.add(Dense(512)) # 14 Dense层,又被称作全连接层
self.model.add(Activation('relu')) # 15 激活函数层
self.model.add(Dropout(0.5)) # 16 Dropout层
self.model.add(Dense(nb_classes)) # 17 Dense层
self.model.add(Activation('softmax')) # 18 分类层,输出最终结果我们使用 model.summary() 可以明了的看清神经网络的组织方式:
Keras使用fit方法拟合模型,关于keras的API使用我们这里就不多介绍了,现在已经对应的中文网站出现了,学习起来应该是无压力的。对应到我们的代码就是:
model.fit(dataset.train_images,
dataset.train_labels,
batch_size = batch_size,
nb_epoch = nb_epoch,
validation_data = (dataset.valid_images, dataset.valid_labels),
shuffle = True)最终学习出来的准确率, 有点欠缺人意,哈哈,准确率只达到了96.4%,不过我想也够用了。

最后如果我们随即使用一张图片集的图片验证,基本上都是对的。但如果我们从Internet上找一张关于Laura Bush的照片,确实很容易就出错了,毕竟laura的训练图片实在是太少了。
我们还是使用openCv的方式提取图像,传递给模型,基本上bush是可以是别的,但也存在着误差。代码部分这里就不贴出来了,大家可以下载github工程去查看对应的face_predict_use_keras.py脚本。 在场的观众也可能被误认为是Bush,毕竟在训练的时候我们没有这些观众的图片,在经过CNN输出分类的时候就有可能随机是Bush了。可能计算机认为他们长得比较像吧。