游戏风格转换
如今人工智能大行其道, 其中在图像、影音处理中方法颇多。 本文介绍一种游戏中图像风格转换的例子,训练采用Tensorflow-GAN的方式,运行时在Unity引擎使用compute shader实现了跟tensorflow中一样的前向传播的网络来生成转换后的风格。对应Tensorflow环境中的Generator。 对应到github地址点击这里, 实现的效果如下图, 转换风格的图像我们通过一张RT渲染到右下角:

训练集
我们在python-tensorflow中实现了一种反向传播网络,我们使用Auto-Encoder替代GAN中Generator,用以生成风格化的图像, 而在Discriminator来鉴别图像。
训练中采用的训练集是微软的coco的dataset, 下载转换风格图片集.
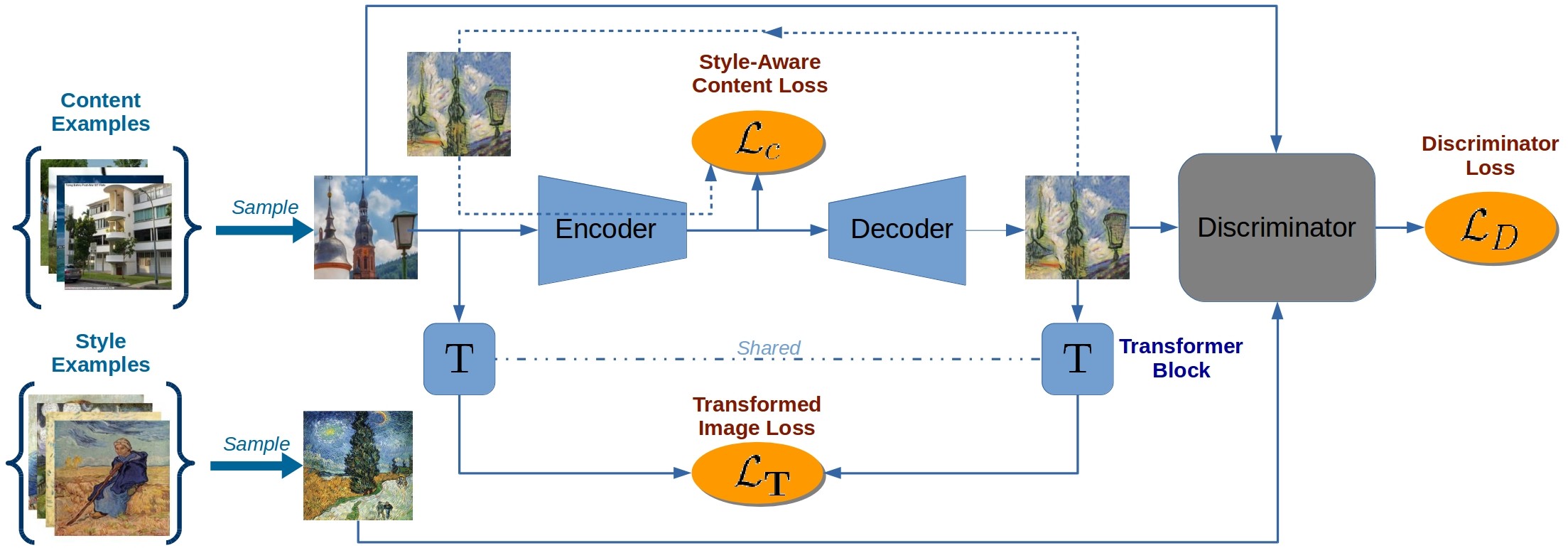
我们在训练Discriminator的时候, 评估损失函数,丢给Discriminator风格化的图片尽量大, coco训练集的图片因为是假的, 我们去使其输出的值尽量小, 通过gennerator的图片,也是假的,我们也使其值也越小。
在训练Genenrator评估其损失函数的时候, generator的图片丢给Discriminator,尽量和真实的风格图片尽量接近,因此我们使其输出的值也要越大。
这里定义content image的内容的损失,方法采用的如paper 均值池化提取特征后, 比较方差的差异。
定义style featur的损失, 方法采用把generator生成的图片和原始输入的style image分别带入encoder做绝对值的差。
# Image loss.
self.img_loss_photo = mse_criterion(
transformer_block(self.output_photo), transformer_block(self.input_photo))
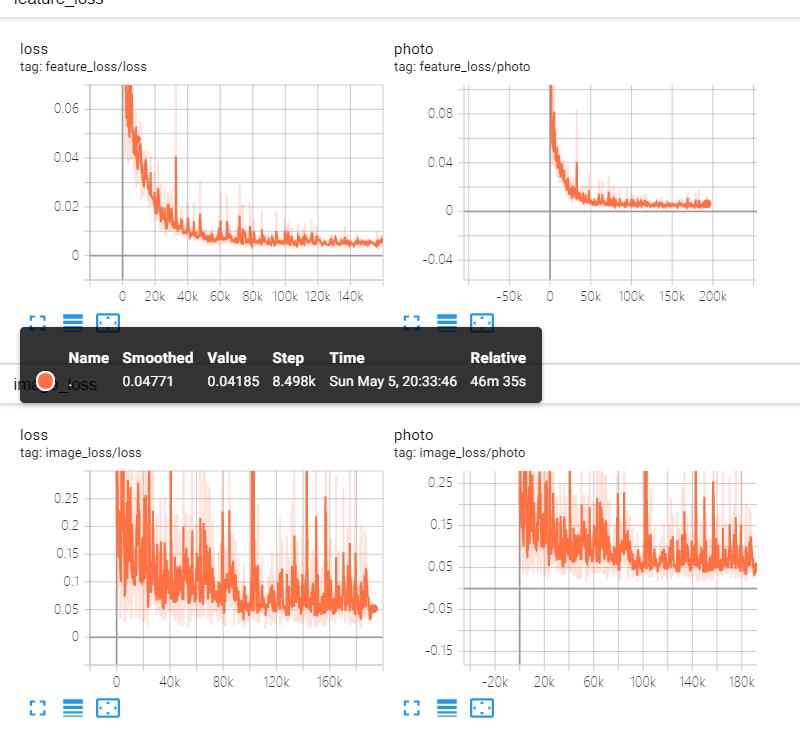
self.img_loss = self.img_loss_photo
# Features loss.
self.feature_loss_photo = abs_criterion(self.output_photo_features, self.input_photo_features)
self.feature_loss = self.feature_loss_photoTensorboard 里观察loss的变化:
运行时
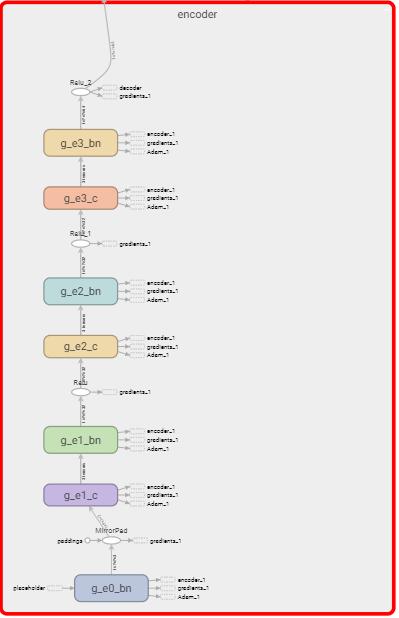
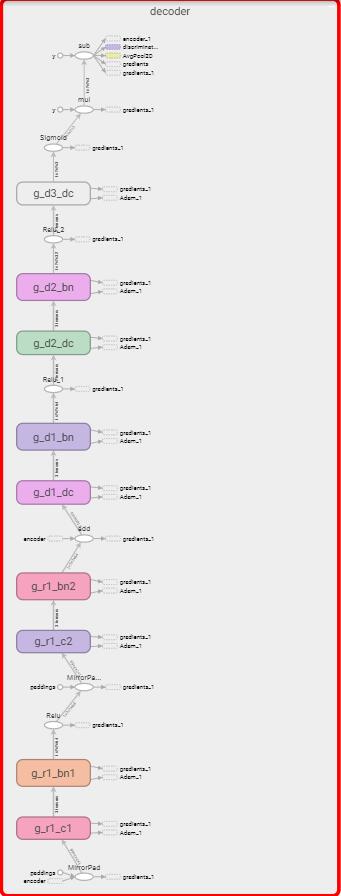
在unity中, 我们使用compute shader实现了一套跟TensorFlow中的相同的前向传播网络。 这里只是实现了Encoder和Decoder, 并没有实现Discriminator, 因为只有训练的时候用到了Discriminator.
在网络层中 Batch-normal由于为了求整体的均值和方差, 需要遍历当前层每个深度的layer,需要使用归纳算法-reduce, 使计算效率时间复杂度由n变成logn, 所以设计网络的时候尽量减少了类似的操作,在CompVis的设计网络中,decoder使用了九个残差模块, 为了性能我们这里减少到了一个。 参数规模也由大概48M减少到12M, 却实现了类似的效果。
由于受限于compute shader的语法, 我们在定义thread group时候, thread的大小不能超过1024,thread-z不能超过64, group的组成是vec3的格式, 而且需要是32或者64的倍数, 因此我们在设计网络的时候,每一个的layer尽量去靠近这些特性, 致使GPU发挥出最大的性能。 (CS5 group thread个数最多是1024, 而CS4最多支持到512,Apple的平台最多支持到CS4,这里需要注意下)。
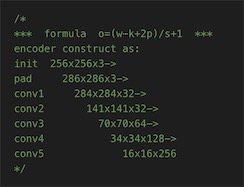
compute shader里网络的参数规模如下图所示:
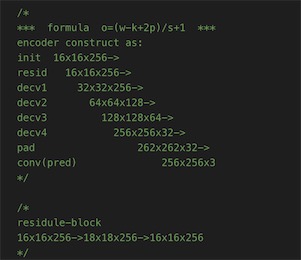
简化过后的,对应的tensorboard里的版本:
在设计的CNN网络层中, 卷积核大都是3x3的, 所以这里我们定义了一个Matrix3x3.cs在csharp中, 这样给StructureBuffer传递数据的时候,一次性传递过去。
数据导出
tensorflow 训练数据集有自己的序列化方式,大概是protobuf, google也提供了一套api, 去获取里面的张量Tensor。
通过训练集之后导出的checkpoint文件大小超过一个G,如果把这么庞大的参数文件导入到unity中所开销的内存空间是无法想象的。
通过遍历checkpoint发现所有的tensor发现, 每一层layer, 网络中的每个参数都对应了两个Adam对象,所以我们写了一套工具,导出数据的时候过滤掉Adam对象,使其大小减小到之前的1/3.
在上面提到,discriamtor只在训练的时候用到,而且其参数规模远超generator, 这里我们在导出的时候也需要对其过滤掉。
通过上面的操作我们导出的参数规模大概是48M,由于可以去掉预算复杂且效率不高的残差网络模块,参数规模进一步缩小到十几兆。 这还是我们采用float存储的格式, 如果对精度要求不高, 采用half的数据格式 5M-6M之间, 我觉得这个大小都手机平台还是可以接受的。
数据调试
为了清晰的看出Tensorflow Session里的每一层数据, 我们同时在python和unity环境中定义了printf 和 printh 函数, 分别用来输出二三维和一二维数据到控制台。 也可以检测python环境和unity环境运算结果是否具有一致性。
为了看出神经网络中的参数整体的相关性, 这里通过工具导出Auto-Encoder每一层里的数据(.bytes 二进制文件), 然后在unity导入数据。通过Unity-Editor工具,我们对数据HXW前两维的数据生成一张Texture上, 在生成数据之前,我们通过激励函数sigmod, 使全部数据normalized到取件[0,1]之间。 之后,在通过一个slider表示第三维度的数据,通过拖拽slider的进度, 就可以看到不同depth的数据整体相关情况了。
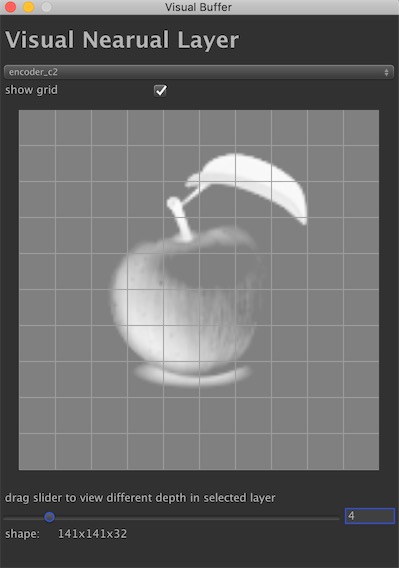
我们通过一张图片看到, ganerator前期encoder前期更多的学到的是形状信息, 后期decoder学到的更多的是风格相关的信息。
性能分析
- 参数规模:
在导出参数二进制文件到unity中的时候, 我们在python 控制台输出了参数规模大小约88M, 在过滤掉只在训练集里用到的参数, 导出的文件大概是9.7M。 在项目的fast分支, 我们删除了一些不重要的layer, 精简网络之后,参数规模占用23M, 过滤掉只在训练集里用到的参数, 导出的文件大小只有600K多一些了, 相比较于Tensorflow中Checkpoint文件中多达一个多G的参数规模,我们在运行时参数规模精简了1000多倍。(tensorflow checkpoint文件采用了protobuf格式的数据存储,我们这里纯是二进制, 因为protobuf虽然也是二进制, 但是会记一些tag之类的版本兼容相关的信息, 另外tensorflow还会存discriminator的信息,这块实现比较复杂,但只会出现在训练集里)。
- 帧率:
当我们使用完整的pix2pixHD去实现的时候, PC上大概能跑3FPS, MAC上大概还不到1FPS。 之后在fast分支, 我们去掉了一些不重要的网络层,PC上大概能跑到29FPS,在文章的效果图里可以看到对应的效果。
在手机上, 我们对模糊效果的处理,往往为了性能会控制采样点的数量,也就是卷积核的大小。当采样点超过9个的话, 性能相对来说就会有一定的下降。 如果按此来比对基于深度神经网络方式实现的风格转换的做法时,那么这里采样的点岂止9个,即使fast上的实现方式,每个像素的采样规模也是模糊处理的几十倍, 所以帧率低也是有一定道理的。 在fast分支处理的时候, 我们尽量删除了那些depth标记深的layer, 因为cnn的时候要对每一层累加, 归纳reduce算法对于GPU来说,因为要遍历全局,时间复杂度最快也是logn。