AR探索
程序通过OpenCV实现对Marker的识别和定位,然后通过OpenGL将虚拟物体叠加到摄像头图像下,实现增强现实。这里以参考《深入理解OpenCV》这本书第二章节的例子,实现基于标记的的虚拟现实实现。看到网上很多的例子都是基于固定渲染管线来画虚拟物体的, 而且很多地方都经不起推敲。 本例使用现代OpenGL实现的整个绘制过程。
固定标记识别
访问相机
增强现实应用必须包括视频捕获和AR可视化这两个主要过程。视频捕获阶段包括从设备接收视频帧,执行必要的色彩转换,并且将其发送给图像处理流程。对AR应用来讲,单帧处理的时间很关键,因此,帧的获取应尽可能高效。为了达到高性能,最好的办法是直接从摄像机读取帧。从iOS4开始支持这种方式。AVFoundation框架有现成的API函数来直接读取内存中的图像缓冲区。
AVCaptureDevice和AVCaptureVideoDataOutput允许用户配置、捕获以及指定未处理视频帧,这些帧都是32bpp BGRA格式(bpp是bit per pixel的缩写)。也可设置输出帧的分辨率。但这样做会影响整体性能,因为较大的帧会花费更多的处理时间并需要更大的内存空间。
通过AVFoundation API来获取高性能视频有一个好的选择。它提供了一个更快、更简洁的方法来直接从摄像机缓冲区中获取帧。但首先需了解下图关于iOS的视频获取流程:
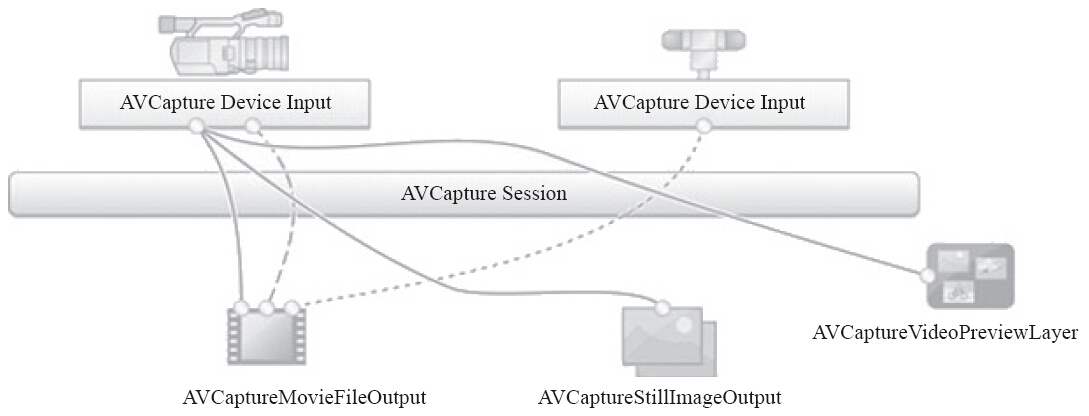
AVCaptureMovieFileOutput接口用于将视频写到文件中,AVCaptureStillImageOutput接口用于生成静态图像,AVCaptureVideoPreviewLayer接口用于在屏幕上进行视频预览。本项目将用到AVCaptureVideoDataOutput接口,因为它可直接访问视频数据。
AVCaptureVideoDataOutput *captureOutput = [[AVCaptureVideoDataOutput alloc] init];
captureOutput.alwaysDiscardsLateVideoFrames = YES;
// 在这里注册输出
[self.captureSession addOutput:captureOutput];
#pragma mark AVCaptureSession delegate
- (void)captureOutput:(AVCaptureOutput *)captureOutput didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer fromConnection:(AVCaptureConnection *)connection
{
CVImageBufferRef imageBuffer = CMSampleBufferGetImageBuffer(sampleBuffer);
CVPixelBufferLockBaseAddress(imageBuffer,0);
/*Get information about the image*/
uint8_t *baseAddress = (uint8_t *)CVPixelBufferGetBaseAddress(imageBuffer);
size_t width = CVPixelBufferGetWidth(imageBuffer);
size_t height = CVPixelBufferGetHeight(imageBuffer);
size_t stride = CVPixelBufferGetBytesPerRow(imageBuffer);
BGRAVideoFrame frame = {width, height, stride, baseAddress};
[delegate frameReady:frame]; //派发帧
/*We unlock the image buffer*/
CVPixelBufferUnlockBaseAddress(imageBuffer,0);
}
绘制背景
由于是AR项目, 所有背景输出的就是camera捕获的内容了。 这里获取到的frame都是上面代码传过来的BGRA格式的图像, 我们在OpenGL创建一个GL_TEXTURE_2D, 把frmae的内容绑定到对应的texture即可。对应的格式设置如下, 此时因为全屏输出, 也没有必要设置mipmap.
glGenTextures(1, &m_backgroundTextureId);
glBindTexture(GL_TEXTURE_2D, m_backgroundTextureId);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
// This is necessary for non-power-of-two textures
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
创建一个quad的mesh, 对应的uv区间是【0,1】。 在vert shdader里,直接输出到屏幕,也不需要多余的变换,例如投影之类的。如果输出的图像于现实是相反的,你可以在frag shader里uv采样的时候直接翻转下uv即可。
// vert shader
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec2 aTexCoords;
out vec2 TexCoords;
gl_Position = vec4(aPos, 1.0, 1.0);
// frag shader
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
#ifdef _FLIP_Y_
vec4 color = texture(texture1, vec2(TexCoords.x, 1.0 - TexCoords.y));
#end
FragColor = color;
相机姿势估计
关于什么是相机的内参和外参就不详细介绍了, 具体可以参考这篇文章。
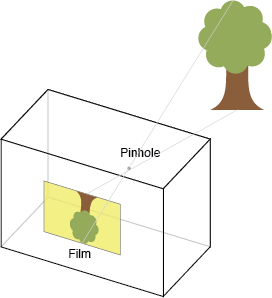
计算摄像机的位置,首先需要对摄像机进行标定,标定是确定摄像机内参矩阵K的过程,一般用棋盘进行标定,这已经是一个很成熟的方法了,在这就不细说了。得到相机的内参矩阵K后,就可以使用solvePnP方法求取摄像机关于某个Marker的位置(这里理解成相机的位置和旋转更确切些, 以虚拟物品当做世界坐标原点,即虚拟物品的模型空间等于世界空间,通过得来的转换矩阵变换到view空间)。摄像机成像使用小孔模型,如下:
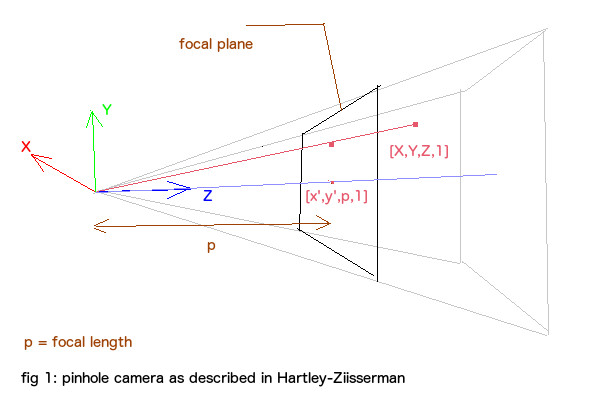
其中,X是空间某点的坐标(相对于世界坐标系),R和T是摄像机外参矩阵,用于将某点的世界坐标变换为摄像机坐标,K是摄像机内参,用于将摄像机坐标中的某点投影的像平面上,x即为投影后的像素坐标。
相机的内参K 表达式如下:
其中f_x代表x-axi方向上的焦距, f_y代表着y-axi方向上的矩阵, 一般来说f_x = f_y = f , 即相机的焦距,在iPhone或者iOS设备上,这个值大约等于640。 x_0和y_0有的地方也叫u0和v0,表示图像的半宽和半高。这里的参数主要用在投影过程中, 他们都是投影矩阵的参数,下面会有详细的介绍。
opencv的相机坐标系转换到opengl的相机坐标系
opencv的相机坐标系参考文章:相机模型与标定(二)–三大坐标系及关系
opengl的相机坐标系参考文章:OpenGL.坐标系统的介绍与坐标变换的实现
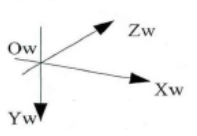
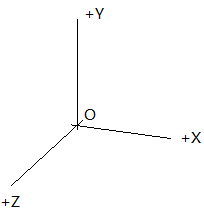
两个系统下的相机坐标系都是右手系的,x轴都是指向右,只是y轴和z轴反了。(上左图就是opencv的相机坐标系,上右图是opengl的)因此,只需要把物体在opencv的相机坐标系下的坐标绕x轴旋转180度,就可以转换为opengl的相机坐标系下的坐标了。
具体实现可以让相机外参左乘一个翻转矩阵:
获取使用一个3x3的矩阵同时作用于transform(vec3) 和旋转(mat3). 我看网上有类似的计算,也是对的。
在ksimek的博客里, 看到一个思路,并没有翻转y轴和z轴。 而是添加了一个到NDC的变换,可能也能实现同样的效果。 但是文章里很多公式都是错的,这里我也没有仔细推。耐心的读者可以认真地按照作者说的思路,详细推导一遍。
读者可以看到很多地方说是需要绕x轴旋转180, 也可以推导出上述的公式。 但原因绝不是因为view space到project space的变化的,也不是因为所谓的OpenGL为了进行Clipping,其投影矩阵需要将点投影到NDC空间中。 因为这些变化都体现在了投影矩阵里了, 投影矩阵会切换右手坐标系到左手坐标系,具体的推导过程参考这里。
现在再来考虑OpenGL投影椎体不对称的情况,这种情况下,PROJECTION矩阵的形式为:
其中c,d 如下:
关于l+r和b+t是怎么计算的,可以参考下图:
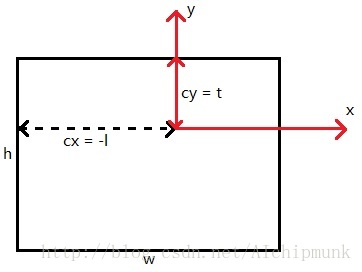
代码部分如下, 根据相机内参构建投影矩阵并建立opencv到opengl的y轴-z轴翻转矩阵(绕x轴旋转180度)
void InitialVR(float width, float height,const Matrix33& intrinsic)
{
proj = glm::mat4(0);
float fx = intrinsic.data[0], n= -0.01f, f = -100.0;
proj[0][0] = 2.0 * fx / width;
proj[1][1] = 2.0 * fx / height;
proj[2][2] = (f + n) / (n - f);
proj[2][3] = -1.0;
proj[3][2] = 2.0 * f * n / ( f - n);
reverse = glm::mat4(1);
reverse[1][1] = -1;
reverse[2][2] = -1;
}
根据MarkerDetector识别的camera外部参数, 传递给shader.
glm::mat4 view = transforms[i].getMat44(); //camera's position & rotation
view = reverse * view;
vrShader->use();
vrShader->setMat4("view", view);
vrShader->setMat4("proj", proj);
glBindVertexArray(vrVao);
glDrawArrays(DRAW_MODE, 0, 36);
glBindVertexArray(0);
shader里直接变换到屏幕上的图像就可以了, 在glsl里实现如下:
uniform mat4 view;
uniform mat4 proj;
out vec2 TexCoords;
void main()
{
vec3 pos = vec3(aPos.x * 0.3, aPos.y * 0.3, aPos.z * 0.3);
gl_Position = proj * view * vec4(pos, 1.0);
}
最后展示下在引擎里运行在ipad上的效果:
camera动态图像识别
前面使用了一个特制的maker(印有方块的标记)。 现实生活中,这种标记都是不存在的,这里通过算法对现实世界的图像进行特征提取,生成特有的标记, 从而实现了从基于标记到AR转移到无标记的AR。可采用无标记AR的几个例子: 杂志封面,公司标志、玩具等。无标记AR计算量很大, 所以移动设备往往不能确保流畅的FPS。
在实现过程主要分为两步:
1. 使用关联图片创建一个marker
2. 和新图片匹配
生成marker
首先,使用选择手机相册里的图片,根据UIImagePickerController的回调内容,把数据传递给OpenGL. Opengl在screen右下角画出选择的image, 就像之前在glfw里显示shadowmap一样。
获取UIImagePickerController的回调, 你需要在代码注册protocol,类似这样:
@interface AlbumSource() <UINavigationControllerDelegate, UIImagePickerControllerDelegate>
{}
-(void)imagePickerControllerDidCancel:(UIImagePickerController *)picker;
-(void)imagePickerController:(UIImagePickerController *)picker
didFinishPickingMediaWithInfo:(NSDictionary<NSString *,id> *)info;
@end使用OpenGL画选择的图片就更简单了。 render 一张texture, 绑定一张mesh, mesh的uv放在右下角:
// generate a texture
glGenTextures(1, &texID);
glBindTexture(GL_TEXTURE_2D, texID);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
// render the texture
glBindTexture(GL_TEXTURE_2D, texID);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, x, y, 0, GL_RGBA, GL_UNSIGNED_BYTE, data);
同时传递给cv, 生成关键点和descriptor, 后面使用匹配算法会用到这两个变量:
cv::Mat image(x, y, CV_8UC4, data);
cornerDetector = cv::ORB::create(750);
cornerDetector->detectAndCompute(image,
cv::noArray(),
referenceKeypoints,
referenceDescriptors);
图像的特征点可以简单的理解为图像中比较显著显著的点,如轮廓点,较暗区域中的亮点,较亮区域中的暗点等。ORB采用FAST(features from accelerated segment test)算法来检测特征点。这个定义基于特征点周围的图像灰度值,检测候选特征点周围一圈的像素值,如果候选点周围领域内有足够多的像素点与该候选点的灰度值差别够大,则认为该候选点为一个特征点。
为了获得更快的结果,还采用了额外的加速办法。如果测试了候选点周围每隔90度角的4个点,应该至少有3个和候选点的灰度值差足够大,否则则不用再计算其他点,直接认为该候选点不是特征点。候选点周围的圆的选取半径是一个很重要的参数,这里为了简单高效,采用半径为3,共有16个周边像素需要比较。为了提高比较的效率,通常只使用N个周边像素来比较,也就是大家经常说的FAST-N.

BRIEF特征描述子
得到特征点后我们需要以某种方式描述这些特征点的属性。这些属性的输出我们称之为该特征点的描述子(Feature DescritorS).ORB采用BRIEF算法来计算一个特征点的描述子。
BRIEF算法的核心思想是在关键点P的周围以一定模式选取N个点对,把这N个点对的比较结果组合起来作为描述子。
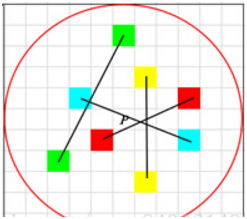
步骤:
1.以关键点P为圆心,以d为半径做圆O。
2.在圆O内某一模式选取N个点对。这里为方便说明,N=4,实际应用中N可以取512.
假设当前选取的4个点对如上图所示分别标记为:
算法步骤如下:
1.以关键点P为圆心,以d为半径做圆O。
2.在圆O内某一模式选取N个点对。这里为方便说明,N=4,实际应用中N可以取512. 假设当前选取的4个点对如上图所示分别标记为:
3.定义操作
其中 表示点A的灰度
4.分别对已选取的点对进行T操作,将得到的结果进行组合。 假如:
则最终的描述子为:1011
理想的特征点描述子应该具备的属性:
在现实生活中,我们从不同的距离,不同的方向、角度,不同的光照条件下观察一个物体时,物体的大小,形状,明暗都会有所不同。但我们的大脑依然可以判断它是同一件物体。理想的特征描述子应该具备这些性质。即,在大小、方向、明暗不同的图像中,同一特征点应具有足够相似的描述子,称之为描述子的可复现性。
当以某种理想的方式分别计算描述子时,应该得出同样的结果。即描述子应该对光照(亮度)不敏感,具备尺度一致性(大小),旋转一致性(角度)等。
ORB并没有解决尺度一致性问题,在OpenCV的ORB实现中采用了图像金字塔来改善这方面的性能。ORB主要解决BRIEF描述子不具备旋转不变性的问题。
在当前关键点P周围以一定模式选取N个点对,组合这N个点对的T操作的结果就为最终的描述子。当我们选取点对的时候,是以当前关键点为原点,以水平方向为X轴,以垂直方向为Y轴建立坐标系。当图片发生旋转时,坐标系不变,同样的取点模式取出来的点却不一样,计算得到的描述子也不一样,这是不符合我们要求的。因此我们需要重新建立坐标系,使新的坐标系可以跟随图片的旋转而旋转。这样我们以相同的取点模式取出来的点将具有一致性。
ORB在计算BRIEF描述子时建立的坐标系是以关键点为圆心,以关键点和取点区域的形心的连线为X轴建立2维坐标系。
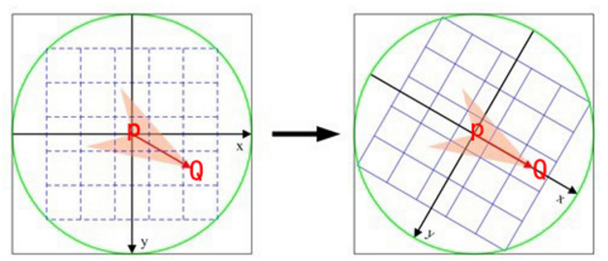
我们知道圆心是固定的而且随着物体的旋转而旋转。当我们以PQ作为坐标轴时,在不同的旋转角度下,我们以同一取点模式取出来的点是一致的。这就解决了旋转一致性的问题。
匹配图片
利用BRIEF特征进行配准
汉明距离:
汉明距离是以理查德•卫斯里•汉明的名字命名的。在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:
1011101 与 1001001 之间的汉明距离是 2。
2143896 与 2233796 之间的汉明距离是 3。
“toned” 与 “roses” 之间的汉明距离是 3。
给予两个任何的字码,10001001和10110001,即可决定有多少个相对位是不一样的。在此例中,有三个位不同。要决定有多少个位不同,只需将xor运算加诸于两个字码就可以,并在结果中计算有多个为1的位。例如:
10001001
Xor 10110001
00111000
两个字码中不同位值的数目称为汉明距离(Hamming distance) 。
特征点的匹配
ORB算法最大的特点就是计算速度快 。 这首先得益于使用FAST检测特征点,FAST的检测速度正如它的名字一样是出了名的快。再次是使用BRIEF算法计算描述子,该描述子特有的2进制串的表现形式不仅节约了存储空间,而且大大缩短了匹配的时间。
例如特征点A、B的描述子如下。
A:10101011
B:10101010
我们设定一个阈值,比如80%。当A和B的描述子的相似度大于90%时,我们判断A,B是相同的特征点,即这2个点匹配成功。在这个例子中A,B只有最后一位不同,相似度为87.5%,大于80%。则A和B是匹配的。
我们将A和B进行异或操作就可以轻松计算出A和B的相似度。而异或操作可以借组硬件完成,具有很高的效率,加快了匹配的速度。
#define NN_MATCH_RATIO 0.8f
#define MIN_INLIER_COUNT 32
matcher = cv::DescriptorMatcher::create("BruteForce-Hamming");
int matchcnt = 0;
std::vector<std::vector<cv::DMatch>> descriptorMatches;
matcher->knnMatch(referenceDescriptors, descriptor, descriptorMatches, 2);
for (unsigned i = 0; i < descriptorMatches.size(); i++)
{
if (descriptorMatches[i][0].distance <
NN_MATCH_RATIO * descriptorMatches[i][1].distance) matchcnt++;
}
if (matchcnt >= MIN_INLIER_COUNT) {
state->setText(" key points matched "+std::to_string(matchcnt));
captrue = true;
}
上述代码设定的阈值即80%, 当匹配的特征点个数超过32个的时候, 我们即认为匹配到了之前在相册选中的图片。在引擎里点击pick按钮会选择一张相册里的图,然后不断匹配camera的图像,知道检测到跟旋转的图片匹配的画面,画面定格。再次点击pick,会重新匹配新选组的图片。
运行效果如下:

参考:
[1] Camera Intrinsic & Extrinsic矩阵
[2] OpenGL Projection Matrix
[3] iOS内置的api 获取camera内置参数
[4] OpenGL与OpenCV实现增强现实
[5] OpenGL坐标系统
[6] Calibrated Cameras in OpenGL without glFrustum
[7] KNN 邻近算法
[8] Image Match
[9] iOS内置的api 获取camera内置参数
[10] OpenCV中ORB特征提取与匹配
[11] OpenCV中ORB的API解释
[12] 百科中关于 汉明距离的介绍