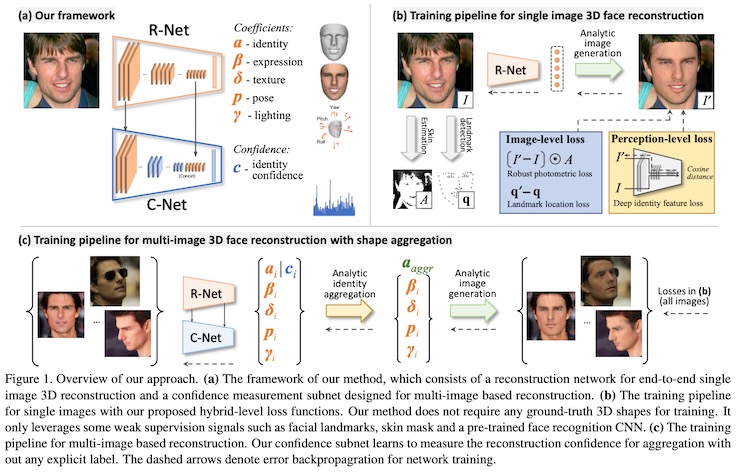
3D人脸重建
人脸重建是计算机视觉比较热门的一个方向,3d人脸相关应用也是近年来短视频领域的新玩法。不管是Facebook收购的MSQRD,还是Apple研发的Animoji,底层技术都与三维人脸重建有关。最近看到微软亚研院一篇关于重建人脸的paper: Accurate 3D Face Reconstruction with Weakly-Supervised Learning: From Single(CVPR 2019 最佳论文奖), 不仅支持面部网格的重建, 还能支持对表情、纹理贴图、Env光照的的重建, 还第一次感到AI的创作能力。
3DMM
1999 年,瑞士巴塞尔大学的科学家Blanz 和Vetter 提出了一种十分具有创新性的方法:三维形变模型(3DMM) 。三维形变模型建立在三维人脸数据库的基础上,以人脸形状和人脸纹理统计为约束,同时考虑到了人脸的姿态和光照因素的影响,因而生成的三维人脸模型精度高。
3DMM模型数据库人脸数据对象的线性组合,在上面3D人脸表示基础上,假设我们建立3D变形的人脸模型由m个人脸模型组成,其中每一个人脸模型都包含相应的 $S_i$, $ T_i $ 两种向量,这样在表示新的3D人脸模型时,我们就可以用以下的方式:
其中 $\overline{S}$ 表示平均脸部形状模型,$s_i$表示shape的PCA部分(特征向量),$\alpha_i$ 表示对应系数(特征值);纹理模型同理,至于为什么这么处理, 参见下面的PCA部。 像这样,一张新的人脸模型就可以由已有的脸部模型线性组合。也就是说,我们可以通过改变系数,在已有人脸基础上生成不同人脸。

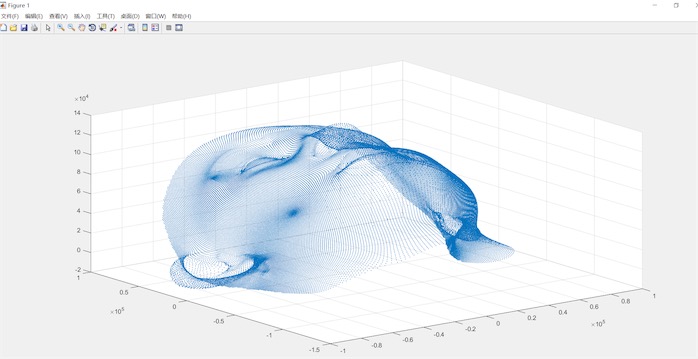
BFM数据集中在matlab中显示的平均人脸 $\overline{S}$ 如下图显示:
3DMM求解过程
基于3DMM求解三维人脸需要解决的问题就是形状,纹理等系数的估计,具体就是如何将2D人脸拟合到3D模型上,被称为Model Fitting,这是一个病态问题。经典的方法是1999年的文章“A Morphable Model For The Synthesis Of 3D Faces”,其传统的求解思路被称为analysis-by-Synthesis;
(a) 初始化一个3维的模型,需要初始化内部参数α,β,以及外部渲染参数,包括相机的位置,图像平面的旋转角度,直射光和环境光的各个分量,图像对比度等共20多维,有了这些参数之后就可以唯一确定一个3D模型到2D图像的投影。
(b) 在初始参数的控制下,经过3D至2D的投影,即可由一个3D模型得到2维图像,然后计算与输入图像的误差。再以误差反向传播调整相关系数,调整3D模型,不断进行迭代。每次参与计算的是一个三角晶格,如果人脸被遮挡,则该部分不参与损失计算。
(c) 具体迭代时采用由粗到精的方式,初始的时候使用低分辨率的图像,只优化第一个主成分的系数,后面再逐步增加主成分。在后续一些迭代步骤中固定外部参数,对人脸的各个部位分别优化。
对于只需要获取人脸形状模型的应用来说,很多方法都会使用2D人脸关键点来估计出形状系数,具有更小的计算量,迭代也更加简单,另外还会增加一个正则项,所以一个典型的优化目标是如下:
对于Model fitting问题来说,除了模型本身的有效性,还有很多难点。
(1) 该问题是一个病态问题,本身并没有全局解,容易陷入不好的局部解。
(2) 人脸的背景干扰以及遮挡会影响精度,而且误差函数本身不连续。
(3) 对初始条件敏感,比如基于关键点进行优化时,如果关键点精度较差,重建的模型精度也会受到很大影响。
PCA
PCA, 中文名字:主成分分析。 旨在利用降维的思想,把多指标转化为少数几个综合指标。PCA 经常用于减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。3DMM中将采集的人脸数据通过PCA降维到199个特征, 微软的论文进一步保留到80个特征。
PCA 处理流程:
(1) 第一步计算矩阵 X 的样本的协方差矩阵 S(此为不标准PCA,标准PCA计算相关系数矩阵C):
(2) 第二步计算协方差矩阵S(或C)的特征向量 e1,e2,…,eN和特征值 , t = 1,2,…,N ;
(3)第三步投影数据到特征向量张成的空间之中。利用公式$newBV_{i,p} = \sum^{n}{k=1} {e_i BV{i,k}}$,其中BV值是原样本中对应维度的值。
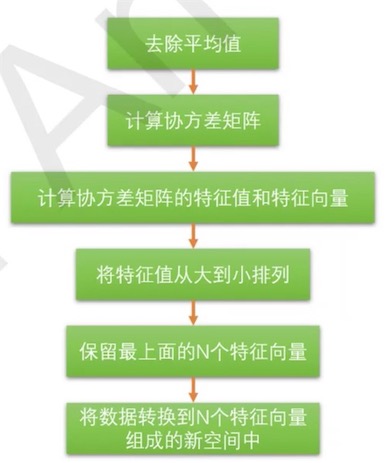
PCA 的目标是寻找r(r<n)个新变量,使它们反映事物的主要特征,压缩原有数据矩阵的规模,将特征向量的维数降低,挑选出最少的维数来概括最重要特征。每个新变量是原有变量的线性组合,体现原有变量的综合效果,具有一定的实际含义。这 r 个新变量称为“主成分”,它们可以在很大程度上反映原来 n 个变量的影响,并且这些新变量是互不相关的,也是正交的。通过主成分分析,压缩数据空间,将多元数据的特征在低维空间里直观地表示出来。
def PCA(datamat, top):
# 对所有样本进行中心化(所有样本属性减去属性的平均值)
meanVals = np.mean(datamat, axis=0)
meanRemoved = datamat - meanVals
# 计算样本的协方差矩阵 XXT
covmat = np.cov(meanRemoved, rowvar=0)
# 对协方差矩阵做特征值分解,求得其特征值和特征向量,
# 并将特征值从大到小排序,筛选出前top个
eigVals, eigVects = np.linalg.eig(np.mat(covmat))
print(eigVals)
eigValInd = np.argsort(eigVals)
# 取前top大的特征值的索引
eigValInd = eigValInd[: -(top + 1) : -1]
# 取前top大的特征值所对应的特征向量
redEigVects = eigVects[:, eigValInd]
# 将数据转换到新的低维空间中
# 降维之后的数据
lowDDataMat = meanRemoved * redEigVects
# 重构数据,可在原数据维度下进行对比查看
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return reconMat, lowDDataMat, redEigVects
如果对PCA还是没有直观的了解,可以参见b站视频菊安酱的机器学习 降维算法之PCA&SVD, 视频中通过理论结合代码(python, sck-learn)讲解的很详细。
单帧人脸重建
给定一张RGB图片$I$,作者使用R-Net回归参数向量$\chi$,根据得到的人脸模型可以渲染得到新的图片$I’$,训练时不需要任何真实标签,而是根据$I’$来计算损失。
Image-Level Losses
1. Robust Photometric Loss
原始图片 $I$ 和重建后的图片 $I’$ 之间的像素差异作为损失是直观明了的方法,本文基于此提出了一种鲁棒的、皮肤感知的图像损失:
其中 $I$ 表示像素索引,$M$ 是投影的人脸区域,$ \parallel \cdot \parallel $表示 $l_2$距离,$A$是一个基于皮肤颜色的attention mask。
Mask Attention 为了使网络对人脸遮挡和其他面部变化如胡须或浓妆等情况更加鲁棒,作者在皮肤颜色数据集上训练了一个简单的基于高斯混合模型的贝叶斯分类器,对每个像素$i$预测一个皮肤颜色概率$P_i$,这样
作者发现这个简单的皮肤感知的损失函数在实际中非常奏效,相比直接的图像损失效果提升显著,如下图所示。

2. Landmark Loss
作者在训练中还使用了人脸的2D关键点作为弱监督,使用SOTA的3D人脸对齐方法检测训练集中人脸的68个关键点${q_n}$,在训练过程中,将重建的人脸的3D关键点投影到图像空间得到${q_n’}$,并计算两者的距离作为损失函数
这里$\omega_n$是特征点权重,作者经过试验发现当嘴内部和鼻子处的点权重设为20,其他权重设为1时效果较好。
Perception-Level Loss
虽然使用低层次的图像信息作为损失函数也能取得不错的结果,但作者发现只使用这类损失对于基于CNN的3D人脸重建容易陷入局部最优解,为了解决这个问题,作者提出了一种感知层次的损失来进一步指导训练过程,即借助来自一个预训练的人脸识别网络的信号作为弱监督,计算源图和重建图片之间的人脸特征距离:
这里$f(\cdot)$表示深度特征编码,$<\cdot,\cdot>$表示内积。作者使用FaceNet网络作为人脸特征提取器,并在从网络爬取的包含5万个体的300万张图片的数据集中训练了该网络。下图展示了使用感知损失的效果提升。

Regularization
为了防止人脸形状和纹理退化,作者使用3DMM系数的正则项
其中权重$\omega_\alpha=1.0$, $\omega_\beta=0.8$,$\omega_\sigma=1.7e-3$。
由于2009 Basel Face Model的人脸纹理包含baked-in shading (e.g., ambient occlusion),为了倾向常量的皮肤反射率,作者增加了一个惩罚纹理图方差的正则项:
其中$R$是预定义的包含脸颊、鼻子和前额的皮肤区域。
多帧人脸的重建
除了从单张人脸图片重建人脸,如何从一个人的多张脸部图片,去重建一个更加精确的人脸模型也是一个很有意义的问题。不同的图片可能采集自不同的姿态、光照等,能够互相提供补充信息,这样重建出来的人脸对于遮挡、不佳的光照等情况更加鲁棒。
使用深度学习网络作用于任意张图片并不是一个简单的事情,在本文中,作者从单张图片人脸重建的结果学习一个置信度(反映重建质量),并使用这个置信度收集人脸形状信息。具体来说,作者针对人脸形状参数$\alpha\in \Bbb{R}^{80}$生成一个反映置信度的向量 $c\in \Bbb{R}^{80}$ 。
假设 $\zeta={ I_j | j=1,….,M }$ 表示一个人的照片集,$\chi_j=(\alpha^j, \beta^j, \sigma^j, p^j, \gamma^j)$表示R-Net从图片$j$得到的系数向量,$c^j$表示$\alpha^j$的置信度向量,则最终的人脸形状参数为
其中$\odot$和$\oslash$分别表示哈达玛积和商(Hadamard product and division)。
Confidence-Net Structure
作者提出C-Net来预测置信度$c$,由于R-Net能够预测诸如人脸姿态、光照等高阶信息,很自然地想到将其特征图运用到C-Net中来,作者同时使用了R-Net的浅层和深层特征,如前图所示,具体网络细节参考文章.
损失函数
为了在图片集中训练C-Net,首先从图片 ${I^j}$ 得到人脸系数 , 其中
,然后生成重建图片${I^{j’}}$,则损失函数定义为
$L(\cdot{})$是前面单张图片人脸重建中定义的损失函数。
实现细节
R-Net 的训练集来自CelebA, 300W-LP, I-JBA, LFW和LS3D数据集,并对其做了删选以得到平衡的人脸姿态和种族分布,最终用于训练的有大约26万张图片。然后再对图片进行对齐。网络的输入大小为224x224,使用ImageNet预训练的权重作为初始,优化器为Adam,batch size是5,初始学习率为1e-4,一共进行了50万次迭代。
C-Net 的训练集来自300W-LP, Multi-PIE和部分人脸识别数据集,对于300W-LP和Multi-PIE数据集,作者为每个人挑选了5张人脸角度分布均匀的图片,对于人脸识别数据集,对每个人随机挑选了5张图片,总的训练集包含大约1万个个体的5万张图片。作者固定住R-Net的权重,随机初始化C-Net的权重(除了最后一个全连接层初始化为0),优化器为Adam,batch size同样为5,初始学习率为2e-5,一共进行1万次迭代。
参考
- 3D人脸重建, csdn
- Accurate 3D Face Reconstruction, bliliblilli
- Accurate 3D Face Reconstruction tf, github
- A Morphable Model For The Synthesis Of 3D Faces, 3DMM
- 主成分分析技术, 百度百科
- 降维算法之PCA&SVD
- CVPR 2019 基于弱监督学习的精确3D人脸重建, 知乎
- 3D人脸处理工具Face3d, GitHub
- PCA(特征降维)的特征值,特征向量
- 3D Basel Face Model, BFM数据集
- BFM使用 - 获取平均脸模型的68个特征点坐标
- Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning
- Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion