光线追踪-降噪与硬件加速
图像去噪是非常基础也是非常必要的研究,去噪常常在更高级的图像处理之前进行,是图像处理的基础。可惜的是,目前去噪算法并没有很好的解决方案,实际应用中,更多的是在效果和运算复杂度之间求得一个平衡。

噪声模型
图像中噪声的来源有许多种,这些噪声来源于图像采集、传输、压缩等各个方面。噪声的种类也各不相同,比如椒盐噪声,高斯噪声等,针对不同的噪声有不同的处理算法。
对于输入的带有噪声的图像v(x),其加性噪声可以用一个方程来表示:
其中u(x)是原来没有噪声的图像。x是像素集合,η(x)是加项噪声项,代表噪声带来的影响。Ω是像素的集合,也就是整幅图像。从这个公式可以看出,噪声是直接叠加在原始图像上的,这个噪声可以是椒盐噪声、高斯噪声。理论上来说,如果能够精确地获得噪声,用输入图像减去噪声就可以恢复出原始图像。但现实往往很骨感,除非明确地知道噪声生成的方式,否则噪声很难单独求出来。
工程上,图像中的噪声常常用高斯噪声$N(μ,σ^2)$来近似表示,其中$μ=0,σ^2$是噪声的方差,$σ^2$越大,噪声越大。一个有效的去除高斯噪声的方式是图像求平均,对N幅相同的图像求平均的结果将使得高斯噪声的方差降低到原来的N分之一,现在效果比较好的去噪算法都是基于这一思想来进行算法设计。
除了高斯噪音,还有poisson噪声, 蒙特卡洛噪音。 光线渲染在路径追踪的时候,往往由于蒙特卡洛采样过少,则会导致的噪点。
为什么光线追踪会出现噪点
因为光线追踪,确切地说是路径追踪(Path Tracing)本质上是在解渲染方程,一个积分方程。
使用蒙特卡洛采样, 将上面积分式转换为离散的表达式:
当然,引入这个方法,如果采样数量不够多,会造成光照贡献量与实际值偏差依然会很大,形成噪点(即上式中N比较小)。随着采样数量的增加,局部估算越来越接近实际光照积分,噪点逐渐消失(下图)。

从左到右分别对应的每个象素采样为1、16、256、4096、65536
峰值信噪比
PSNR是Peak Signal to Noise Ratio的缩写,即峰值信噪比,是一种评价图像的客观标准,它具有局限性,一般是用于最大值信号和背景噪音之间的一个工程项目。
psnr一般是用于最大值信号和背景噪音之间的一个工程项目。通常在经过影像压缩之后,输出的影像都会在某种程度与原始影像不同。为了衡量经过处理后的影像品质,我们通常会参考PSNR值来衡量某个处理程序能否令人满意。它是原图像与被处理图像之间的均方误差相对于$(2^n-1)^2$的对数值(信号最大值的平方,n是每个采样值的比特数),它的单位是dB。
给定一个大小为 m×n 的干净图像 I 和噪声图像 K,均方误差 (MSE) 定义为:
数学公式如下:
一般地,针对 uint8 数据,最大像素值为 255,;针对浮点型数据,最大像素值为 1。n为每像素的比特数,一般取8,即像素灰阶数为256. PSNR的单位是dB,数值越大表示失真越小。
上面是针对灰度图像的计算方法,如果是彩色图像,通常有三种方法来计算
- 分别计算 RGB 三个通道的 PSNR,然后取平均值
- 计算 RGB 三通道的 MSE ,然后再除以 3
- 将图片转化为 YCbCr 格式,然后只计算 Y 分量也就是亮度分量的 PSNR
# im1 和 im2 都为灰度图像,uint8 类型
# method 1
diff = im1 - im2
mse = np.mean(np.square(diff))
psnr = 10 * np.log10(255 * 255 / mse)
# method 2
psnr = skimage.measure.compare_psnr(im1, im2, 255)
数据集
可以使用Tungsten引擎来生成, 也可以去开源的站点去下载。 下面主要介绍使用引擎生成数据集的方式。
Tungsten是一个基于物理的渲染器,最初为ETH年的年度渲染竞赛编写。 它通过对渲染方程的无偏积分来模拟通过任意几何的全光传输。 Tungsten支持各种光传输算法,如双向路径跟踪BRDF、渐进光子映射、空间城市光传输等。Tungsten是用C++11编写的,利用了几何交叉库embree的高性能。 Tungsten充分利用多核系统,并通过频繁的基准和优化来提供良好的性能。 运行渲染器至少需要SSE3支持。

编译生成引擎, 需要你本地已经安装了GCC, 下载然后make:
git clone https://github.com/tunabrain/tungsten.git
./setup_builds.sh
cd build/release
make
然后添加Tungsten 到环境变量PATH里去,(Mac系统保存环境变量在.profle文件)
echo 'export PATH="<tungsten-release-dir>":$PATH' >> ~/.bashrc
source ~/.bashrc
在终端里敲命令,看是否配置成功:
tungsten -v
下载场景贴图(大概860张建筑贴图):
cd data && mkdir scenes
wget https://benedikt-bitterli.me/resources/tungsten/bathroom.zip
unzip bathroom.zip -d scenes
rm *.zip
render.py生成训练集:
python3 render.py \
--scene-path ../data/scenes/bathroom/scene.json \
--spp 8 \
--nb-renders 48 \
--output-dir ../data/mc/train \
--hdr-targets
Tungsten生成的mc-noised 和cleaned 图像对比:

Unity 生成的mc-noised 和 cleaned的图像对比:

NL-Means算法
NL-Means的全称是:Non-Local Means,直译过来是非局部平均,在2005年由Baudes提出,该算法使用自然图像中普遍存在的冗余信息来去噪声。与常用的双线性滤波、中值滤波等利用图像局部信息来滤波不同的是,它利用了整幅图像来进行去噪,以图像块为单位在图像中寻找相似区域,再对这些区域求平均,能够比较好地去掉图像中存在的高斯噪声。NL-Means的滤波过程可以用下面公式来表示:
在这个公式中,w(x,y)是一个权重,表示在原始图像v中,像素 x 和像素 y 的相似度。这个权重要大于0,同时,权重的和为1,用公式表示是这样:
Ωx是像素 x 的邻域。这个公式可以这样理解:对于图像中的每一个像素 x ,去噪之后的结果等于它邻域中像素 y 的加权和,加权的权重等于 x 和 y 的相似度。这个邻域也称为搜索区域,搜索区域越大,找到相似像素的机会也越大,但同时计算量也是成指数上升。在提出这个算法的文献中,这个区域是整幅图像!导致的结果是处理一幅512x512大小的图像,最少也得几分钟。
衡量像素相似度的方法有很多,最常用的是根据两个像素的亮度值的差的平方来估计。但因为有噪声的存在,单独的一个像素并不可靠。对此解决方法是,考虑它们的邻域,只有邻域相似度高才能说这两个像素的相似度高。衡量两个图像块的相似度最常用的方法是计算他们之间的欧氏距离:
其中: n(x) 是一个归一化的因子,是所有权重的和,对每个权重除以该因子后,使得权重满足和为1的条件。 h>0 是滤波系数,控制指数函数的衰减从而改变欧氏距离的权重。 V(x) 和 V(y) 代表了像素 x 和像素 y 的邻域,这个邻域常称为块(Patch)邻域。块邻域一般要小于搜索区域。${|{V(x) - V(y)}|_{2,a}^2}$ 是两个邻域的高斯加权欧式距离。其中 a>0 是高斯核的标准差。在求欧式距离的时候,不同位置的像素的权重是不一样的,距离块的中心越近,权重越大,距离中心越远,权重越小,权重服从高斯分布。实际计算中考虑到计算量的问题,常常采用均匀分布的权重。

如上图所示,p为去噪的点,因为q1和q2的邻域与p相似,所以权重w(p,q1)和w(p,q2)比较大,而邻域相差比较大的点q3的权重值w(p,q3)很小。如果用一幅图把所有点的权重表示出来,那就得到下面这些权重图:

这6组图像中,左边是原图,中心的白色色块代表了像素 x 块邻域,右边是计算出来的权重 w(x,y) 图,权重范围从0(黑色)到1(白色)。这个块邻域在整幅图像中移动,计算图像中其他区域跟这个块的相似度,相似度越高,得到的权重越大。最后将这些相似的像素值根据归一化之后的权重加权求和,得到的就是去噪之后的图像了。
这个算法参数的选择也有讲究,一般而言,考虑到算法复杂度,搜索区域大概取21x21,相似度比较的块的可以取7x7。实际中,常常需要根据噪声来选取合适的参数。当高斯噪声的标准差 σ 越大时,为了使算法鲁棒性更好,需要增大块区域,块区域增加同样也需要增加搜索区域。同时,滤波系数 h 与 σ 正相关:h=kσ,当块变大时,k 需要适当减小。
NL-Means算法的复杂度跟图像的大小、颜色通道数、相似块的大小和搜索框的大小密切相关,设图像的大小为N×N,颜色通道数为Nc,块的大小为k×k,搜索框的大小为n×n,那么算法复杂度为:O(N2Nck2n2)。对512×512的彩色图像而言,设置k=7,n=21,OpenCV在使用了多线程的情况下,处理一幅图像所需要的时间需要几十秒。虽然有人不断基于这个算法进行改进、提速,但离实时处理还是比较远。
最后来看一下这个算法的去噪效果[3]:

BM3D算法
BM3D(Block-matching and 3D filtering,3维块匹配滤波)可以说是当前效果最好的算法之一。该算法的思想跟NL-Means有点类似,也是在图像中寻找相似块的方法进行滤波,但是相对于NL-Means要复杂得多,理解了NL-Means有助于理解BM3D算法。BM3D算法总共有两大步骤,分为基础估计(Step1)和最终估计(Step2):
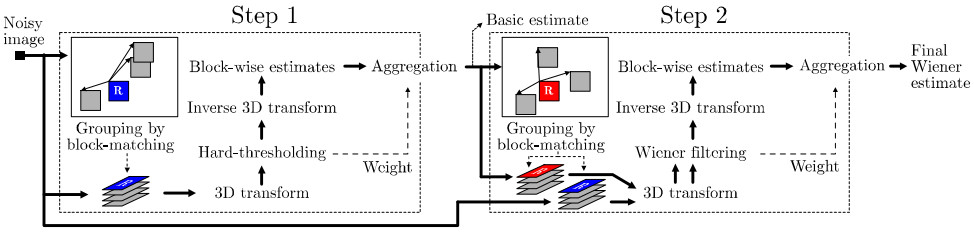
在这两大步中,分别又有三小步:相似块分组(Grouping),协同滤波(Collaborative Filtering)和聚合(Aggregation)。上面的算法流程图已经比较好地将这一过程表示出来了,只需要稍加解释。
Stpe1:基础估计
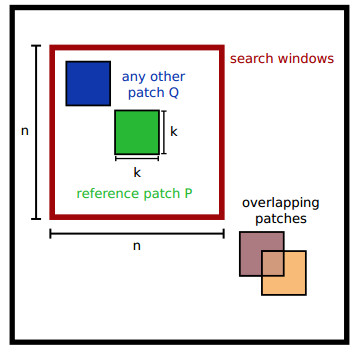
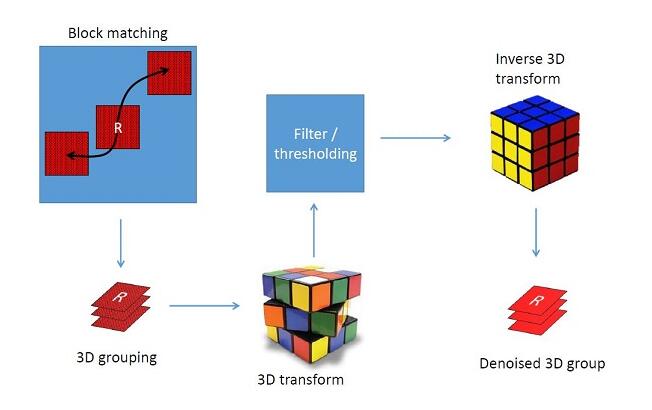
(1) Grouping:有了NL-Means的基础,寻找相似块的过程很容易理解。首先在噪声图像中选择一些k×k 大小的参照块(考虑到算法复杂度,不用每个像素点都选参照块,通常隔3个像素为一个不长选取,复杂度降到1/9),在参照块的周围适当大小(n×n)的区域内进行搜索,寻找若干个差异度最小的块,并把这些块整合成一个3维的矩阵,整合的顺序对结果影响不大。同时,参照块自身也要整合进3维矩阵,且差异度为0。寻找相似块这一过程可以用一个公式来表示:
d(P,Q)代表两个块之间的欧式距离。最终整合相似块获得的矩阵就是流程图Step1中左下角的蓝色R矩阵。
(2) Collaborative Filtering:形成若干个三维的矩阵之后,首先将每个三维矩阵中的二维的块(即噪声图中的某个块)进行二维变换,可采用小波变换或DCT变换等,通常采用小波BIOR1.5。二维变换结束后,在矩阵的第三个维度进行一维变换,通常为阿达马变换(Hadamard Transform)。变换完成后对三维矩阵进行硬阈值处理,将小于阈值的系数置0,然后通过在第三维的一维反变换和二维反变换得到处理后的图像块。这一过程同样可以用一个公式来表达:
在这个公式中,二维变换和一维变换用一个T3Dhard 来表示。γ是一个阈值操作:
σ是噪声的标准差,代表噪声的强度。
(3) Aggregation:此时,每个二维块都是对去噪图像的估计。这一步分别将这些块融合到原来的位置,每个像素的灰度值通过每个对应位置的块的值加权平均,权重取决于置0的个数和噪声强度。
Step2:最终估计
(1) Grouping:第二步中的聚合过程与第一步类似,不同的是,这次将会得到两个三维数组:噪声图形成的三维矩阵Qbasic(P)和基础估计结果的三维矩阵Q(P)。
(2) Collaborative Filtering:两个三维矩阵都进行二维和一维变换,这里的二维变换通常采用DCT变换以得到更好的效果。用维纳滤波(Wiener Filtering)将噪声图形成的三维矩阵进行系数放缩,该系数通过基础估计的三维矩阵的值以及噪声强度得出。这一过程同样可以用一个公式来表达:
在这个公式中,二维变换和一维变换用一个T3Dwein 来表示。wp是一个维纳滤波的系数:
σ是噪声的标准差,代表噪声的强度。
(3) Aggregation:与第一步中一样,这里也是将这些块融合到原来的位置,只是此时加权的权重取决于维纳滤波的系数和噪声强度。
经过最终估计之后,BM3D算法已经将原图的噪声显著地去除。可以来看一组结果:

该算法的主要运算量还是在相似块的搜索与匹配上,在与NL-Means同样大小的相似块和搜索区域的情况下,BM3D的算法复杂度是要高于NL-Means的,应该大概在NL-Means的3倍左右。实时处理是跑不起来了。
两个算法的PSNR比较
| NL_Mean | BM3D | |
|---|---|---|
| PSNR | 32.09 | 33.67 |
NL-Means和BM3D可以说是目前效果最好的去噪算法,其中BM3D甚至宣称它可以得到迄今为止最高的PSNR。从最终的结果也可以看出来,BM3D的效果确实要好于NL-Means,噪声更少,能够更好地恢复出图像的细节。
光线追踪降噪
目前光线跟踪要做到实时,每个像素的光线是比较有限的,一般一个像素一条光线(1spp),在1spp下显然渲染出来的阴影充满噪点,为了能够在很低样本下得到比较好的结果,学术界和工业界提出一系列除噪算法,像SVGF、NVIDIA RTX Shadow Denoiser之类能够在1spp下完成除噪,这些算法的基本原理是复用样本,增大有效样本数目来降低噪声,首先空间上使用卷积的方法,比如用高斯核收集周边的样本,但是这样会把图像模糊化,所以需要像SVGF通过自适应核控制核的宽度或者RTX Shadow Denoiser代替图像空间使用世界空间核,对核的长宽方向进行优化,来避免模糊的现象,然后在时间上使用类似TAA的方法收集样本,对于静态场景时间样本是可靠的,所以一边收集一边调整空间核的大小,进一步提高除噪效果,但是运动场景TAA找不到正确的运动向量,会出现鬼影问题,就需要一系列类似neighbor clamping方法来除去鬼影。
Noise2Noise
深度学习方法进行图像去噪的时候,通常需要大量的训练图像样本对,即带有噪声的图片和去噪后的图片,可是去噪后的图片往往很难获得,比如在摄影中,需要长曝光才能获得无噪声图片。在MRI图像中,获取无噪声图片则更加难。
Noise2Noise一种不需要无噪声图片作为标签的去噪方法。方法非常有意思,实现起来也很简单。那就是:输入输出都是带有噪声的图片(噪声是人工加入的,0均值,高斯噪声),进行训练。
假设我们有一组温度采样数据(y1,y2,…)。我们希望在某种损失度量L下,得到温度估计值z(希望该损失最小):
于所有观测y,都要最小化损失。所以可以把L看成一个以y为变量的概率分布,最小化所有样本的损失,其实就是最小化期望(即损失的均值)。如果距离度量方式是2范数,那么真实温度z就是y的均值。所以,真实温度,其实是y的均值,至于每一次观测y(i)是什么,根本不重要,优化的目标是考虑所有观测的均值。
那么,对于图像去噪问题,输入噪声图像设为x(i),输出的清晰图像设为y(i)。那么,我们可以将问题建模为如下优化问题:
上述公式的$\theta$是CNN的权重参数,x, y不是相互独立的,所以左式等于右式。
同样的,如果改变p(y/x)的分布,只要条件期望不变,最终求得的$\theta$
也不会变。所以,如果我们对标签y添加一个0均值的高斯噪声作为扰动得到y’。那么,上述建模
其中,$x^i$是有噪图像,$y^i$也是有噪图像($y_i$不一定要和$x_i$相同),y就是目标干净图像。
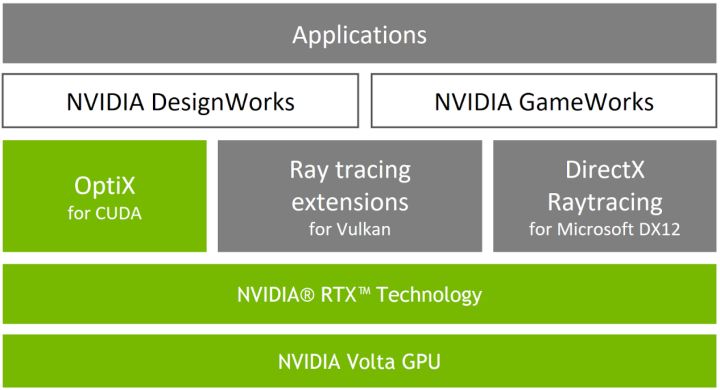
NVIDIA OptiX
NVIDIA OptiX API是基于GPU实现高性能光线追踪的应用程序框架。它为加速光线追踪算法提供了一个简单、递归且灵活的管线。OptiX SDK包含两个可相互独立使用的主要组件:用于渲染器开发的光线追踪引擎和post process管线来处理最终显示的像素。
OptiX使用Iray渲染的成千上万的图像构建了一个神经网络,现在这个学习的数据可以应用到其他光线跟踪图像。 凭借OptiX引擎,从前需要耗费数分钟的软件操作现在只需几毫秒即可完成,从而让设计师能够在行业标准硬件上交互地检查真实场景中的光照、反射、折射以及阴影的播放效果。 NVIDIA®(英伟达™)Quadro和Tesla产品拥有业内最大容量的显存,能够处理最大的数据集,可打造出高可靠性的解决方案,非常适合用于GPU光线追踪。 Quadro还能够提供顶级图形性能,是专业人士在处理图形与光线追踪时的首选产品。
OptiX AI降噪技术与Quadro GV100和Titan V中的全新NVIDIA Tensor Cores相结合,可提供相当于前代GPU 3倍的性能,并首次实现了无噪声流体交互。
Nvidia 允许开发者构建自己的神经网络, 使用Optix来加速降噪运算, 从而实现更好的效果, 详细参见siggraph-2017教程, 专门针对路径追踪,由于蒙特卡洛采样次数不足产生的noise picture降噪的神经网络。

构建一个降噪神经网络, 如基于AutoEncoder实现的Noise2Noise, 训练的时候不需要清晰的图片一样可以产生降噪后的图片。
OptiX 5 AI降噪效果视频 youtube
NVIDIA RTX
NVIDIA正式推出了基于新的Turing架构的RTX系列显卡,除了全新的架构之外,我们还引入了一个全新的硬件单元叫RTCcore,主要是用来加速射线和几何体求交,为实时光线追踪奠定硬件上的基础。除此之外,我们还加入了Tensor Core用来加速AI计算。
光线追踪需要快速的找到射线和场景中物体的交点,所以快速对场景进行遍历求交就显得尤为重要。为了加速这个过程,通常我们需要对场景里面的物体建立加速结构,就像普通的剔除一样,对场景中的物体建立八叉树之类的结构进行管理。
BVH 算法
BVH即bounding volume Hierachy, 即专门用来求射线与三角形的交点的快速算法。
如下图所示,是演示如何找到一条射线和兔子头部的交点。
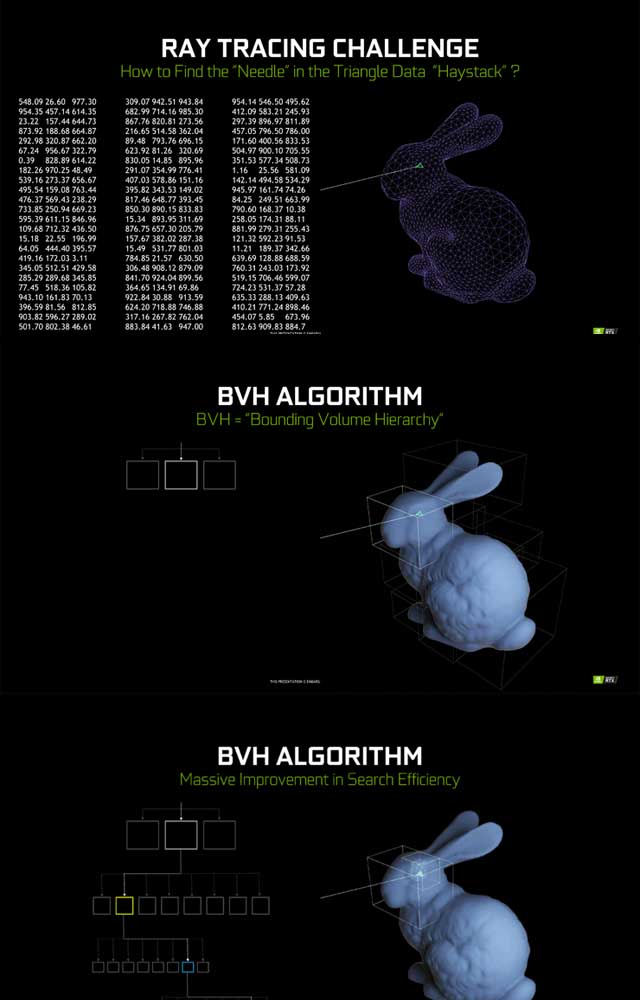
第一步,先找到包含整个兔子头部的大的包围盒,然后发现这个包围盒的子节点是更小的包围盒。
第二步,看射线与哪个子包围盒相交。如果找到了相交的子包围盒,就重复递归以上过程,直到找到子节点里包含的不再是包围盒而是具体的图元信息,图元信息一般为三角形,我们就开始求交三角形与射线的交点,并返回交点信息。
在Turing之前这些步骤都是在Shader里面模拟的。右侧的图可以看到Shader里面先产生一条射线,然后射线进入到加速结构遍历求交的过程。
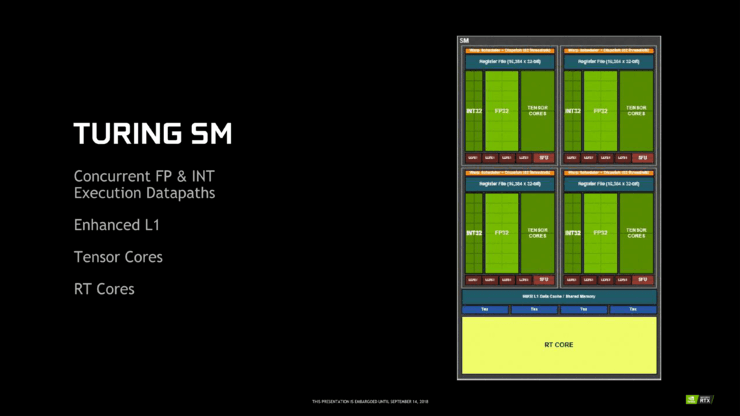
首先取出包围盒数据,包围盒解码。然后判断下一级是子包围盒还是三角形,如果是包围盒就重复以上过程,直到找到三角形,然后进行射线三角形求交计算并返回交点。
黄色的部分就是加速结构的遍历求交过程,这一部分通常需要上千条指令,是比较耗时的一个过程。在Turing中就把黄色的这块加速结构遍历求交的计算,放在全新的硬件单元RTCore上去执行,所以速度会提升很多,而Shader还是在SM上执行的。
那么光线追踪的过程就变成了执行在SM单元上的Shader里面产生射线信息,然后将这条射线的求交查询请求发往RTCore,RTCore收到请求后就进行加速结构的遍历及相交测试,如果找到交点就将交点信息返回到SM单元里面的Shader进行着色计算。所以在Turing中RTCore是放在SM旁边的,这就是硬件的架构图。

RTCore极大的提升了射线与物体求交的速度,性能方面我们这边有组数据,上图中,在1080Ti上,我们使用Shader模拟大概支持的射线是每秒1G左右,在2080Ti上有RTCore可以达到每秒10G,所以性能提升了大概10倍。
DXR 光线追踪
在GDC 2018全球游戏开发者大会上,微软推出了名为DirectX Raytracing(DirectX光线追踪,简称DXR)的新功能。通过DXR API,图像设备可以进行实时光线追踪。DXR API还带来了一系列全新技术(如实现真实全局光照),为未来的游戏世界打开了大门。在起步阶段,它将用于补充当前的渲染技术,如屏幕空间反射等。微软希望通过DXR,取代当前的光栅化技术。
场景数据结构
在Raytrace Pipeline中,几何数据由两层结构存储,其中底层的数据结构称之为Bottom Level Acceleration Structure,上层的数据结构叫做Top Level Acceleration Structure。
在Unity(需要升级到2019.3之后的版本)中检查设备是否支持:
if (!SystemInfo.supportsRayTracing)
{
Debug.LogError("You system is not support ray tracing. Please check your graphic API is D3D12 and os is Windows 10.");
}
使用DX12的api检查是否支持这种硬件加速结构:
#define FAILED(hr) (((HRESULT)(hr)) < 0)
ID3D12Device5Ptr pDevice;
d3d_call(D3D12CreateDevice(pAdapter, D3D_FEATURE_LEVEL_12_0, IID_PPV_ARGS(&pDevice)));
D3D12_FEATURE_DATA_D3D12_OPTIONS5 features5;
HRESULT hr = pDevice->CheckFeatureSupport(D3D12_FEATURE_D3D12_OPTIONS5, &features5, sizeof(D3D12_FEATURE_DATA_D3D12_OPTIONS5));
if (FAILED(hr) || features5.RaytracingTier == D3D12_RAYTRACING_TIER_NOT_SUPPORTED)
{
msgBox("Raytracing is not supported on this device. Make sure your GPU supports DXR (such as Nvidia's Volta or Turing RTX) and you're on the latest drivers. The DXR fallback layer is not supported.");
exit(1);
}
return pDevice;
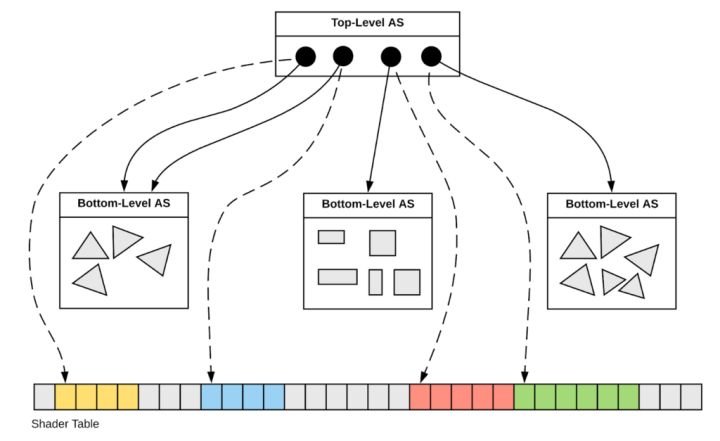
Bottom Level AS:这层存放一般意义上的顶点数据,类似于Raster Pipeline的Vertex/Index Buffer的集合。当然如果是非三角面的话,可能存放的是其他数据(比如参数曲面的控制点)。
Top Level AS:Top Level AS是模型级别的场景信息描述,它的每一项数据引用一个Bottom Level AS(当做该模型的几何数据),并单独定义了该模型的模型变换矩阵以及包围盒。
基于这样双层的数据结构,我们就可以调用DXR API创建整个场景的查询结构,这个查询结构是一个BVH(Bounding Volume Hierarchy),用来加速光线-场景的相交测试。可以想象,当一个相交测试开始时,光线首先会和BVH进行相交测试,通过的对象才会进一步访问其Bottom Level AS数据执行具体的光线-三角面相交测试。
由于整个BVH只用于进行光线-场景相交测试,因此它只包含顶点位置的信息,如果我们需要顶点位置之外的信息(uv,normal等),则往往需要额外自定义一个SRV/UAV Buffer用于存储这些数据。
在Unity2019.3版本中, 构建加速运算结构使用RayTracingAccelerationStructure, 例如:
var _accelerationStructure = new RayTracingAccelerationStructure();
foreach (var r in renderers)
{
if (r)
_accelerationStructure.AddInstance(r, subMeshFlagArray, subMeshCutoffArray);
}
_accelerationStructure.Build();
Raytrace Pipeline的流程
下图是Raytrace Pipeline的基本流程图,其中绿色的部分表示可编程单元,灰色的则是固定单元。可以看出Raytrace Pipeline以可编程管线为主,只有极少的固定单元。基本概念中我们已经介绍过,任何一个光线追踪的渲染程序都是从Ray Generation Shader开始,它负责初始的光线生成,生成的初始光线会通过固定的软/硬件单元对整个场景(我们构建好的BVH,在DXR中也就是Top Acceleration Structure)进行遍历求交,这个求交过程可以是用户自定义的一个Intersection Shader,也可以是默认的三角形相交测试。一旦相交测试通过,即得到了一个交点,这个交点将会被送给Any Hit Shader去验证其有效性,如果该交点有效,则它会和已经找到的最近交点去比较并更新当前光线的最近交点。当整个场景和当前光线找不到新的交点后,则根据是否已经找到一个最近交点去调用接下来的流程,若没有找到则调用Miss Shader,否则调用Closest Hit Shader进行最终的着色。
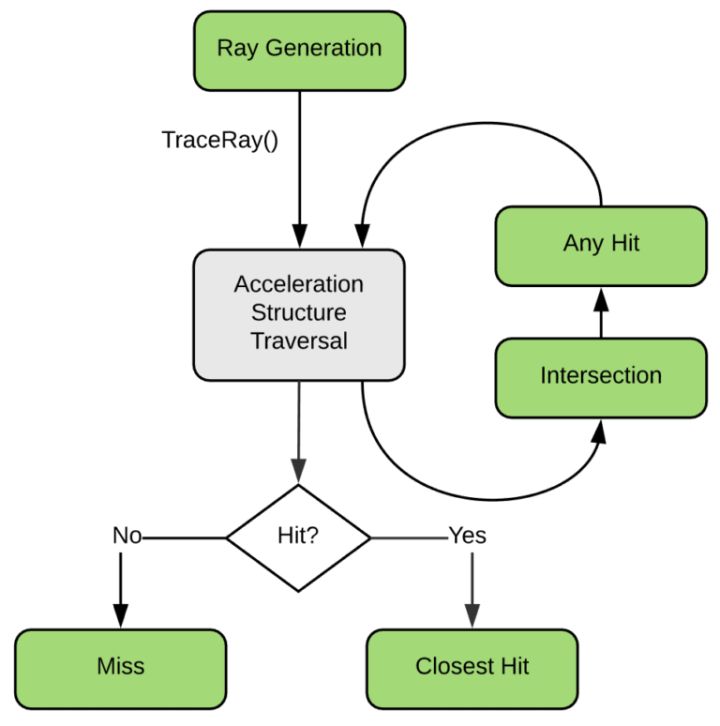
在DXR API中一共有五类着色器:
Ray Generation Shader:
这个Shader负责初始化光线,是整个DXR可编程管线的入口,我们在其中调用TraceRay函数向场景发射一条光线。Ray Generation Shader从结构上非常像Compute Shader(在 GPU硬件中,它很可能也是通过Compute Pipeline来实现的),不同的是Compute Shader的组织形式是Group->Thread这样的架构,同一个Group中的Thread可以使用Shared Memory及一些原子操作进行数据共享和同步,但在Ray Generation Shader中,每条光线是彼此独立的,他们之间不需要线程间的同步和共享。此外RayGeneration Shader也负责最终着色结果的输出(通常是输出到一个UAV对应的Texture上)。
Intersection Shader
这个Shader是可选的,它只负责一件事,就是定义场景内基本的几何单元和光线的相交判定方法。如果场景的基本几何单元是三角面,则用户不需要自定义这个Shader,但如果不是三角面,而是用户自定义的几何形式,比如是用于体渲染的体素结构,或者是用于曲面细分的参数曲面,则用户需要提供提供相交判定的方法。这样的设定使得一些过程生成式模型(细分曲面,烟雾,粒子等)也能够使用光线追踪的框架进行渲染。需要注意的是,对于三角面来说,通过相交测试返回的是交点的重心坐标,用户需要根据重心坐标自行插值得到交点的相关几何数据(uv, normal等)。
Any Hit Shader
这个Shader的作用是验证某个交点是否有效,典型的应用是alpha test,比如我们找到了一个光线和场景的交点,但该位置刚好是草地中被alpha通道过滤掉的像素位置,我们希望光线穿过它继续查找新的交点,那么就可以在这个Shader中忽略找到的交点,此外,我们也可以在这个Shader中发射新的光线,一个可能的应用场景是折射/反射效果的实现。
Closest Hit Shader
当一条发射的光线经过和场景的若干次求交最终找到一个有效的最近交点后,就会进入这个Shader,这个Shader的作用很像我们在Graphics Pipeline中用的Pixel Shader,它用于某个找到的样本点的最终着色。
Miss Shader
这是一个可能会被忽略的细节,即如果找不到有效的交点怎么办?在真实世界中一条光线总是会和某个表面相交,但虚拟场景的有限空间内却并非如此,这时候我们可能希望进行一次cube map的采样,或者告诉Ray Generation Shader它没找到交点,这些行为都可以在Miss Shader里定义。
参考资料
- Tungsten 基于物理的渲染器
- 几何交叉库 embree
- 峰值信噪比, PSNR, 百科
- Learning Image Restoration without Clean Data, arxiv
- Learning Image Restoration without Clean Data, pytorch, github
- Learning Image Restoration without Clean Data, tensorflow, github
- NVIDIA Optix Instro
- v-ray instro, 百科
- NVIDIA OptiX Denoise
- 基于RTX的NVIDIA OptiX光线追踪, 知乎
- Microsoft’s DirectX Ray Tracing (DXR)
- NVIDIA Vulkan Ray Tracing Tutorial
- Interactive Reconstruction of Monte Carlo Image Sequences
- 图像处理之添加高斯与泊松噪声
- DX 管理追踪光线流程
- 光线追踪的入门, 知乎
- RayTracingAccelerationStructure in Unity API
- CUDA-Path-Tracer-Denoising -github
- Spatiotemporal Variance-Guided Filter, 向实时光线追踪迈进