CoreML一瞥
在这篇博文中,我们将快速了解 CoreML 模型的内部结构,以及运行模型时设备和 GPU 上发生的情况。了解 CoreML 背后的工作原理和更轻松地解决在使模型工作时可能遇到的任何问题。
.mlmodel 文件中有什么?
要在 Core ML 中使用机器学习模型,它需要采用mlmodel格式。使用coremltools Python包将经过训练的模型转换为这种格式。但是这样的.mlmodel文件究竟是什么?
mlmodel 文件格式基于protobuf。您可以在此处下载 mlmodel规范。当解压缩此文件夹时,它包含一堆.proto文件,主要的一个是Model.proto,它包括所有其他的。
您可以使用文本编辑器打开这些文件并查看内部。这是摘录:
message Model {
int32 specificationVersion = 1;
ModelDescription description = 2;
// start at 200 here
// model specific parameters:
oneof Type {
// pipeline starts at 200
PipelineClassifier pipelineClassifier = 200;
PipelineRegressor pipelineRegressor = 201;
Pipeline pipeline = 202;
// regressors start at 300
GLMRegressor glmRegressor = 300;
CoreML所有内容都由这些.proto描述, 如神经网络层描述配置在 NeuralNetwork.proto。
虽然这些 proto 文件对于理解 CoreML 的可能性和局限性很有用,但我们仍可以使用它们来查看 mlmodel 文件的内部。毕竟,mlmodel 文件只不过是这种 protobuf 格式的二进制文件。先使用brew或者pip来安装 protobuf:
brew update
brew install protobuf
# ....
pip3 install -U protobuf
现在进入 mlmodel_specification 文件夹(包含 proto 文件的文件夹)并运行以下命令:
$ protoc --python_out=. *.proto
这将为每个 proto 文件创建一个_pb2.py文件。protobuf 编译器将 proto 文件中的每个定义转换为可以在 Python 中使用的对象。
使用以下内容创建一个新的 Python 脚本:
import os
import sys
import Model_pb2
model = Model_pb2.Model()
with open("Inceptionv3.mlmodel", "rb") as f:
model.ParseFromString(f.read())
该行import Model_pb2加载我们刚刚从 Model.proto 生成的文件(依次导入所有其他文件)。该Model_pb2模块包含一个Model可用于加载 mlmodel 文件的类,在本例中为来自developer.apple.com/machine-learning/ 的Inceptionv3.mlmodel。
protobuf 的好处在于它隐藏了所有的解析逻辑。要读取 mlmodel 文件,只需使用与.proto中的定义看起来完全相同的本机对象。
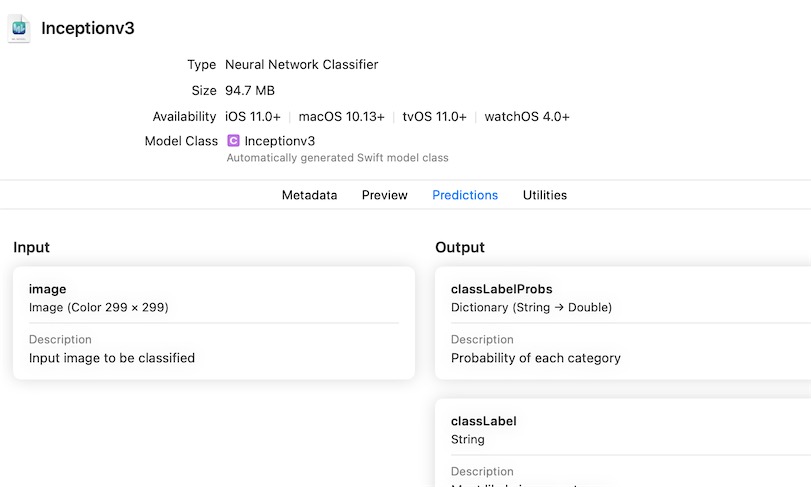
Model.proto 包含一个Model带有description属性的定义。要打印出此属性的值,您只需将此行添加到脚本中:
print(model.description)
结果:
input {
name: "image"
shortDescription: "Input image to be classified"
type {
imageType {
width: 299
height: 299
colorSpace: RGB
}
}
}
output {
name: "classLabelProbs"
shortDescription: "Probability of each category"
type {
dictionaryType {
stringKeyType {
}
}
}
}
output {
name: "classLabel"
shortDescription: "Most likely image category"
type {
stringType {
}
}
}
predictedFeatureName: "classLabel"
predictedProbabilitiesName: "classLabelProbs"
metadata {
shortDescription: "Detects the dominant objects present in an image from a set of 1000 categories such as trees, animals, food, vehicles, person etc. The top-5 error from the original publication is 5.6%."
author: "Original Paper: Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna. Keras Implementation: Fran\303\247ois Chollet"
license: "MIT License. More information available at https://github.com/fchollet/keras/blob/master/LICENSE"
}
这个打印结果和xcode里是一致的:
使用这个接口还可以打印所有的layer:
for layer in model.neuralNetworkClassifier.layers:
print(layer.name)
if layer.HasField("convolution"):
print("\tis convolution")
print("\tkernel size:", layer.convolution.kernelSize)
print("\tinput channels", layer.convolution.kernelChannels)
print("\toutput channels", layer.convolution.outputChannels)
运行结果:
convolution2d_1
is convolution
kernel size: [3, 3]
input channels 3
output channels 32
convolution2d_1__activation__
batchnormalization_1
convolution2d_2
is convolution
kernel size: [3, 3]
input channels 32
output channels 32
convolution2d_2__activation__
. . .
batchnormalization_94
mixed10
avg_pool
flatten
predictions
predictions__activation__
编写这样的脚本有助于检查 coremltools 转换过程所做的工作,并验证它所包含的层。
CoreML对于拍摄图像的模型,输入图像能转换成模型所期望的Shape。要验证模型进行了什么样的预处理,可以编写:
print(model.neuralNetworkClassifier.preprocessing)
[scaler {
channelScale: 0.007843137718737125
blueBias: -1.0
greenBias: -1.0
redBias: -1.0
}
]
这意味着 CoreML 首先将每个像素与0.007843(恰好是)相乘1/127.5,然后1.0从每个颜色通道中减去。如此有效地将像素从范围 [0, 255] 缩放到范围 [-1, 1]。
模型
在创建好 .mlmodel,当将它发送到 App Store 时,该文件实际上并未包含在您的应用程序包中。相反,Xcode将.mlmodel编译成.mlmodelc。
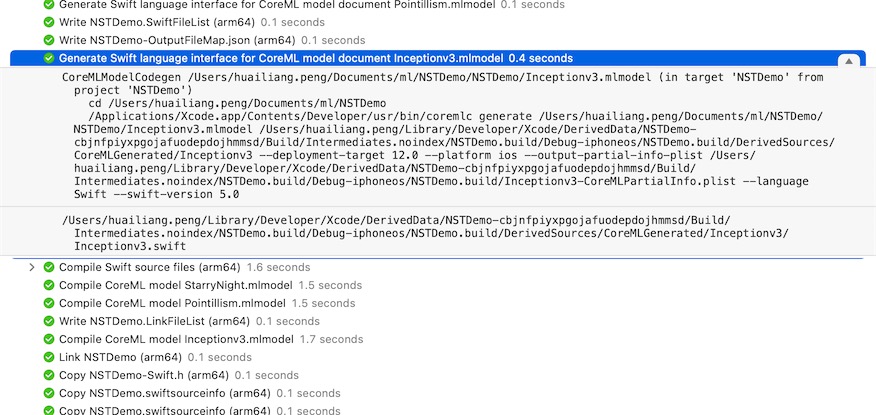
当将 Inceptionv3.mlmodel 添加到您的项目并构建应用程序时,Xcode 执行以下构建步骤:
/Applications/Xcode.app/Contents/Developer/usr/bin/coremlc generate
/path/to/Inceptionv3.mlmodel ... --language Swift --swift-version 4.0
/Applications/Xcode.app/Contents/Developer/usr/bin/coremlc compile
/path/to/Inceptionv3.mlmodel ...
构建时首先生成Inceptionv3.swift包含源文件MLModel包装类,然后将其编译mlmodel文件到mlmodelc文件夹,并把它添加到应用程序包。
查看模型编译步骤的输出(在 Xcode 报告导航器中),因为它显示了层的名称和大小:
除了xcode构建时生成.mlmodelc, 还可以通过一下接口生成:
mkdir output
xcrun coremlc compile Inceptionv3.mlmodel output
xcrun coremlc generate Inceptionv3.mlmodel output

其中.mlmodelc是 compile 生成的, .h, *.m 是generate的wrap接口, 因此如果有算法上云的部分,只能提前将编译生成的.mlmodelc 放在服务器等在下载, 而将脚本.m 需要编译到包体里去。 直接上传.bundle跳过构建应用阶段编译是无法生效的。
但是coreML提供了运行时编译mlmodel的接口,能实现动态编译:
//编译模型文件并通过编译版本创建MLModel实例。
let compiledUrl = try MLModel.compileModel(at: modelUrl)
let model = try MLModel(contentsOf: compiledUrl)
当打开 mlmodelc 文件夹。如果您在 Finder 中打开 .app 文件并选择“显示包内容”,它将显示您的应用程序包中的内容:
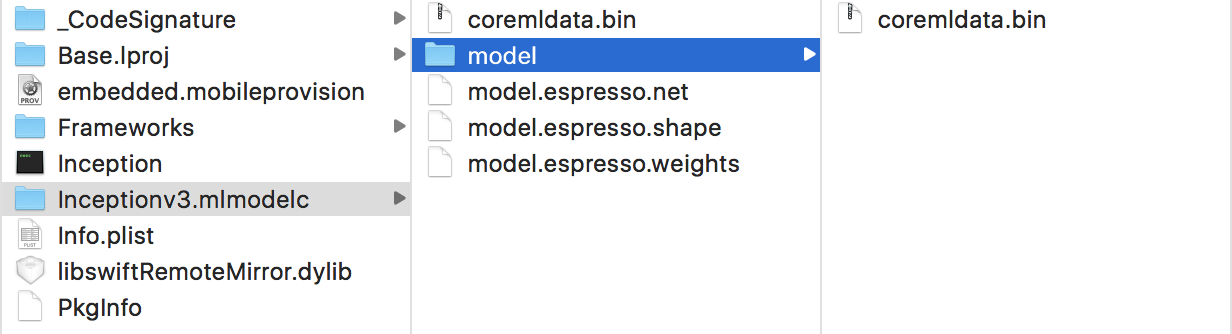
Inceptionv3.mlmodelc 文件夹包含以下文件:
coremldata.bin: 模型的元数据(作者姓名等)和分类标签
model.espresso.net: 描述模型的网络结构
model.espresso.shape: 神经网络中层的输出大小(与您在上面构建步骤的输出中看到的相同)
model.espresso.weights: 模型的学习参数(这通常是一个大文件,对于 Inception-v3 为 96MB)
coremldata.bin: 用于运行神经网络的 CoreML 部分的内部名称。
model.espresso.net, 这是一个普通的文本文件:
{
"storage" : "model.espresso.weights",
"properties" : {
},
"format_version" : 200,
"layers" : [
{
"pad_r" : 0,
"fused_relu" : 1,
"fused_tanh" : 0,
"pad_fill_mode" : 0,
"pad_b" : 0,
"pad_l" : 0,
"top" : "convolution2d_1__activation___output",
"blob_weights" : 3,
"K" : 3,
"blob_biases" : 1,
"stride_x" : 2,
"name" : "convolution2d_1",
"has_batch_norm" : 0,
"type" : "convolution",
其列出了所有模型的层,但这次以JSON格式而不是protobuf。为什么同一件事有两种不同的格式?我认为 mlmodel 应该是一种开放的标准文件格式,以便其他工具也可以加载 mlmodel 文件(例如,允许您在 Android 或 Linux 上使用您的 mlmodel 文件)另一方面,mlmodelc 是一种专有格式它针对 Apple 设备进行了优化,并且特定于iOS。
将 mlmodel 编译为私有格式的另一个原因是通常可以进行优化——例如将不同的层融合在一起——以减少推理时间。例如,如果 mlmodel 指定一个卷积层后跟一个缩放层,那么 CoreML 编译器可以删除该缩放层,而是使卷积层的权重更大或更小。结果是相同的,但它节省了一个计算步骤。
运行模型时会发生什么?
当我们在MLModel的predict()方法上设置了一个断点:

关闭xcode中的编译优化选项(xcode-> build settings -> Optimization Level),重新构建应用程序,然后运行。应用程序将在调用 时暂停handler.perform([request])。按几次调试器工具栏中的Step Into按钮,您将获得如下堆栈跟踪:

这里有几个类和方法名值得注意:
[VNCoreMLTransformer processWithOptions:regionOfInterest: warningRecorder:error:] 这可能就是将我们的图像缩放到 Inception 输入大小 299×299 像素的方法。
[VNCoreMLModel predictWithCVPixelBuffer:options:error]这似乎是一个私有方法VNCoreMLModel;你不应该自己调用它。(事实上,stacktrace 中的很多东西似乎都是私有的。)
[MLNeuralNetworkEngine predictionFromFeatures:options:error:] 这看起来像实际运行神经网络的类。
Espresso::abstract_context::compute_batch_sync 是 C++ 代码, 实现对底层 Metal Performance Shaders 的 CorML 包装。
这个过程可以总结为:首先调整图像大小,然后将其交给MLNeuralNetworkEngine,用于Espresso从 model.espresso.net 文件中读取神经网络定义,最后 MPS 执行在 GPU 上运行神经网络的实际工作。
CoreML 可以在 CPU 或 GPU 上运行模型。对于某些模型,使用 CPU 更有意义,但对于(深度)神经网络,GPU 是首选工具。Xcode 带有一个GPU Frame Capture按钮,让我们可以检查 GPU 正在做什么,我们可以使用它来监视 CoreML。
要在 CoreML 应用程序中启用 GPU 帧捕获,您需要添加几行代码(例如,在mainViewController内):
import Metal
var device: MTLDevice!
var commandQueue: MTLCommandQueue!
// in viewDidLoad():
device = MTLCreateSystemDefaultDevice()
commandQueue = device.makeCommandQueue()

运行应用程序,按下 GPU Frame Capture 按钮开始捕捉,等待一秒左右,再次按下按钮停止。当然,您实际上需要在捕获发生时进行 CoreML 预测。
现在 Xcode 将显示 GPU 在捕获期间正在做什么:

在上面的截图中,很明显卷积层的Conv占用了大部分时间。
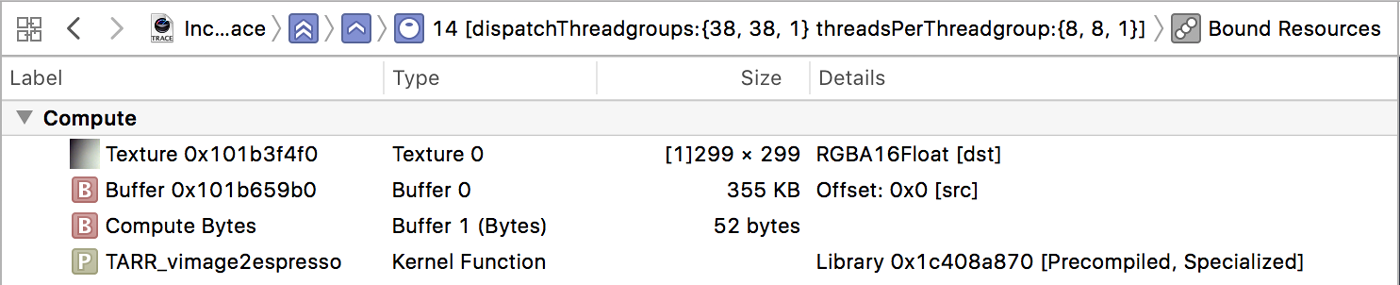
计算内核从包含输入图像的 355 KB 内存缓冲区(Buffer0)读取并写入 299×299 像素的纹理(Texture0)。回想一下,此时必须已经调整了输入图像的大小——很容易验证这一点:299×299 像素乘以每像素 4 个字节需要 355 KB 的存储空间,这确实是输入缓冲区的大小。
卷积核
现在让我们将注意力转向Conv命令编码器。它们具有具有特定名称的内核函数,例如cnnConvArray_3xIn_16xOut_1_3和cnnConvArray_8xIn_8xOut_1_2。很明显MPS有几个不同的计算内核来进行卷积,每个内核都针对特定情况定制的。
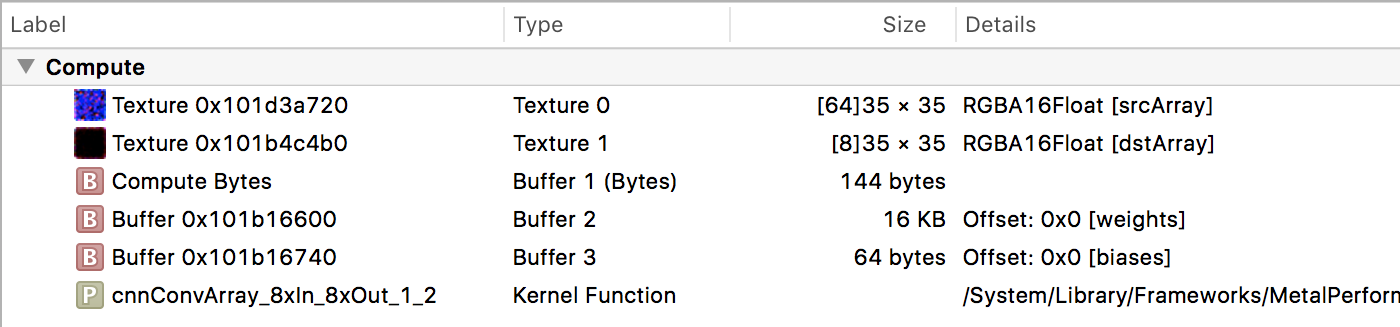
卷积核从纹理读取并写入新纹理。它需要三个缓冲区:Buffer1 包含内核大小、步长、激活函数值等(双击缓冲区查看);Buffer2 包含卷积权重;Buffer3 包含偏差项。
在 Xcode 调试窗格中,您可以找到有关此计算内核及其绑定资源的更多信息。
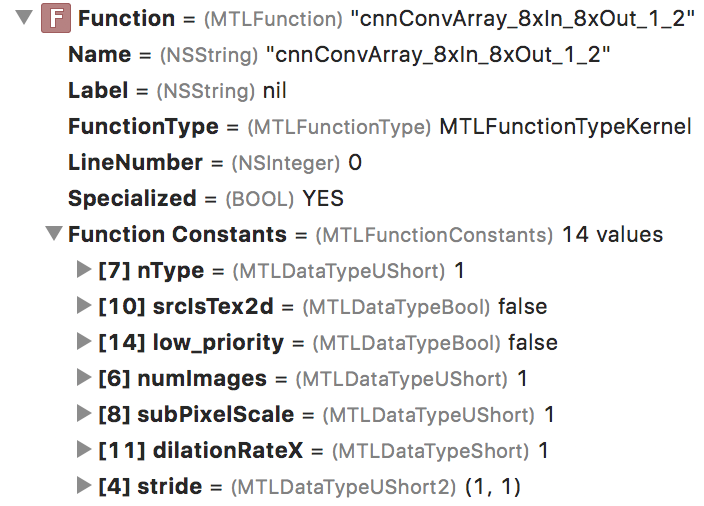
展开此项以显示函数常量下的其他参数。对于这个计算内核,nType 的值为 1。经过一些实验,我发现 nType 代表“神经元类型”,1 代表 ReLU。所以这个 nType 值告诉你这个层的激活函数是什么。
由此我们可以得出结论,在 MPS 中,激活函数被“融合”到了卷积核中,这样两个操作——卷积和激活——都可以在一个步骤中完成,这比单独进行要高效得多。很高兴知道!
多少线程?
另一个有趣的事情是这个计算内核的线程组的大小(在调试导航器窗格中):
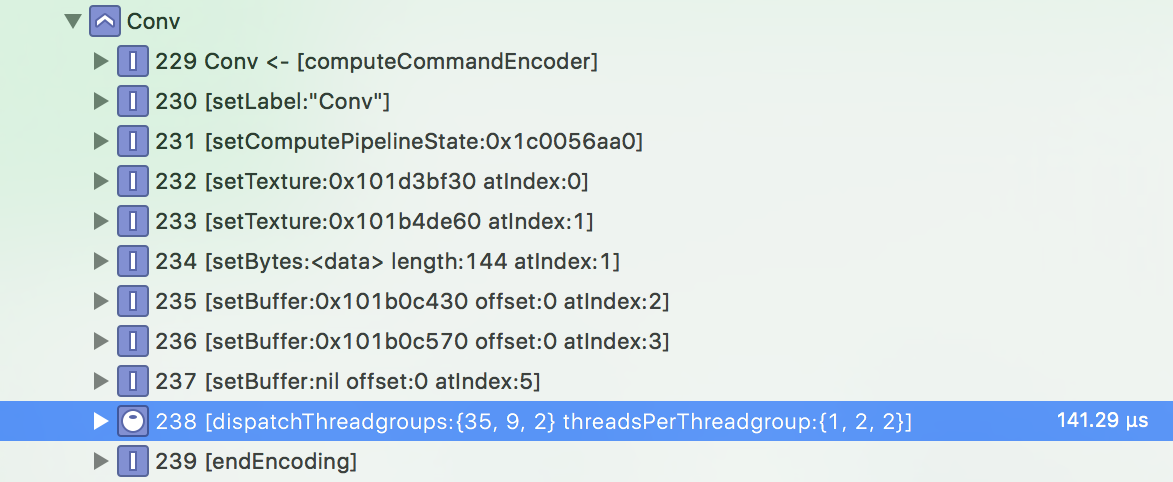
GPU 是大规模并行的:相同的计算内核将由许多线程并行执行,每个线程处理一小部分问题。在卷积层的情况下,每个线程计算输出纹理中的一个像素。线程由 GPU 分组调度。
在这种情况下,每个线程组包含 1×2×2 = 4 个线程,并且有 35×9×2 = 630 个组。所以总共有 630 × 4 = 2520 个线程启动来执行这个特定的卷积。这些数字从何而来?您必须询问编写这些 MPS 内核的 Apple 工程师,但大概选择他们是因为它们在此特定设备(10.5 英寸 iPad Pro)上在这种尺寸的问题上提供了最佳性能。
MPS有多个计算内核用于在各种情况下执行卷积,并且这些内核已经过调整以在不同的硬件和不同的图像大小上尽可能快地运行。线程组的大小以三个维度给出,因此我们有 35×1 线程处理图像的宽度,9×2 线程用于高度,2×2 线程用于深度。在这种情况下,输入纹理为 35×35 像素,具有 48×4 = 192 个通道。输出纹理也是 35×35,但只有 32 个通道。
将所有这些数字放在一起意味着每个线程水平处理一个像素(宽度为 35,我们有 35 个线程在该维度上工作)和两个像素垂直处理(高度也是 35,但我们只有 9×2 = 18 个线程在该维度上工作,因此 18 个线程执行 2 个像素,每个线程覆盖这 35 个像素)。每个线程写入 32 / 2×2 = 8 个输出通道的结果。