移动端AI算力加速
目前支持移动端(手机端)的框架, 主流的实现架构诸如苹果公司的CoreML, 华为麒麟芯片的支持AI加速的NPU和在上面运行框架HiAI,阿里的优化框架MNN, 还有腾讯公司的NCNN。 过去我们使用的AI运算大都是PC端搭建的GPU集群,往往运行着后端(云侧), 而在端侧往往只是负责拿到云侧数据进行表现。 随着手机端性能的提升, 其巨大的算力给AI拓扑带来了无限的可能。
一、概述
目前AI的主流实现都是基于反向传播算法的神经网络,前向传播进行推理, 反向传播计算梯度来更新参数。 主机上运行的主流框架多是谷歌公司的Tensorflow (Lite), Facebook公司开发的Pytorch 以及 Caffe, 然后他们在设计这些框架的时候, 往往更多的考虑的是算法的覆盖, 而不是性能。 我们常常看到这些复杂的网络结构大多跑在Nvidia的高端显卡上, 训练时间往往短则数日, 长则数周以致多大一两个月, 比如说Nvidia实现的StyleGAN。 由于这些特性, 特别不适应手机端的芯片。

随着国内厂商不断的优化, 我们看到了华为推出的麒麟芯片(麒麟980之后带独立的NPU)使用HiAI框架来进行AI加速运算, 阿里的MNN则依靠大量手写汇编实现核心运算,充分发挥 ARM CPU 的算力, 整合不同后端(backend: OpenCL、Vulkan、OpenGL, Metal)进行深度优化来适配不同的设备。这些国内的厂商都提供了各自的工具(比如说华为HiAI的转换工具OMG, 阿里的mmnconvert)来转换主机上运行的Tensorflow、Caffee模型为自己量化的模型。 在华为内部, 除了开源的HiAI, 也有类似的MNN的框架,同样实现了全平台的支持。 由于暂未开源,这里且不表。

在处理相同的AI运算时,NPU的性能是 CPU 的 25 倍,GPU 的 6.25 倍(25/4),能效比上,NPU 更是达到了 CPU 的 50 倍,GPU 的 6.25 倍(50/8)。在测试中发现,麒麟 970 的 NPU 每分钟可以识别出 2005 张照片,而不使用 NPU 的话则每分钟只能识别 97 张,明显看出独立NPU的算力优势巨大。
二、环境
我们看到国内厂商推出的Demo都是基于原生的语言开发出来的应用, 目前对游戏引擎这种跨平台的应用支持的还不多,这里大多是由于移动端的算子支持还不够全面, 从而导致有些主机上的模型导致转换失败,这就限制了移动端从主机端迁移的速度, 不过类似经典的MobileNet_v2都是支持的。
三. 生成数据集
本文以手势识别为例,首先创建一个数据集, 提取mnist的数据, 然后通过PIL的接口导出图片和对应的标签。代码如下:
import os
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
from PIL import Image
mnist = input_data.read_data_sets('./MNIST_data', one_hot=True)
# hack for duplicated library on MacOS
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
def save_raw():
save_dir = 'raw/'
if os.path.exists(save_dir) is False:
os.makedirs(save_dir)
f = open("raw/flag.txt", 'w')
for i in range(100):
image_array = mnist.test.images[i, :]
image_array = image_array.reshape(28, 28)
filename = save_dir + 'mnist_%d.jpg' % i
Image.fromarray((image_array * 255).astype('uint8'), mode='L').convert('RGB').save(filename)
label_array = mnist.test.labels[i, :]
print(np.argmax(label_array))
f.write(str(np.argmax(label_array)))
f.write("\n")
f.close()
save_raw()
四. 构建网络
我们在python环境下, 使用cnn网络简单搭建一个手写图片预测的神经网络, 并保证预测的准确率在90%以上。 然后到处网络以pb格式存储。
如下代码, 为了使用mnn中NHWC格式的数据, 我们将数据集进入ai网络前需要把[None, 28x28, 1]的格式转成[None, 28, 28, 1]的输入格式
mnist = input_data.read_data_sets('./MNIST_data', one_hot=True) # they has been normalized to range (0,1)
test_x = mnist.test.images[:2000]
test_x2 = np.reshape(test_x, (2000, 28, 28, 1))
test_y = mnist.test.labels[:2000]
tf_x = tf.placeholder(tf.float32, [None, 28, 28, 1]) / 255.
# image = tf.reshape(tf_x, [-1, 28, 28, 1]) # (batch, height, width, channel)
tf_y = tf.placeholder(tf.int32, [None, 10]) # input y
# CNN
conv1 = tf.layers.conv2d( # shape (28, 28, 1)
inputs=tf_x,
filters=16,
kernel_size=5,
strides=1,
padding='same',
activation=tf.nn.relu
) # -> (28, 28, 16)
pool1 = tf.layers.max_pooling2d(
conv1,
pool_size=2,
strides=2,
) # -> (14, 14, 16)
conv2 = tf.layers.conv2d(pool1, 32, 5, 1, 'same', activation=tf.nn.relu) # -> (14, 14, 32)
pool2 = tf.layers.max_pooling2d(conv2, 2, 2) # -> (7, 7, 32)
flat = tf.reshape(pool2, [-1, 7 * 7 * 32]) # -> (7*7*32, )
output = tf.layers.dense(flat, 10) # output layer
out_y = tf.argmax(output, 1, name="y_pred")
loss = tf.losses.softmax_cross_entropy(onehot_labels=tf_y, logits=output) # compute cost
train_op = tf.train.AdamOptimizer(LR).minimize(loss)
accuracy = tf.metrics.accuracy( # return (acc, update_op), and create 2 local variables
labels=tf.argmax(tf_y, axis=1), predictions=tf.argmax(output, axis=1), )[1]
sess = tf.Session()
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init_op) # initialize var in graph
for step in range(2000):
b_x, b_y = mnist.train.next_batch(BATCH_SIZE)
b_x2 = np.reshape(b_x, (-1, 28, 28, 1))
_, loss_ = sess.run([train_op, loss], {tf_x: b_x2, tf_y: b_y})
if step % 50 == 0:
accuracy_, flat_representation = sess.run([accuracy, flat], {tf_x: test_x2, tf_y: test_y})
print('Step:', step, '| train loss: %.4f' % loss_, '| test accuracy: %.2f' % accuracy_)
test_output = sess.run(out_y, {tf_x: test_x2[:10]})
# pred_y = np.argmax(test_output, 1)
print(test_output, 'prediction number')
print(np.argmax(test_y[:10], 1), 'real number')
output_graph_def = tf.compat.v1.graph_util.convert_variables_to_constants( # 模型持久化,将变量值固定
sess,
sess.graph_def,
['y_pred'] # 如果有多个输出节点,以逗号隔开
)
with tf.gfile.GFile("model/mnist.pb", "wb") as f: # 保存模型
f.write(output_graph_def.SerializeToString())
然后将训练好的pb文件转换为mnn能够识别的格式
./MNNConvert -f TF --modelFile mnist.pb --MNNModel mnist.mnn --bizCode biz
MNNConvert具体的转换参数参见官方.
五. Unity侧Wrap接口
官方Demo提供了一个java表面的wrap接口, 我们这里为了在Unity引擎的实现同样的效果, 封装了一套c#的Wrap接口。 具体参见 MnnApi.cs
对应的在c++侧实现一套和c#对接的接口, mnistnative.cpp 并通过cmakelist, 将c++侧的接口编译成so, 导入到Unity的Plugins目录
#include <android/bitmap.h>
#include <jni.h>
#include <string>
#include <MNN/ImageProcess.hpp>
#include <MNN/Interpreter.hpp>
#include <MNN/Tensor.hpp>
#include <memory>
#include <vector>
#include <android/log.h>
#define LOG_TAG "JNI.out"
#define LOGI(...) __android_log_print(ANDROID_LOG_INFO, LOG_TAG, __VA_ARGS__)
extern "C" JNIEXPORT void *JNICALL nativeCreateNetFromFile(const char *modelName) {
auto interpreter = MNN::Interpreter::createFromFile(modelName);
return interpreter;
}
extern "C" JNIEXPORT int JNICALL nativeReleaseNet(void *netPtr) {
if (nullptr == netPtr) return 0;
delete ((MNN::Interpreter *) netPtr);
return 0;
}
extern "C" JNIEXPORT int JNICALL nativeCreateSess(void *netPtr, int forwardType, int numThread,
int &saveSize, int &outputSize) {
LOGI("nativeCreateSess forward, %d, numthread: %d ", forwardType, numThread);
return forwardType + 1;
}
extern "C" JNIEXPORT void *JNICALL nativeCreateSession(void *netPtr, int forwardType, int numThread,
std::string *jsaveTensors, int &saveSize,
std::string *joutputTensors, int &outputSize) {
MNN::ScheduleConfig config;
config.type = (MNNForwardType) forwardType;
if (numThread > 0) config.numThread = numThread;
if (jsaveTensors != nullptr) {
int size = saveSize;// env->GetArrayLength(jsaveTensors);
std::vector<std::string> saveNamesVector;
for (int i = 0; i < size; i++) {
std::string nameStr = jsaveTensors[i];
saveNamesVector.push_back(nameStr);
}
config.saveTensors = saveNamesVector;
}
if (joutputTensors != nullptr) {
int size = outputSize;// env->GetArrayLength(joutputTensors);
std::vector<std::string> saveNamesVector;
for (int i = 0; i < size; i++) {
std::string nameStr = joutputTensors[i];
saveNamesVector.push_back(nameStr);
}
config.path.outputs = saveNamesVector;
}
auto session = ((MNN::Interpreter *) netPtr)->createSession(config);
LOGI("nativeCreateSession execute SUCC");
return session;
}
extern "C" JNIEXPORT void JNICALL nativeReleaseSession(void *netPtr, void *sessionPtr) {
auto net = (MNN::Interpreter *) netPtr;
auto session = (MNN::Session *) sessionPtr;
net->releaseSession(session);
}
extern "C" JNIEXPORT int JNICALL nativeRunSession(void *netPtr, void *sessionPtr) {
auto net = (MNN::Interpreter *) netPtr;
auto session = (MNN::Session *) sessionPtr;
LOGI("nativeRunSession:%d, %d",(netPtr== nullptr),(sessionPtr== nullptr));
return net->runSession(session);
}
extern "C" JNIEXPORT int JNICALL
nativeRunSessionWithCallback(void *netPtr, void *sessionPtr, std::string *nameArray, int &nameSize,
void **tensoraddrs, int &tensorSize) {
if (tensorSize < nameSize) MNN_ERROR("tensor array not enough!");
std::vector<std::string> nameVector;
for (int i = 0; i < nameSize; i++) {
std::string nameStr = nameArray[i];
nameVector.push_back(nameStr);
}
MNN::TensorCallBack beforeCallBack = [&](const std::vector<MNN::Tensor *> &ntensors,
const std::string &opName) {
return true;
};
MNN::TensorCallBack AfterCallBack = [&](const std::vector<MNN::Tensor *> &ntensors,
const std::string &opName) {
for (int i = 0; i < nameVector.size(); i++) {
if (nameVector.at(i) == opName) {
auto ntensor = ntensors[0];
auto outputTensorUser = new MNN::Tensor(ntensor, MNN::Tensor::TENSORFLOW);
ntensor->copyToHostTensor(outputTensorUser);
tensoraddrs[i] = outputTensorUser;
}
}
return true;
};
auto net = (MNN::Interpreter *) netPtr;
auto session = (MNN::Session *) sessionPtr;
net->runSessionWithCallBack(session, beforeCallBack, AfterCallBack, true);
return 0;
}
extern "C" JNIEXPORT int JNICALL nativeReshapeSession(void *netPtr, void *sessionPtr) {
auto net = (MNN::Interpreter *) netPtr;
auto session = (MNN::Session *) sessionPtr;
net->resizeSession(session);
return 0;
}
extern "C" JNIEXPORT void *JNICALL
nativeGetSessionInput(void *netPtr, void *sessionPtr, const char *name) {
auto net = (MNN::Interpreter *) netPtr;
auto session = (MNN::Session *) sessionPtr;
LOGI("name %s, %d, %ld", name, (name == nullptr), (long) sessionPtr);
if (nullptr == name) {
return net->getSessionInput(session, nullptr);
}
return net->getSessionInput(session, name);
}
extern "C" JNIEXPORT void *
JNICALL nativeGetSessionOutput(void *netPtr, void *sessionPtr, const char *name) {
auto net = (MNN::Interpreter *) netPtr;
auto session = (MNN::Session *) sessionPtr;
if (nullptr == name) {
return net->getSessionOutput(session, nullptr);
}
auto tensor = net->getSessionOutput(session, name);
return tensor;
}
extern "C" JNIEXPORT void JNICALL
nativeReshapeTensor(void *netPtr, void *tensorPtr, int *dims, int dimSize) {
LOGI("nativeReshapeTensor: %d, %d, %d", dims[0], dims[1], dims[2]);
LOGI("dimsize: %d", dimSize);
std::vector<int> dimVector(dimSize);
for (int i = 0; i < dimSize; ++i) {
dimVector[i] = dims[i];
}
auto net = (MNN::Interpreter *) netPtr;
auto tensor = (MNN::Tensor *) tensorPtr;
net->resizeTensor(tensor, dimVector);
}
extern "C" JNIEXPORT void JNICALL
nativeSetInputIntData(void *netPtr, void *tensorPtr, const int *data, int dataSize) {
auto tensor = (MNN::Tensor *) tensorPtr;
for (int i = 0; i < dataSize; ++i) {
tensor->host<int>()[i] = data[i];
}
}
extern "C" JNIEXPORT void JNICALL
nativeSetInputFloatData(void *netPtr, void *tensorPtr, float *data, int dataSize) {
auto tensor = (MNN::Tensor *) tensorPtr;
for (int i = 0; i < dataSize; ++i) {
tensor->host<float>()[i] = data[i];
}
}
extern "C" JNIEXPORT int *JNICALL nativeTensorGetDimensions(void *tensorPtr) {
auto tensor = (MNN::Tensor *) tensorPtr;
auto dimensions = tensor->buffer().dimensions;
int *destDims = new int[dimensions];
for (int i = 0; i < dimensions; ++i) {
destDims[i] = tensor->length(i);
LOGI("dim %d is %d", i, destDims[i]);
}
return destDims;
}
extern "C" JNIEXPORT int JNICALL
nativeTensorGetUINT8Data(void *tensorPtr, unsigned char *destPtr, int &length) {
auto tensor = (MNN::Tensor *) tensorPtr;
if (nullptr == destPtr) return tensor->elementSize();
std::unique_ptr<MNN::Tensor> hostTensor;
if (tensor->host<int>() == nullptr) {
// GPU buffer
hostTensor.reset(new MNN::Tensor(tensor, tensor->getDimensionType(), true));
tensor->copyToHostTensor(hostTensor.get());
tensor = hostTensor.get();
}
auto size = tensor->elementSize();
if (length < size) {
MNN_ERROR("Can't copy buffer, length no enough");
return JNI_FALSE;
}
::memcpy(destPtr, tensor->host<uint8_t>(), size * sizeof(uint8_t));
// env->ReleaseByteArrayElements(jdest, destPtr, 0);
return JNI_TRUE;
}
extern "C" JNIEXPORT int JNICALL nativeTensorGetIntData(void *tensorPtr) {
auto tensor = (MNN::Tensor *) tensorPtr;
std::unique_ptr<MNN::Tensor> hostTensor;
if (tensor->host<int>() == nullptr) {
// GPU buffer
hostTensor.reset(new MNN::Tensor(tensor, tensor->getDimensionType(), true));
tensor->copyToHostTensor(hostTensor.get());
tensor = hostTensor.get();
}
int* t= tensor->host<int>();
LOGI("RESULT: %d", t[0]);
return t[0];
}
extern "C" JNIEXPORT int JNICALL nativeTensorGetData(void *tensorPtr, float *dest, int length) {
auto tensor = reinterpret_cast<MNN::Tensor *>(tensorPtr);
LOGI("nativeTensorGetData %d",(dest == nullptr));
if (nullptr == dest) {
std::unique_ptr<MNN::Tensor> hostTensor(
new MNN::Tensor(tensor, tensor->getDimensionType(), false));
return hostTensor->elementSize();
}
std::unique_ptr<MNN::Tensor> hostTensor(
new MNN::Tensor(tensor, tensor->getDimensionType(), true));
tensor->copyToHostTensor(hostTensor.get());
tensor = hostTensor.get();
auto size = tensor->elementSize();
if (length < size) {
MNN_ERROR("Can't copy buffer, length no enough");
return JNI_FALSE;
}
::memcpy(dest, tensor->host<float>(), size * sizeof(float));
LOGI("result0 %f", dest[0]);
return JNI_TRUE;
}
extern "C" JNIEXPORT bool JNICALL
nativeConvertBufferToTensor(void *bufferData, int width, int height,int format, void *tensorPtr) {
if (bufferData == nullptr) {
MNN_ERROR("Error Buffer Null!\n");
return JNI_FALSE;
}
MNN::CV::ImageProcess::Config config;
config.destFormat = (MNN::CV::ImageFormat) format;
config.sourceFormat = (MNN::CV::ImageFormat) format;
std::unique_ptr<MNN::CV::ImageProcess> process(MNN::CV::ImageProcess::create(config));
auto tensor = (MNN::Tensor *) tensorPtr;
process->convert((const unsigned char *) bufferData, width, height, 0, tensor);
return JNI_TRUE;
}
将上述代码编译成libmnistcore.so, 并将对应的依赖的so同样copy到Plugins目录
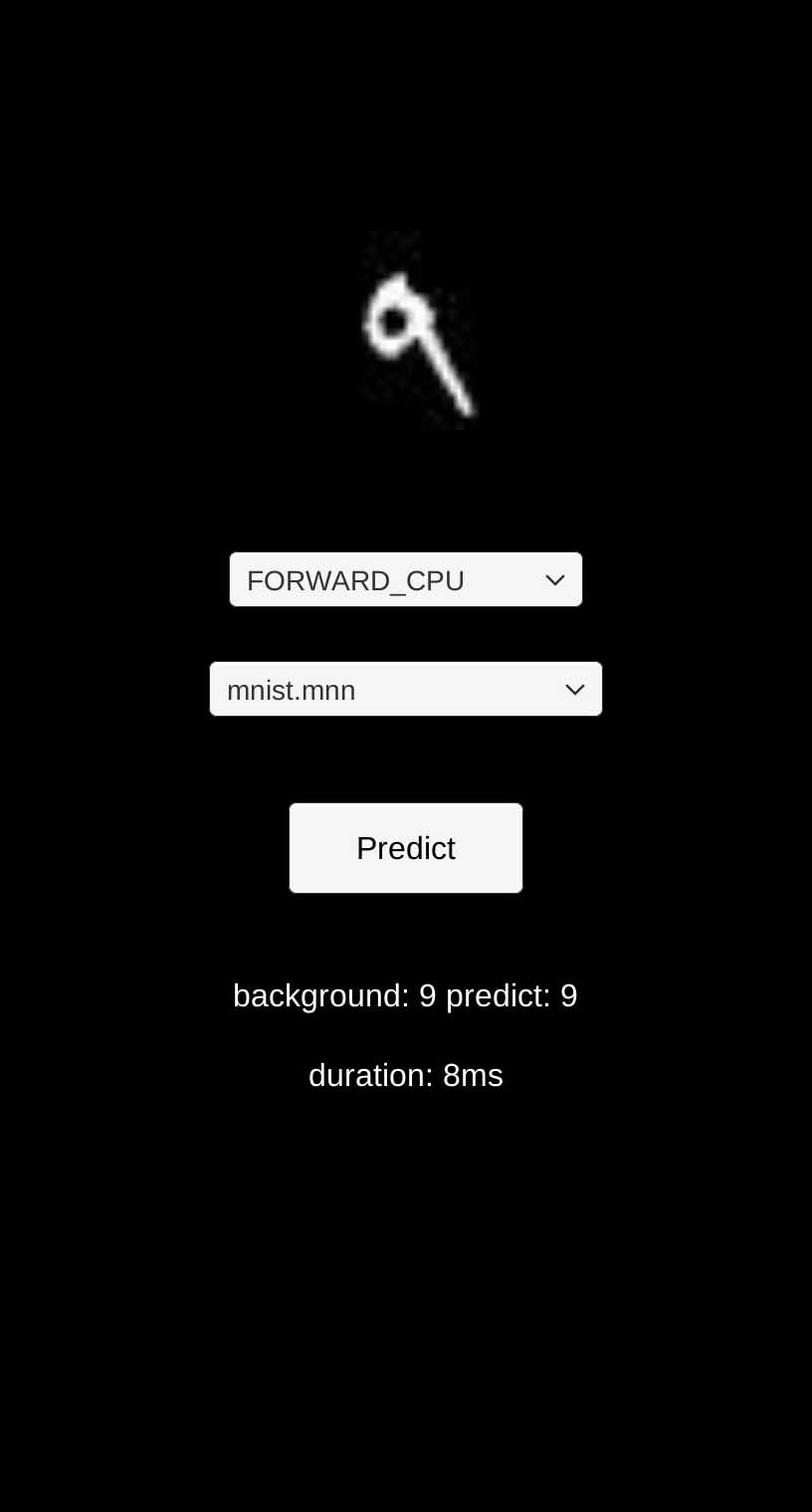
导出apk的时候, 需要将打包方式选择IL2CPP, 然后字在手机上运行得到的结果如下图, 不断的点击Predict来切换数据集的图片, ai运行和记录的标签对比:
相应的代码已经上传到 Github
六. 华为NPU的支持
在编译libMNN的时候放开宏 -DMNN_NPU:BOOL=true , 然后运行时选择backend方式MNN_FORWARD_USER_0,同时拷贝hiai的依赖库拷贝到Plugins目录下, 就可以麒麟芯片NPU上运行了。
具体的操作步骤参见官方