高性能加速计算-Neon
最近在AR开发的时候, 使用需要将camera的预览流传递到算法(c++), 算法要求的图像结构是RGB24排列的图像。 由于Unity侧获取的图像还是xy倒置的, 一开始的处理获取webcameratexture之后, 通过blit 一个材质, 材质在uv采样的时候进行翻转, 并离线输出到一张RGB24的RT上。 但由于每一帧都存在着一次这样额外的CPU和GPU切换, 在P30Pro的这样的机器上耗时大概18ms, 太长了。 于是就考虑在CPU上使用Neon直接处理webcamera的图像, 最终在android里使用neon指令, 整个过程降低到6ms, 整体时间减少了2/3(tip: CPU的算力在某些方面终于强过GPU了)。
说到Neon, 就不得不提到 SIMD. 通常我们进行多媒体处理的时候,很多的数据都是16位或者8位的,如果这些程序运行在32位的机器上,那么计算机有一部分的计算单元是没有工作的, 所以这是一种浪费。 为了更好的使用那些被浪费的资源, SIMD就应运而生了。 SIMD这种技术就是使用一条指令,但对多个相同类型和尺寸的数据进行并行处理,就像我们现实生活中的好几个人都在做同一件事情那样,这样就可以将速度提升很多倍。
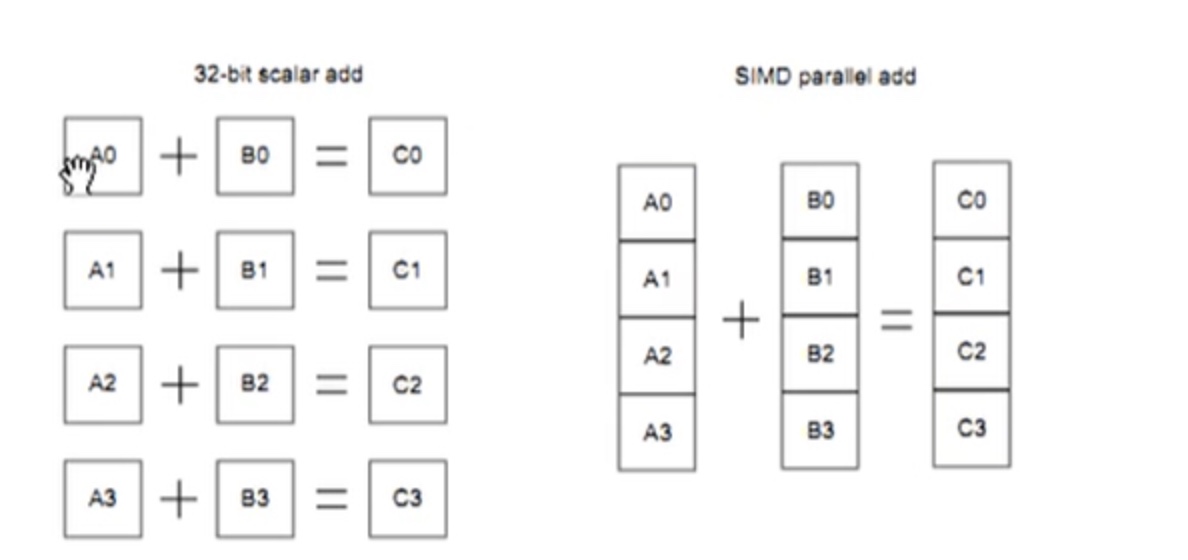
Neon是适用于ARM Cortex-A系列处理器的一种128位SIMD(Single Instruction, Multiple Data,单指令、多数据)扩展结构。NEON技术与Cortex-A8和Cortex-A9处理器相结合,已经被许多领先企业广泛采用。越来越多的机构正在IP设计中采用NEON技术,或提供为NEON技术优化的软件,构成了NEON生态系统的一部分。NEON 技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成),其性能至少为 ARMv5 性能的3倍,为ARMv6 SIMD性能的2倍。
Neon为什么速度快, 原因有以下几条:
- Neon有32个128bit寄存器,能够输入多行的数据同时操作
- CPU运算比加载数据快,速度瓶颈在加载数据这里。可以操作多种数据类型,包括浮点数
- 基于位和字节向量操作,避免了拆解字节的耗费
- Neon基于SIMD,一条指令操作多个数据,对多个数据项同时执行相同的操作。这些数据项在较大的寄存器中打包为单独的通道
1. Burst
Burst是一个编译器,它使用LLVM将IL/.NET字节码转换为高度优化的本机代码。它作为Unity包发布,并使用Unity Package Manager集成到Unity中。它既能与Unity DOTS一起生成高优化代码,又能作为单独的功能使用。最近发布的新版本 Unity Burst 1.5 重点添加了多条 Neon intrinsics 指令。Neon intrinsics 指令支持精确设定矢量命令,为 Arm CPU 的处理进程生成最为高效代码。新指令的效果立竿见影,其中一项优化甚至能让 Burst 代码比结构精巧的非 Burst 代码快 6 倍,让手动编写的 Neon 代码快 10 倍。Neon 指令集传统上只适用于 C/C++ 语言,而 Unity 目前已成功将其移植到了 C# 中。
Burst主要用于与Job系统高效协作, 通过使用属性[BurstCompile]装饰Job结构,从而在代码中简单地使用burst编译器
using Unity.Burst;
using Unity.Jobs;
using UnityEngine;
public class MyBurst2Behavior : MonoBehaviour
{
void Start()
{
var input = new NativeArray<float>(10, Allocator.Persistent);
var output = new NativeArray<float>(1, Allocator.Persistent);
for (int i = 0; i < input.Length; i++)
input[i] = 1.0f * i;
var job = new MyJob
{
Input = input,
Output = output
};
job.Schedule().Complete();
Debug.Log("The result of the sum is: " + output[0]);
input.Dispose();
output.Dispose();
}
// Using BurstCompile to compile a Job with burst
// Set CompileSynchronously to true to make sure that the method will not be compiled asynchronously
// but on the first schedule
[BurstCompile(CompileSynchronously = true)]
private struct MyJob : IJob
{
[ReadOnly]
public NativeArray<float> Input;
[WriteOnly]
public NativeArray<float> Output;
public void Execute()
{
float result = 0.0f;
for (int i = 0; i < Input.Length; i++)
{
result += Input[i];
}
Output[0] = result;
}
}
}
默认情况下,在编辑器中,Burst JIT是通过异步来编译job,但在上面的示例中,我们使用该选项CompileSynchronously = true确保在第一个Schedule中编译该方法。通常,您应该使用异步编译。见[BurstCompile]选项
从“Jobs”菜单中,您可以打开Burst 属性面板。属性面板允许您查看可以编译的所有作业,然后您还可以检查生成的本机代码
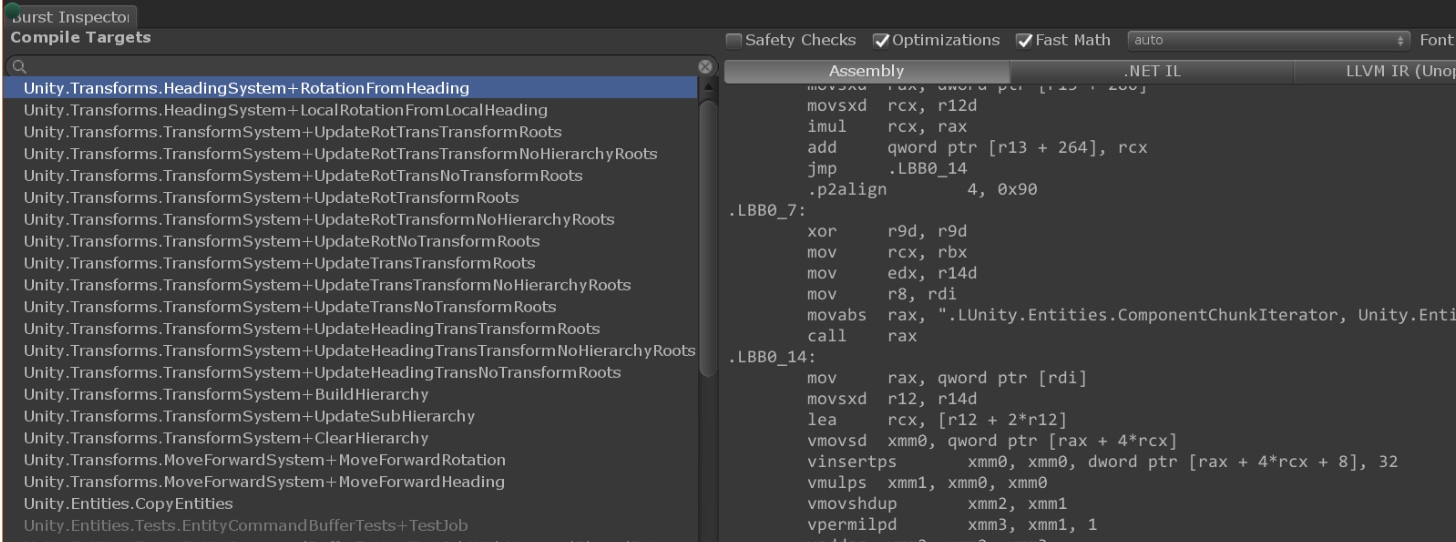
在左侧窗格中,我们有Compile Targets,它提供了一个可以编译的Jobs列表。以白色突出显示的作业可以通过Burst 编译,而禁用的作业则不具有该[BurstCompile]属性。
1.从左窗格中选择一个活动的编译目标。
2.在右窗格中,按“ 刷新反汇编 ”按钮
3.在不同选项卡之间切换以显示详细信息:
- 选项卡程序集(Assembly)提供了由burst生成的最终优化本机代码
- 选项卡 .NET IL 提供了从Job方法中提取的原始.NET IL的视图
- 选项卡LLVM(未优化)在优化之前提供内部LLVM IR的视图。
- 选项卡 LLVM(优化)在优化后提供内部LLVM IR的视图。
- 选项卡LLVM IR Optimization Diagnostics提供优化的详细LLVM诊断(即,如果它们成功或失败)。
切换不同的选项:
如果启用“Safety Checks”将生成包括容器访问安全检查(如检查是否有作业写入本地容器是只读)的代码。
如果启用“Optimizations ”此选项将允许编译器优化代码。
如果启用了“ Fast Math”选项,则编译器可以折叠数学运算以提高效率,但代价是不考虑精确的数学正确性(请参阅编译器放宽选项)。
C#/.NET语言支持
Burst正在研究.NET的一个子集,它不允许在代码中使用任何托管对象/引用类型(C#中的类)。
以下部分提供了更多有关burst实际支持的构造类型详细信息。
支持的.NET类型
原始类型
Burst支持以下原始类型:
bool
char
sbyte/byte
short/ushort
int/uint
long/ulong
float
double
Burst不支持以下类型:
string //因为这是一种托管类型
decimal
矢量类型
Burst能够将矢量类型从Unity.Mathematics原生SIMD矢量类型转换为优化的第一类支持:
bool2/bool3/bool4
uint2/uint3/uint4
int2/int3/int4
float2/float3/float4
请注意,出于性能原因,应首选4种wide 类型(float4,int4…)
枚举类型
Burst支持所有枚举,包括具有特定存储类型的枚举(例如public enum MyEnum : short)
Burst目前不支持Enum方法(例如Enum.HasFlag)
结构类型
Burst支持具有支持类型的任何字段的常规结构。
Burst支持固定数组字段。
关于布局,LayoutKind.Sequential和LayoutKind.Explicit都受到支持,该StructLayout.Pack包装尺寸不支持
本机支持System.IntPtr和UIntPtr作为直接表示指针的内部结构。
指针类型
Burst支持任何Burst支持类型的指针类型
通用类型
Burst支持结构使用的泛型类型。具体来说,它支持对具有接口约束的泛型类型的泛型调用的完全实例化(例如,当具有通用参数的结构需要实现接口时)
数组类型
Burst不支持托管阵列。例如,您应该使用本机容器NativeArray
Burst缺陷
经过一番使用, 发现Burst缺少太多的指令集, 比如说图像处理的所有交错加载多个128位寄存器的指令都没有, 只有一些 vld 或者 vld1q, 也就是一次只能操纵一个寄存器, 这太不友好了, 大大降低了neon的使用场景。
// 连续交错加载3个寄存器 int32_t
vld3q_s32
// 连续交错加载3个寄存器 uint32_t
vld3q_u32
// 连续交错加载3个寄存器 float
vdl3q_f32
// 连续交错加载4个寄存器 uint8
vld4q_u8
// 连续交错加载4个寄存器 int32_t
vld4q_s32
// 连续交错加载4个寄存器 float
vld4q_f32
// 连续交错加载2个寄存器 float
vld2q_f32
// 连续交错加载2个寄存器 int32_t
vld2q_s32
// 连续交错加载2个寄存器 uint8
vld2q_u8
这些指令在图像处理,特别是分离RGBA通道单独计算非常重要, 却官方却没有实现, 这在平时运算的时候, 很多算法需要绕来绕去, 还不一定绕的过去。
还有一些指令虽然只有声明, 却没有实现, 直接抛出一个异常:
比如说
作者使用的Unity版本是2020, 默认使用的1.6.6版本, 却没有基础的存储指令, 升级了1.7.x之后, 才发现其中的实现。
// 所有的 vst 存储都没有实现
vst3q_u8
vst3q_s32
vst1q_u8
vst1q_s32
vst1q_f32
vst4q_s32
vst4q_u8
Burst里的数据结构也比较有限, 其使用了 v64, v128, v256代表了本来在c里面使用的 uint8x8, int32x2, uint8x4x2 之类的数据结构, 由于其没有实现 vld4q_u8 这样的指令, 所以也不会有类似的 uint8x16x4_t 这样数据, 在burst的 NEON_AArch64.cs 这个类中 没有一个方法有 v256 (等价于 uint8x16x4)的参数或者返回值。
总体来说, Burst的 Neon intrinsics 还是一个比较低阶的实现, 绝大多数指令都没有相关的实现, 如果真的使用 Burst来写复杂的算法, 实现的实现会出现各种掣肘,估计unity跨平台的原因<具体已不可考> 希望在之后的Burst的版本能快速的完善。 Unity之所以能做到支持Neon, 本质原因还是因为c#是支持JIT( Just-in-Time ), c# 代码不是一步到位编译成机器码。 在c#里使用的好处就是 Unity帮处理了多个平台适配的情况, 具体有:X86_SSE2, X86_SSE3, X86_SSE4, AVX, AVX2, WASM32, ARMV7A_NEON32, ARMV8A_64, THUMB2_NEON32, ARMV8A_AARCH64_HALFFP等。
NDK
由于Burst里的neon 是残缺版本的, 于是就想到直接在c++(Android NDK)里直接使用neon, 经过使用发现这个比在c# 好用多了, intrinsics 支持的也很完整。 实现完整个算法, 打包生成一个so, 然后集成到Unity的Plugins目录里, 就可以直接调用了。
包含把相关的头文件引用到项目, 这里建议直接在Android Studio里开发, 而不是使用visual studio开发标准的c++程序, 否则的话, 就不会找到相关的库:
#include <arm_neon.h>
这里处理 RGBA32 -> RGB24, 该函数的实现用到了两个NEON Intrinsics,分别是vld4q_u8和vst3q_u8
void hw_rgba2rgb_with_neon(const uint8_t *rgba_img, uint8_t *rgb_img,
int32_t height, int32_t width) {
const int total_pixels = height * width;
const int stride_pixels = 16;
for (int i = 0; i < total_pixels; i += stride_pixels) {
const uint8_t *src = rgba_img + i * SRC_CHANNELS;
uint8_t *dst = rgb_img + i * DST_CHANNELS;
uint8x16x4_t a = vld4q_u8(src);
uint8x16x3_t b;
b.val[0] = a.val[0];
b.val[1] = a.val[1];
b.val[2] = a.val[2];
vst3q_u8(dst, b);
}
}
vld4q_u8的函数原型为uint8x16x4_t vld4q_u8 (const uint8_t * __a),作用为以步长为 4 交叉地加载数据到四个连续的 128-bit 的向量寄存器。
s具体地:将内存地址__a、__a+4、…、__a+60处的内容分别赋值给向量寄存器Vn的lane[0]、lane[1]、…、lane[15],将内存地址__a+1、__a+5、…、__a+61处的内容分别赋值给向量寄存器Vn+1的lane[0]、lane[1]、…、lane[15],将内存地址__a+2、__a+6、…、__a+62处的内容分别赋值给向量寄存器Vn+2的lane[0]、lane[1]、…、lane[15],将内存地址__a+3、__a+7、…、__a+63处的内容分别赋值给向量寄存器Vn+3的lane[0]、lane[1]、…、lane[15]。也就是说,vld4q_u8在上述函数中的作用为:将连续 16 个像素的 R 通道: R0、R1、… 、R15 加载到向量寄存器Vn,将连续 16 个像素的 G 通道: G0、G1、… 、G15 加载到向量寄存器Vn+1,将连续 16 个像素的 B 通道: B0、B1、… 、B15 加载到向量寄存器Vn+2,将连续 16 个像素的 Alpha 通道: A0、A1、… 、A15 加载到向量寄存器Vn+3。
vst3q_u8的函数原型为void vst3q_u8 (uint8_t * __a, uint8x16x3_t val),作用为以步长为 3 交叉地存储数据到内存中。
由于每一次迭代可以同时处理 16 个连续的像素。所以,变量stride_pixels的值为 16。
内联汇编
优点:在C代码中嵌入汇编,调用简单,无需手动存储寄存器;
缺点:有较为复杂的格式需要事先学习,不好移植到其他语言环境。
//add for int array. assumed that count is multiple of 4
#include<arm_neon.h>
// C version void add_int_c(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i++)
dst[i] = src1[i] + src2[i];
}
}
// NEON version void add_float_neon1(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i += 4)
{
int32x4_t in1, in2, out;
in1 = vld1q_s32(src1);
src1 += 4;
in2 = vld1q_s32(src2);
src2 += 4;
out = vaddq_s32(in1, in2);
vst1q_s32(dst, out);
dst += 4;
}
}
比如上述intrinsics代码产生的汇编代码为:
// ARMv7-A/AArch32
void add_float_neon2(int* dst, int* src1, int* src2, int count)
{
asm volatile (
"1: \n"
"vld1.32 {q0}, [%[src1]]! \n"
"vld1.32 {q1}, [%[src2]]! \n"
"vadd.f32 q0, q0, q1 \n"
"subs %[count], %[count], #4 \n"
"vst1.32 {q0}, [%[dst]]! \n"
"bgt 1b \n"
: [dst] "+r" (dst)
: [src1] "r" (src1), [src2] "r" (src2), [count] "r" (count)
: "memory", "q0", "q1"
);
}
运行时查看当前设备是否支持neon, 可以通过cpu-features里获取cpu信息,主要是获取cpu类型和相关的标识位:
#include <cpu-features.h>
bool isSupportNeon()
{
auto family = android_getCpuFamily();
return (family == ANDROID_CPU_FAMILY_ARM || family == ANDROID_CPU_FAMILY_ARM64) &&
(android_getCpuFeatures() & ANDROID_CPU_ARM_FEATURE_NEON) != 0;
}
为了使 cpu-features 生效, CMakeLists.txt需要做如下调整:
add_library( # Sets the name of the library.
cam-turbo
# Sets the library as a shared library.
SHARED
${ANDROID_NDK}/sources/android/cpufeatures/cpu-features.c
img_neon.cpp
native-lib.cpp )
target_include_directories(cam-turbo PRIVATE ${ANDROID_NDK}/sources/android/cpufeatures)
编译
编译的时候, 为模块(库)启用 NEON, 如果使用cmakelist编译, 可以这样配置:
set_target_properties(${TARGET} PROPERTIES COMPILE_FLAGS -mfpu=neon)
NEON 在 ndk-build 模块中构建所有源文件,请将以下内容添加到 Android.mk 的模块定义中:
LOCAL_ARM_NEON := true
除此之外, 还支持为某些cpp文件单独支持NEON, 例如cmakelist可以这样配置, 下面的foo.cpp就支持neon了:
set_source_files_properties(foo.cpp PROPERTIES COMPILE_FLAGS -mfpu=neon)
mdk-build 使用ANdroid.mk 方式如下:
LOCAL_SRC_FILES := foo.c.neon bar.c
为 LOCAL_SRC_FILES 变量列出源文件时,可以选择使用 .neon 后缀表示要构建支持 Neon 的单个文件。例如,以下示例会构建一个支持 Neon 的文件 (foo.c),以及另一个不支持 Neon 的文件 (bar.c), 您可结合使用 .neon 后缀与 .arm 后缀,后者指定用于非 Neon 指令的 32 位 ARM 指令集(而非 Thumb2)。在这种情况下,.arm 必须在 .neon 之前。例如:foo.c.arm.neon 可行,但 foo.c.neon.arm 不可行。
参考文献: