Shader中的偏阶导数
偏导数函数(HLSL中的ddx和ddy,GLSL中的dFdx和dFdy)是片元着色器中的一个用于计算任何变量基于屏幕空间坐标的变化率的指令(函数)。在WebGL中,使用的是dFdx和dFdy,还有另外一个函数fwidth = dFdx + dFdy。
偏导数计算
在三角形栅格化期间,GPU会同时跑片元着色器的多个实例,但并不是一个pixel一个pixel去执行的,而是将其组织在2x2的一组pixels块中并行执行。偏导数就是通过像素块中的变量的差值(变化率)而计算出来的。dFdx表示的是像素块中右边像素的值减去素块中左边像素的值,而dFdy表示的是下面像素的值减去上面像素的值。如下图所示,图中显示的是渲染的屏幕像素,图中红色区域是一个像素块,p(x,y)表示在屏幕空间坐标系中坐标(x,y)的片元(像素)上的某一个变量,图中显示了dFdx和dFdy的计算过程。
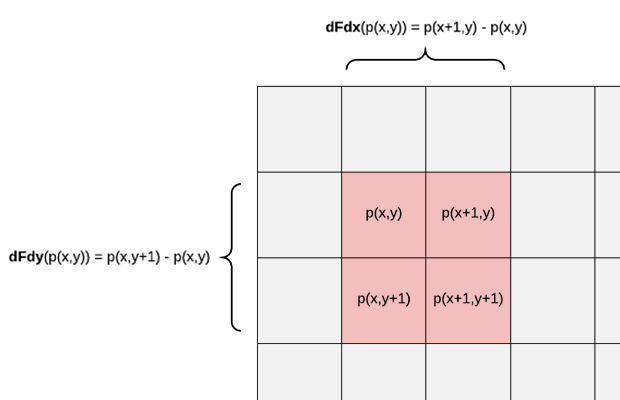
偏导数函数可以用于片元着色器中的任何变量。对于向量和矩阵类型的变量,该函数会计算变量的每一个元素的偏导数。
要注意的是,不论HLSL还是GLSL中,偏导函数都只能在fragment shader阶段处理,因为它是求不同 fragment 的 val 差值
偏导数函数是纹理mipmaps实现的基础,也能实现一系列算法和效果,特别是哪些依赖于屏幕空间坐标的(比如渲染统一线宽的线框参考我的另外一篇文章:https://www.jianshu.com/p/1a0979a2d972)
mipmaps
Mipmaps用于计算纹理的一些列的子图,每个子图都比前一个的尺寸缩小了2倍。 他们用于在纹理缩小(纹理映射到比自身尺寸小的表面)的时候的去锯齿。

Mipmaps 对于纹理缓存的一致性也很重要,在遍历一个三角形(的片元)的时候,它会强制获取一个最近的像素比例:这个比例保证三角形上的一个像素尽量对应纹理上的一个像素。 Mipmaps是可以同时可视化效果和性能的少数技术之一。
在纹理取样过程中使用偏导数来选择最佳的 mipmap 级数。纹理坐标在屏幕空间中的变化率作为选择mimmap级数的依据,变化率越大,mimap级数越大,反之越小。使用Mipmap就能解决这个问题,整个texture大小为原来的1.33倍,选择合适的level,这样尽可能让pixel和texel一一对应(同时也能减少Cache Miss)。
注:w是3D贴图的第三个坐标轴,对于2D贴图,∂w/∂x和∂w/∂y为0
∂u/∂x是u对x的偏微分(也就是u沿x轴的变化率),即ddx(u),可以理解成当屏幕像 素沿x轴变换一个单位时,贴图沿u方向变化了几个单位.
面的法线向量计算(flat shader)
偏导数函数可以用来在片元着色器中计算当前面(三角形)的法线向量。当前片元的世界坐标系的水平偏导数和垂直偏导数是两个三角形表面上的两个向量,它们的叉乘结果是一个垂直于表面的向量,该向量的归一化结果就是面的法线向量。需要特别注意的是两个向量的叉乘的顺序。
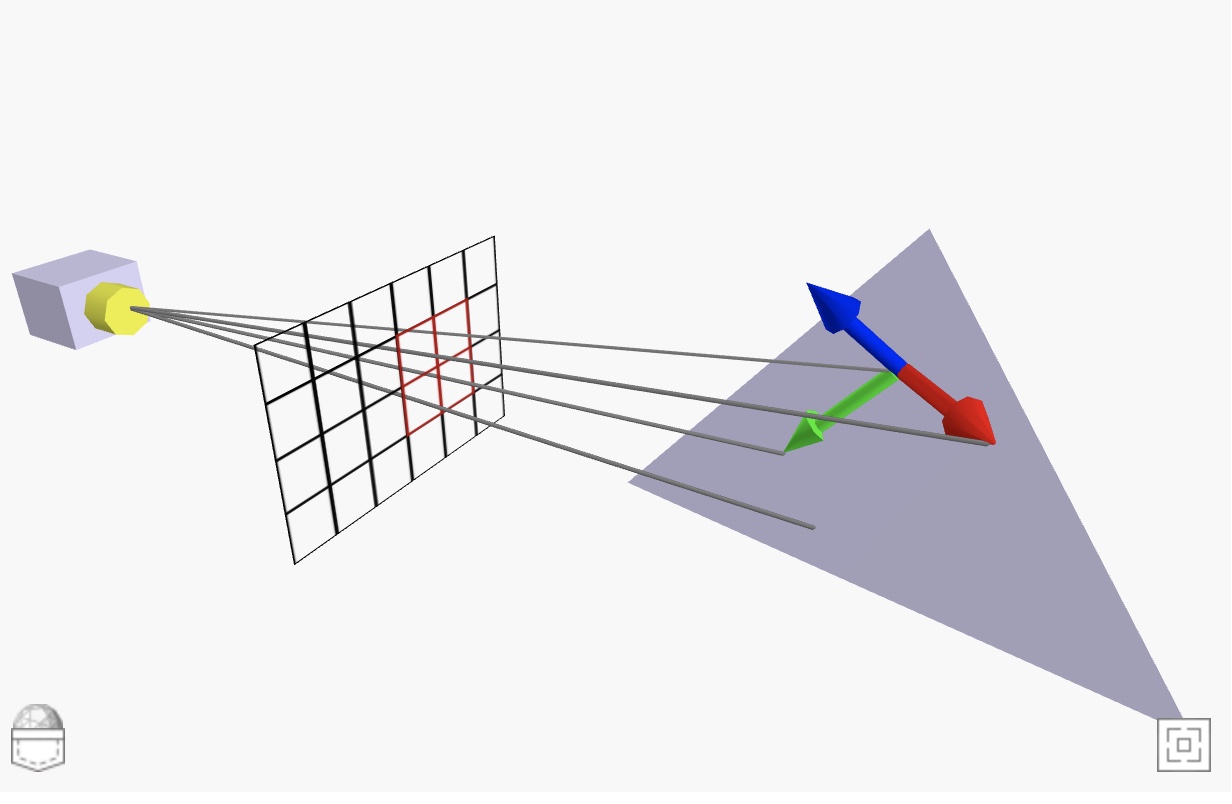
下面是GLSL中通过镜头坐标系中坐标计算面法线向量的代码:
normalize(cross(dFdx(pos), dFdy(pos)));
Tip:有点儿类似 ShaderToy 上 Raymarch 对sdf距离场的法线求解算法。 上面的pos不一定是屏幕空间的, 也可以是模型空间 或者世界空间, 得到对应的法线也即对应的坐标空间。 和 SDF求解法线不同的是, 此方法由于是基于三角面的定点位置, 所以法线看起来都是面, 而基于SDF距离公式计算出来的形状就丝滑很多了。
分支处理
分支计算基于在 GPU 硬件上并行执行着色器的多个实例。标量运算在寄存器上使用 SIMD(单指令多数据)架构执行,寄存器包含 4 个值的向量,用于 2×2 像素的块。这意味着在执行的每一步中,属于每个2×2块的着色器实例都是同步的,使得衍生计算快速且易于在硬件中实现,这是对同一寄存器中包含的值的简单减法。
但是,在条件分支的情况下会发生什么呢?在这种情况下,如果不是核心中的所有线程都采用相同的分支,则代码执行中存在差异。在下图中显示了一个发散示例:在具有 8 个着色器实例的 GPU 核心中执行条件分支。三个实例采用第一个分支(黄色)。在黄色分支执行期间,其他 5 个实例处于非活动状态(执行位掩码用于激活/停用执行)。在黄色分支之后,执行掩码将反转,蓝色分支由其余 5 个实例执行。
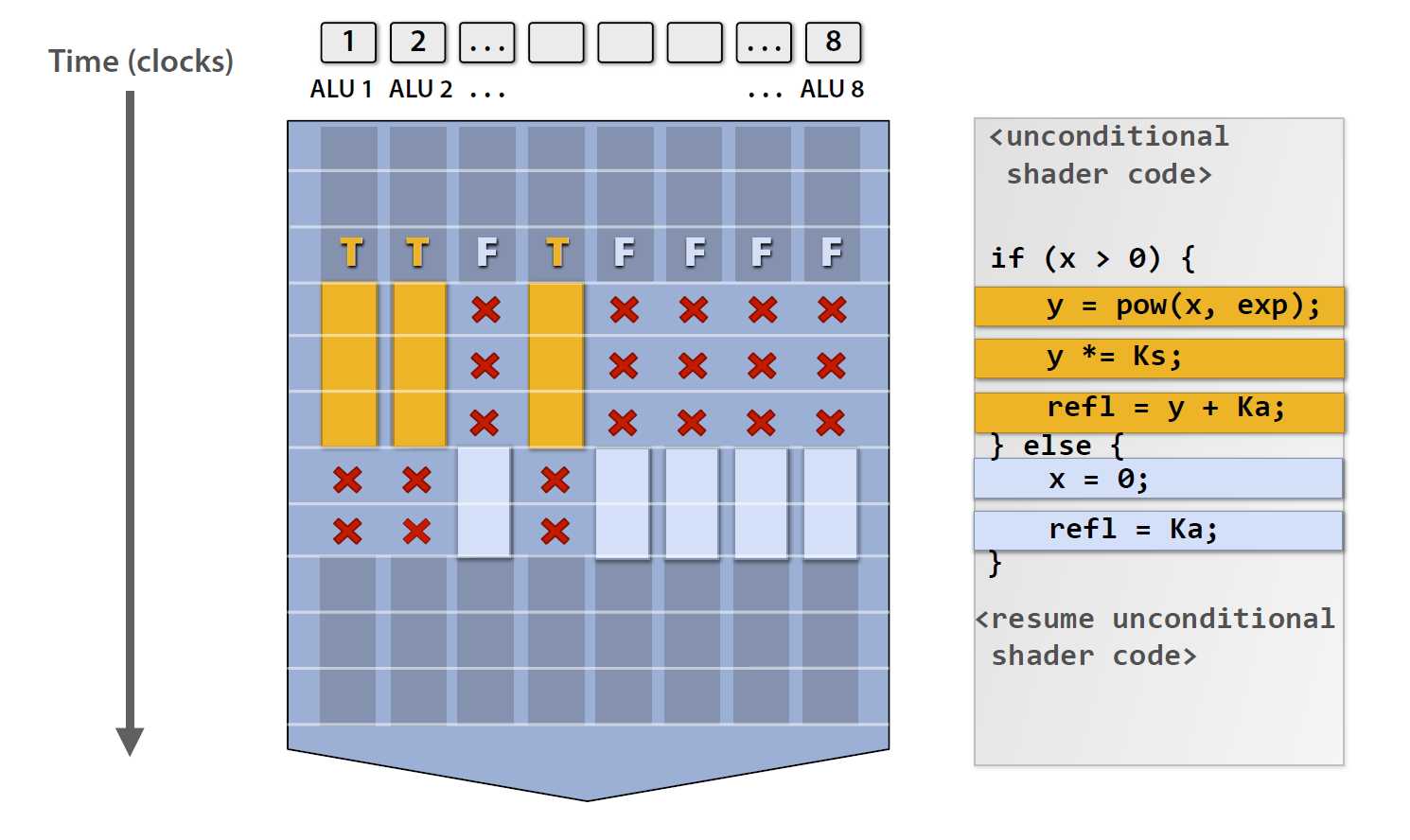
除了分支的效率和性能损失之外,发散还破坏了块中像素之间的同步,使得导数操作未定义。这是纹理采样的一个问题,需要导数进行mipmap电平选择,各向异性过滤等。当遇到这样的问题时,着色器编译器可以平展分支(从而避免它),或者尝试重新排列在分支控制流外部移动纹理读取的代码。通过在对纹理进行采样时使用显式导数或 mipmap 级别,可以避免此问题。
您可以在下面看到使用自定义表达式节点在UE4中编写的HLSL分支实验。
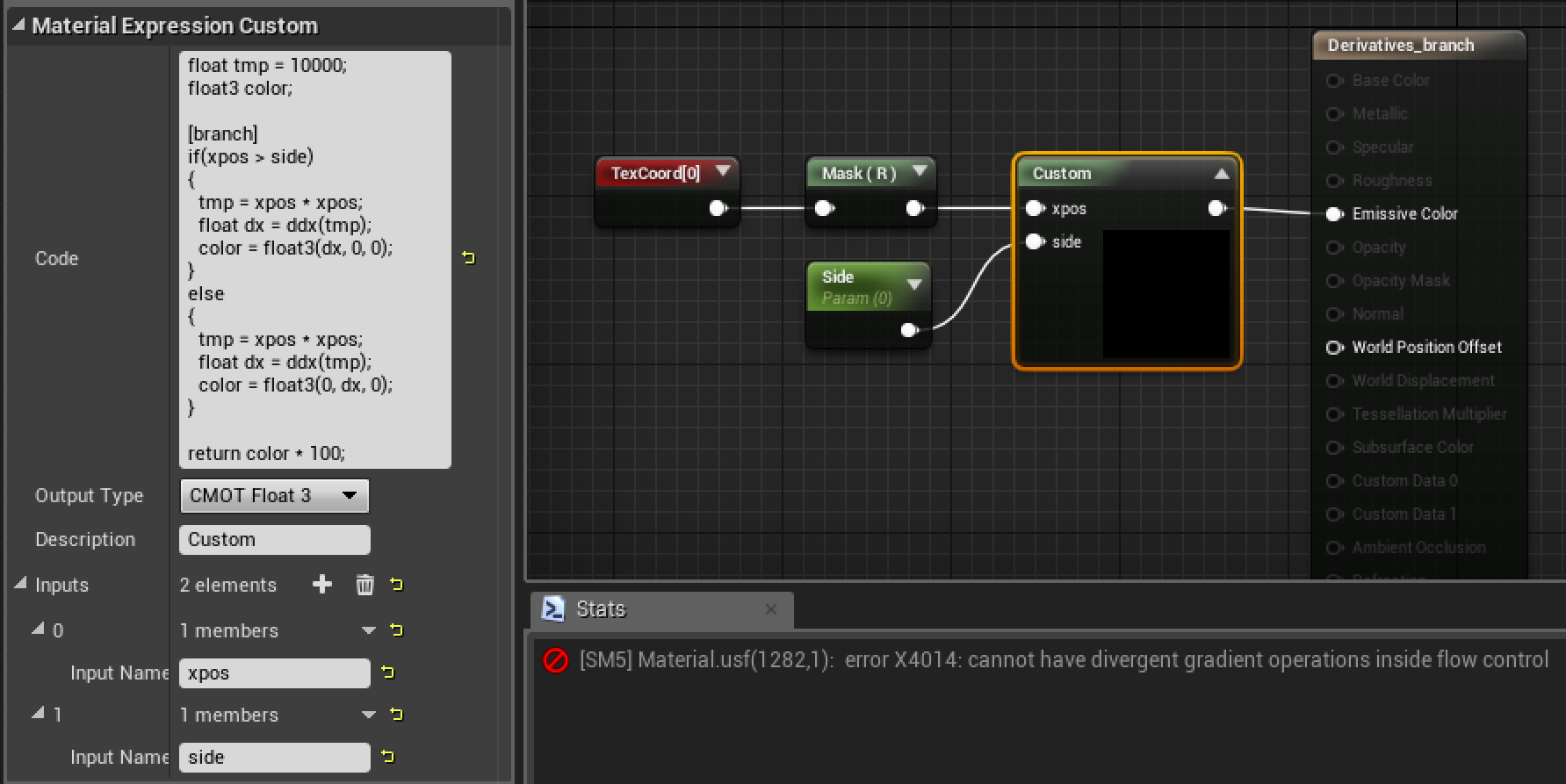
下面是我在前面的示例中使用的着色器代码:
float tmp = 10000;
float3 color;
[branch]
if(xpos > side)
{
tmp = xpos * xpos;
float dx = ddx(tmp);
color = float3(dx, 0, 0);
}
else
{
tmp = xpos * xpos;
float dx = ddx(tmp);
color = float3(0, dx, 0);
}
return color * 100;
这个实验的目的是看看当在发散块内使用导数时会发生什么。假设上述代码在 GPU 内核上执行。当块中像素的子集进入第一个分支时,等待第二个分支执行的非活动像素的值仍应为 10000。因此,该函数应该为发散块上的某些像素提供峰值。[branch]是告诉编译器这段代码严格按照if的逻辑流程,执行时只运行一个分支的代码,另一个分支的代码不执行。 相对的是[flatten],告诉GPU这段代码true和false的代码都执行,最后只在输出时选取true分支的结果。
如上图所示,编译器为该段代码给出了以下错误:”cannot have divergent gradient operations inside flow control”,但是当删除[branch]属性时,代码编译正常,但在渲染过程中看不到峰值,这意味着编译器默认使用的[flatten]。
分支的块对齐
下面是一个简单的实验,揭示了着色器导数的内部块对齐。
我们想要计算它的导数。阶跃函数的导数将是连续域中的Dirac delta函数,但在着色器的离散域中,当步长从0跳到1时,delta函数将等于1,在其他地方则为0。选中 “Show Derivative” 复选框并切换”Step on odd pix”复选框,将”步进”位置捕捉到视口中心的偶数(未选中)或奇数(选中)像素; 您将看到xdFdx(step)将过渡点从偶数像素移动到奇数像素时如何变化。
由于导数计算是在2×2像素的块上执行的,因此我们应该期望两种不同的结果,具体取决于阶跃转换发生的位置:
-
案例1.如果阶跃过渡落在 2×2 像素块的中间,我们将看到一条厚度为 2 像素的垂直线(2×2 块中每个像素的导数等于 1,因此厚度为 2 像素)。当步骤落在奇数像素上时,会发生这种情况。
-
案例2.阶跃过渡落在两个相邻的 2×2 像素块的中间。在这种情况下,我们不会看到任何垂直线,因为两个块都将计算等于 0 的导数。当步骤落在偶数像素上时,会发生这种情况。
作为练习,尝试修改上述沙箱的着色器代码,以显示水平步进函数和水平导数线。
这些混叠伪影是由导数的硬件每块计算引起的子采样引起的;水平导数具有完全垂直和半水平分辨率,垂直导数具有全水平和半垂直分辨率。
边缘突出
这里使用unity Shader 测试边缘突出的情况
Shader "Test/TestDDXTex"
{
Properties
{
[KeywordEnum(IncreaseEdgeAdj, BrightEdgeAdj)] _EADJ("Edge Adj type", Float) = 0
_Tex("Tex", 2D) = "white" {}
_Intensity("Intensity", Range(0, 20)) = 2
}
SubShader
{
Pass
{
Tags { "RenderType"="Opaque" }
Cull off
Blend SrcAlpha OneMinusSrcAlpha
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile _EADJ_INCREASEEDGEADJ _EADJ_BRIGHTEDGEADJ
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
};
sampler2D _Tex;
float4 _Tex_ST;
float _Intensity;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _Tex);
return o;
}
fixed4 frag (v2f i, float f : VFACE) : SV_Target
{
fixed a = 1;
if (f < 0) a = 0.5;
fixed3 c = tex2D(_Tex, i.uv).rgb;
#if _EADJ_INCREASEEDGEADJ // 边缘调整:增加边缘差异调整
// 类似两个3x3的卷积核处理
/*
one:
| 0| 0| 0|
| 0|-1| 1|
| 0| 0| 0|
two:
| 0| 0| 0|
| 0|-1| 0|
| 0| 1| 0|
*/
//使用(ddx(c) + ddy(c)),没有绝对值,会然边缘的像素亮度差异变大,即:加强边缘突出
c += (ddx(c) + ddy(c)) * _Intensity;
#else //_EADJ_BRIGHTEDGEADJ // 边缘调整:增加边缘亮度调整
//c += abs(ddx(c)) + abs(ddy(c)) *_Intensity;
c += fwidth(c) * _Intensity; // fwidth(c) ==> abs(ddx(c)) + abs(ddy(c))
//使用fwidth函数,可以看出,会是边缘变亮,突出边缘
// fwidth func in HLSL: https://docs.microsoft.com/zh-cn/windows/desktop/direct3dhlsl/dx-graphics-hlsl-fwidth
#endif // end _EADJ_INCREASEEDGEADJ
return fixed4(c, a);
}
ENDCG
}
}
}
在shader中,可以看到有两种方法,对应材质Inspector中的两个选项

IncreaseEdgeAdj=边缘突出-锐化-增加差值;
BrightEdgeAdj=边缘突出-增加亮度

使用(ddx(c) + ddy(c)),没有绝对值,会然边缘的像素亮度差异变大,即:加强边缘突出
边缘突出-增加亮度

fwidth(c ) ==> abs(ddx(c)) + abs(ddy(c))
使用fwidth函数,可以看出,会是边缘变亮,突出边缘