Unity DOTS
Unity 的高性能多线程面向数据的技术堆栈 (DOTS) 充分利用了多核处理器的优势,可创建更加丰富的用户体验。使用它可以更快地迭代和创建易于重用的 C# 代码。
从Cache说起
Cache Miss
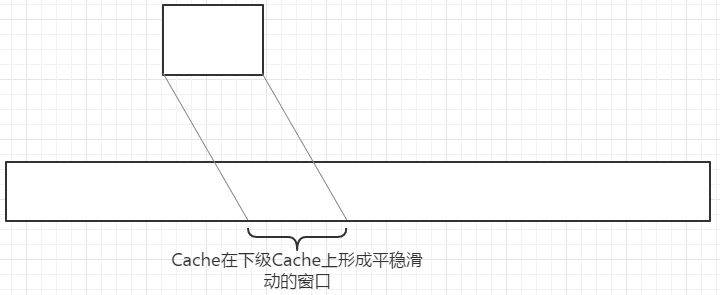
Cache(Cache Memory)作为储存器子系统的组成部分,存放着程序经常使用的指令和数据,是为了缓解访问慢设备的延时而预读的 Buffer,例如 CPU L1/L2/L3 Cache 作为 DDR 内存 IO 的 Cache,而 DDR 内存作为磁盘 IO 的 Cache。当计算需要读取数据的时候,通常从最快得缓存开始依次向下查找,并递归的读取。预读就是用来减少下一次读取的查找层数(每一层的延迟有数量级的差距)的技术。相应的,预读的预测失败的时候将会有非常高的代价,这种情况被称为 Cache Miss。在大部分的情况下,在现代 CPU 的频率带来的运算力下, Cache Miss 比数学运算更容易成为程序的性能瓶颈,且在代码中的表现比较隐晦。这使得一味的讨论复杂度O(n)不再适用,因为现在效率=数据+代码。
Avoid Cache Miss
避免 Cache Miss 的方案当然就是去讨好预读。而一般预读的策略为线性预读,即我们应该尽量的保证数据读写的连续性,从逆向思维出发,则需了解会打断数据连续性的情形。简单的列举几个:遍历大结构体的数组(却只访问少数成员),操作对象引用(OOP),操作数组的顺序不够连续(比如实现得不好的 hash 表),etc。综上所述,避免Cache Miss的主要考量就是尽量使用数组,尽量分割属性(SOA),尽量连续的进行处理。(在 GPU 编程中存在大量实例)
More than Data
前面提到过 Cache 存放着程序经常使用的指令和数据,现代 CPU 在数据 IO 的时候并不会完全的挂起,而是会利用空闲的运算力继续执行后续的指令,且指令也是一种数据,这意味着我们不光要照顾数据的连续性,还需要考虑到指令的连续性,那么什么情况会破坏指令的连续性呢?可能是函数指针(虚函数的调用,回调等),循环超长代码块等。特别是函数指针在 IO 期间,CPU 无事可做,于是在需要高性能的情形下,应该尽量避免虚函数。
Allocation
对于数据而言,还有一个重要的问题就是分配内存。在应用中,不管是分配还是释放都是十分消耗性能的操作,前者可能产生碎片,而后者,(考虑 GC)可能带来停顿,(考虑手动)也可能带来危险和脑力负担,所以一般对于高频分配的部分,会预先分配大块内存用来管理(一般称作池化)。
从 Thread 说起
Multithread
随着处理器核心的发展速度减缓,为了进一步提升处理器的性能,堆叠核心成为了新的出路,甚至现在的处理器没个四核都不好意思见人,其中堆叠核心的巅峰就是 GPU,上千个核心带来了疯狂的数字处理能力,被广泛运用于 AI 和图形领域。而这在游戏之类的高性能软件中,为了充分利用 CPU 的算力,程序设计成多线程运行也是非常必要的。
Race Condition 和 Data Race
不幸的是多线程很多时候不是免费的性能,并不是所有情况都像异步读文件那么简单,在开发过程中,很多地方都可能会有 Race 的发生。同步性问题非常的恶心,因为通常其不会即时造成崩溃之类的错误,而是会积累错误,等到错误爆发,缘由已经很难查询。所以编码的时候就必须要小心翼翼,其中 Race Condition 主要需要我们保证整体操作的原子性,一般的解决方案是一把大锁。Data Race 则更加复杂,触发Data Race的条件可以归纳为:
- 1, 同一个位置的对象。
- 2, 被两个并发的线程操作。
- 3, 两个线程并非都是读。
- 4, 不是原子操作。
只有当这四个条件同时成立的时候,Data Race 才会发生,所以为了避免它的发生,我们需要破坏掉其中的一个或多个条件。对于条件4,可以使用原子操作破坏,然而原子操作的复杂性颇高,实际应用中常用于实现底层库(无锁队列,线程池之类的)。而要破坏条件1、3,则是避免可变共享,完全进行拷贝(如erlang)。剩下条件2就是避免硬碰硬,在可能发生 Data Race 的时候直接放弃并行。但总得来说最重要的还是,要避免它的发生,一定要对这些条件足够敏感以预防遗漏,在这里通常封装就起了反作用,因为黑箱之内我们无法知道会发生什么。而此时相对于 OOP 的黑箱,函数式的纯粹(纯原子性)便能体现出它在并行上天生的优势,所以卡神推荐在 C++ 里也尽量使用函数式的思想来进行编码。
Unity ECS
1. Entity
Entity为ECS中基本的成员,实际上只是由一个Index和一个Version组成(Version只有在Entity被回收后会加1),其实际的Component数据存储在一个Chunk上(Unity ECS特有的数据类型,后面会讲到),需要操作其Component数据时,根据其index到EntityDataManager中找到其所在的Chunk和IndexInChunk,取到对应的Component数据后进行操作。
public struct Entity : IEquatable<Entity>
{
public int Index;
public int Version;
......
}
2. Component
Component是Entity的一个属性,通常是一个继承了IComponentData或ISharedComponentData接口的结构体(两个接口都为空接口,仅标记类型)。一个Entity可以包含多个Component,继承了ISharedComponentData的数据会在多个Entity之间共享,同时可以使用托管类型的成员,一般用来存放GameObject或RenderMesh等渲染相关的成员。
一个Entity的Component可以在CreateEntity时指定,也可以使用一个ArcheType创建或从已有Entity复制来创建。同时已经创建的Entity还可以通过AddComponent和RemoveComponent来动态进行Component的添加或删除(由于效率问题不推荐)。
Tips:Component可以用Proxy包装后直接挂在GameObject上,挂载多个Proxy的GameObject可以作为Prefab直接传入EntityManager.Instantiate来生成新的Entity,如:
// Create an entity from the prefab set on the spawner component.
var prefab = spawnerData.prefab;
var entity = EntityManager.Instantiate(prefab);
3. 块Chunk
Chunk是Unity ECS中特有的一个数据结构,在ECS部分代码中有大量使用,通常是指用来存放Component信息的与ArchetypeChunk,此外还有更一般的Chunk通过ChunkAllocator进行开辟,可以存放ArcheType中的各类型信息,大小和存储结构都与ArchetypeChunk不同,此处的Chunk特指存放ArcheType中Component信息的ArchetypeChunk。Chunk有以下几个特点:
- EntityManager会将Component数据存放在固定的16kb大小的Chunk中(可以在Chunk定义中找到指定大小kChunkSize)
- 每个Chunk结构包含了这个区块中内容的相关信息
- 每个EntityArchetype都包括了一个Chunk的独特集合
- 一个chunk只能存在于一个archetype中
- 一个ArchetypeChunk结构是一个到具体Chunk的指针
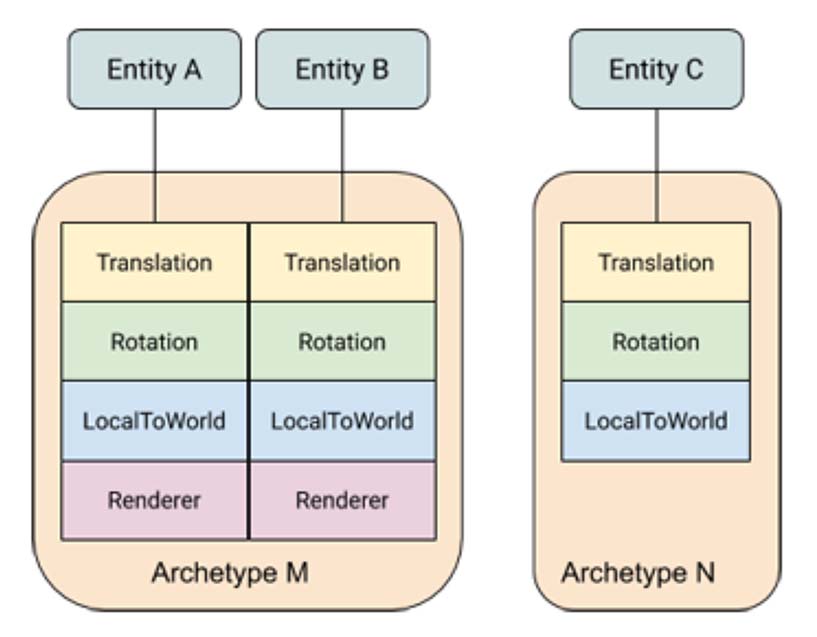
我们有三个实体:
EntityA:包含了Translation、Rotation、LocalToWorld、Render四个组件。
EntityB:包含了Translation、Rotation、LocalToWorld、Render四个组件。
EntityC:包含了Translation、Rotation、LocalToWorld三个组件。
很明显的,EntityA和EntityB拥有的组件是一模一样的。
在ECS中,底层会把这些拥有相同组件的实体放在一起,也就是我们所说的内存块(Chunk)。EntityA和EntityB是放在一个块(Chunk)里的,而EntityC则放在另一个块(Chunk)里。
这涉及到一种”反正我也听不懂”的原理,把相同类型的数据连续存放在一块内存里,会提高提取数据的效率。参考官方文档。
4. 原型Archetype
ArcheType是Unity ECS中特有的概念,也是Unity ECS内存管理中的一个核心部分,许多重要操作都与此相关。ArcheType是由某几个固定Component组成的Entity原型,有以下几个特点:
- ArcheType管理所有属于它的Entity Component数据,对应数据存放在归属于它的chunk上
- 可以通过ArcheType快速访问所有该类型的Entity Component数据
- 拥有Component的Entity一定处在某个ArcheType的管理之下
- ArcheType拥有缓存机制,第二次创建相同的ArcheType时会自动将现有的返回
我们可以使用EntityManager.CreateArchetype(params ComponentType[] types)来主动创建一个ArcheType,通过ArcheType可以直接调用EntityManager.CreateEntity(EntityArchetype archetype)来快速创建具有某一类特征的Entity。同时如果使用直接传入Components的方式来创建Entity时也会自动生成含有对应Component的ArcheType。
5. ComponentSystem
ComponentSystem为System在Unity ECS中的实现。一个ComponentSystem会对含有某些Component的Entity执行一些特定的操作,通常继承自ComponentSystem或JobComponentSystem。区别是继承ComponentSystem只会在主线程执行,而继承自JobComponentSystem的则可以利用JobSystem来进行多线程并发处理,但同时对应操作过程中的限制也更严格。在大部分情况下应当尽量使用JobComponentSystem来完成相关的操作,从而提升性能。
多个不同的ComponentSystem可以在定义时通过UpdateBefore、UpdateAfter、UpdateBefored等标签来控制其执行顺序,这会在一定程度上影响并发执行,通常只在必要时使用。
一个ComponentSystem通常关注一个包含特定的Component组合的Entity集合(称为ComponentGroup。这个ComponentGroup集合可以通过GetComponentGroup主动获取,
ComponentGroup m_Spawners;
//获取包含ObjectSpawner和Position两个Component的ComponentGroup
protected override void OnCreateManager()
{
m_Spawners = GetComponentGroup(typeof(ObjectSpawner), typeof(Position));
}
也可以使用IJobProcessComponentData中的定义和RequireSubtractiveComponentAttribute等标签自动注入(Inject),同样也会生成一个ComponentGroup
//通过RequireComponentTagAttribute为JobComponentSystem添加额外的依赖项
//[RequireComponentTagAttribute(typeof(Object))]
//通过RequireSubtractiveComponentAttribute为JobComponentSystem添加额外的排除项
[RequireSubtractiveComponentAttribute(typeof(ObjectSpawner))]
struct ObjectMove : IJobProcessComponentData<Position>
{
......
public void Execute(ref Position position)
{
......
}
}
常用管理器介绍
Unity ECS中对于不同类型的对象由不同的Manager进行管理,这边对常用的Manager进行一个归纳。
EntityManager
ECS日常使用中使用最频繁的管理器,每个World都会有一个EnitityManager,不直接储存数据,但封装了常用的Enitity、Archetype、Component操作,包括了CreateEntity、CreateArchetype、Instantiate、AddComponent等操作。
同时EntityManager提供了其他多个重要数据管理器的访问接口,包括Entity数据管理器EntityDataManager、原型管理器ArchetypeManager、Component集合管理器EntityGroupManager、以及共享数据管理器SharedComponentDataManager。可以说以EntityManager为入口,可以延伸到ECS系统中90%以上的内容,可谓包罗万象。
ArchetypeManager
管理所有的Archetype的创建、更新、删除等操作,管理了所有当前已创建的Archetype。当需要建立新的ComponentGroup时会到ArchetypeManager中读取所有Archetype的列表m_Archetypes,来筛选需要关注哪些Archetype,同时在Archetype发生变化时也会同时更新对应的ComponentGroup数据。
EntityDataManager
管理所有Entity相关的数据,可以通过m_Entities->ChunkData快速根据Entity Index获得Entity所在的Chunk和在该Chunk上的Index,从m_Entities->Archetype获取其Archetype,从而快速访问对应的Component数据。
EntityGroupManager
管理与ComponentSystem运作息息相关的ComponentGroup。从每个ComponentSystem中收集其需要关注的Component集合,同时在System的每次Update前更新这个集合,同样的集合只会存在一个。
Job System概述
Unity C# Job System允许用户编写与Unity其余部分良好交互的多线程代码,并使编写正确的代码变得更加容易。
编写多线程代码可以提供高性能的好处。其中包括显着提高帧速率和延长移动设备的电池寿命。
C# Job System的一个重要方面是它与Unity内部使用的集成(Unity的native job system)。用户编写的代码和Unity共享工作线程。这种合作避免了导致争用CPU资源的问题,并且可以创建比CPU核心更多的线程。
什么是Job System
Job System通过创建Job而不是线程来管理多线程代码。
Job System跨多个核心管理一组工作线程。它通常每个逻辑CPU核心有一个工作线程,以避免上下文切换(尽管它可能为操作系统或其他专用应用程序保留一些核心)。
Job System将Job放入作业队列中用来执行。Job System中的工作线程从作业队列中获取Job并执行它们。作业系统管理依赖关系并确保作业以适当的顺序执行。
什么是Job?
Job是完成一项特定任务的一小部分工作。Job接收参数并对数据进行操作,类似于方法调用的行为方式。Job可以是独立的,也可以是依赖的(需要等其他作业完成后,然后才能运行。)
什么是Job依赖?
在复杂的系统中,如游戏开发所需的系统,每个工作都不可能是独立的。一项工作通常是为下一份工作准备数据。作业了解并支持依赖关系以使其发挥作用。如果jobA对jobB依赖,则Job System确保在完成jobA之前不会开始执行jobB。
C#Job System中的安全系统
竞争条件
编写多线程代码时,总是存在竞争条件的风险。当一个操作的输出取决于其控制之外的另一个过程的时间的时候,就会发生竞争条件。
竞争条件并不总是一个Bug,但它是不确定行为的来源。当竞争条件确实导致Bug时,可能很难找到问题的根源,因为它取决于时间,因此您只能在极少数情况下重新复现问题。调试它可能会导致问题消失,因为断点和日志记录(Logging)可以改变单个线程的时间。竞争条件是编写多线程代码时最重大的挑战。
安全系统
为了更容易编写多线程代码,Unity C#作业系统可以检测所有潜在的竞争条件,并保护您免受可能导致的Bug的影响。
例如:如果C#Job System将主线程中代码中的数据引用发送到Job中,则无法验证主线程是否在作业写入数据的同时读取数据。这种情况就会创建竞争条件。
C#Job System通过向每个作业发送它需要操作的数据的拷贝副本来解决这个问题,而不是对主线程中的数据的引用。这种拷贝副本隔离数据,从而消除竞争条件。
C#Job System复制数据的方式意味着作业只能访问blittable数据类型。在托管代码和本机代码之间传递时,这些类型不需要转换。
C#Job System可以使用memcpy复制blittable类型,并在Unity的托管和本机部分之间传输数据。它在调度Job时用memcpy将数据放入本机内存,并在执行作业时为托管端提供对该拷贝副本的访问权限。有关更多信息,请参阅计划作业
NativeContainer
NativeContainer
安全系统复制数据的过程的缺点是它还隔离了每个副本中Job的结果。要克服此限制,您需要将NativeContainer结果存储在一种名为NativeContainer的共享内存中。
什么是NativeContainer?
NativeContainer是托管值类型,为本机内存提供相对安全的C#包装器。它包含指向非托管分配的指针。与Unity C#作业系统一起使用时,一个 NativeContainer允许Job访问与主线程共享的数据,而不是使用拷贝副本数据。
有哪些类型的NativeContainer?
Unity附带一个NativeContainer名为NativeArray的程序。您还可以使用NativeSlice操作一个NativeArray来获取NativeArray从指定位置到指定长度的子集。
注意:实体组件系统(ECS)包扩展了Unity.Collections命名空间以包括其他类型的NativeContainer:
- NativeList- 可调整大小的NativeArray
- NativeHashMap - 键值对
- NativeMultiHashMap - 每个键有多个值
- NativeQueue- 先进先出(FIFO)队列
NativeContainer和安全系统
安全系统内置于所有NativeContainer类型。它跟踪NativeContainer中正在阅读和写入的内容。
注意: 所有NativeContainer类型的安全检查(例如越界检查,重新分配检查和竞争条件检查)仅在Unity Editor和Play模式下可用。
该安全系统的一部分是DisposeSentinel和AtomicSafetyHandle。该DisposeSentinel检测内存泄漏,如果你没有正确地释放你的内存,就会报错。内存泄漏发生后很久就会发生内存泄漏错误。
使用AtomicSafetyHandle转移NativeContainer代码的所有权。例如,如果两个调度Job写入相同NativeArray,则安全系统会抛出一个异常,并显示一条明确的错误消息,说明解决问题的原因和方法。当你调度违规Job时,安全系统会抛出此异常。
在这种情况下,您可以调度具有依赖关系的Job。第一个Job可以写入NativeContainer,一旦完成执行,下一个Job就可以安全地读取和写入上一个Job相同的NativeContainer。从主线程访问数据时,读写限制也适用。安全系统允许多个Job并行读取相同的数据。
默认情况下,当Job有权访问一个NativeContainer时,它具有读写访问权限。此配置可能会降低性能。C#Job System不允许您在一个job正在写入NativeContainer时同时调度另外一个对NativeContainer 有写入权限的Job。
如果作业不需要写入一个 NativeContainer,请使用[ReadOnly]属性标记NativeContainer,如下所示:
[ReadOnly]
public NativeArray<int> input;
在上面的示例中,您可以与其他对第一个也具有只读访问权限的作业同时执行作业NativeArray。
注意:无法防止从作业中访问静态数据。访问静态数据会绕过所有安全系统,并可能导致Unity崩溃。有关更多信息,请参阅C#作业系统提示和故障排除。
NativeContainer分配器
当创建 NativeContainer时,必须指定所需的内存分配类型。分配类型取决于Job运行的时间长度。通过这种方式,您可以定制分配以在每种情况下获得最佳性能。
NativeContainer内存分配和释放有三种分配器类型。在实例化你的NativeContainer时候需要指定合适的一个类型。
Allocator.Temp 分配的时候最快。它适用于寿命为一帧或更少的分配。您不应该使用Temp将NativeContainer分配传递给Jobs。您还需要在从方法(例如MonoBehaviour.Update,或从本机代码到托管代码的任何其他回调)调用返回之前调用该方法Dispose()。
Allocator.TempJob 是一个比Temp慢的分配,但速度比Persistent快。它适用于四帧生命周期内的分配,并且是线程安全的。如果在四个帧内没有调用Dispose,则控制台会打印一个从本机代码生成的警告。大多数小型Jobs都使用这个NativeContainer分配类型。
Allocator.Persistent 是最慢的分配,只要你需要它,就一直存在。并且如果有必要的话,可以持续整个应用程序的生命周期。它是直接调用malloc的包装器。较长的Jobs可以使用此NativeContainer分配类型。你不应该使用Persistent在性能至关重要的地方使用。
NativeArray<float> result = new NativeArray<float>(1, Allocator.TempJob);
注意:上例中的数字1表示NativeArray的大小。在这种情况下,它只有一个数组元素(因为它只存储一个数据result)
创建Jobs
要在Unity中创建作业,您需要实现IJob接口。IJob允许您调度可以与其他正在运行的Job并行运行的单个Job。
注意: “Job”是Unity中用于实现IJob接口的任何结构的集合术语。
要创建Jobs,您需要:
- 创建一个继承自IJob的结构体
- 添加Jobs使用的成员变量(blittable类型或NativeContainer类型)
- 在结构体中实现一个继承自IJob接口的Execute的方法
当执行job时,这个Execute方法在单个核心上运行一次.
注意: 在设计job时,请记住它们在数据副本上运行,除非是NativeContainer。因此,从主线程中的作业访问数据的唯一方法是写入NativeContainer。
简单job定义的示例:
public struct MyJob : IJob
{
public float a;
public float b;
public NativeArray<float> result;
public void Execute()
{
result[0] = a + b;
}
}
调度Jobs
要在主线程中调度作业,您必须:
- 实例化作业
- 填充作业的数据
- 调用Schedule方法
调用Schedule将Job放入Job队列中以便在适当的时间执行。一旦调度,你就不能打断Job的运行。
注意: 您只能在主线程调用Schedule。
// Create a native array of a single float to store the result.
//This example waits for the job to complete for illustration purposes
NativeArray<float> result = new NativeArray<float>(1, Allocator.TempJob);
// Set up the job data
MyJob jobData = new MyJob();
jobData.a = 10;
jobData.b = 10;
jobData.result = result;
// Schedule the job
JobHandle handle = jobData.Schedule();
// Wait for the job to complete
handle.Complete();
// All copies of the NativeArray point to the same memory, you can access the result in "your" copy of the NativeArray
float aPlusB = result[0];
// Free the memory allocated by the result array
result.Dispose();
JobHandle和依赖关系
当您调用作业的Schedule方法时,它将返回JobHandle。您可以在代码中使用JobHandle 作为其他Job的依赖关系。如果Job取决于另一个Job的结果,您可以将第一个作业JobHandle作为参数传递给第二个作业的Schedule方法,如下所示:
JobHandle firstJobHandle = firstJob.Schedule();
secondJob.Schedule(firstJobHandle);
结合依赖关系
如果作业有许多依赖项,则可以使用JobHandle.CombineDependencies方法合并它们。CombineDependencies允许您将它们传递给Schedule方法。
NativeArray<JobHandle> handles = new NativeArray<JobHandle>(numJobs, Allocator.TempJob);
// Populate `handles` with `JobHandles` from multiple scheduled jobs...
JobHandle jh = JobHandle.CombineDependencies(handles);
在主线程中等待Job
在主线程中使用JobHandle强迫让你的代码等待您的Job执行完毕。要做到这一点,调用JobHandle的方法 Complete。此时,您知道主线程可以安全地访问正在使用job 的NativeContainer。
注意: 在调度Job时,Job不会开始执行。如果您正在等待主线程中的Job,并且您需要访问正在使用Job的NativeContainer数据,则可以调用该方法JobHandle.Complete。此方法从内存高速缓存中刷新作业并启动执行过程。调用JobHandle的Complete方法将返回NativeContainer的所有权到主线程。您需要再次调用 JobHandle 的Complete方法以便于再次从主线程安全地访问这些NativeContainer类型。也可以通过从Job的依赖中的JobHandle的Complete方法调用返回主线程上的所有权。例如,你可以调用jobA的Complete方法,或者也可以调用依靠JobA的JobB上的Complete方法。两者都会在调用Complete后在主线程上安全访问时使用jobA的NativeContainer类型。
否则,如果您不需要访问数据,则需要明确刷新批处理。为此,请调用静态方法JobHandle.ScheduleBatchedJobs。请注意,调用此方法可能会对性能产生负面影响。
多个Jobs和dependencies的示例:
Job code:
public struct MyJob : IJob
{
public float a;
public float b;
public NativeArray<float> result;
public void Execute()
{
result[0] = a + b;
}
}
public struct AddOneJob : IJob
{
public NativeArray<float> result;
public void Execute()
{
result[0] = result[0] + 1;
}
}
主线程代码:
// Create a native array of a single float to store the result in.
//This example waits for the job to complete
NativeArray<float> result = new NativeArray<float>(1, Allocator.TempJob);
// Setup the data for job #1
MyJob jobData = new MyJob();
jobData.a = 10;
jobData.b = 10;
jobData.result = result;
// Schedule job #1
JobHandle firstHandle = jobData.Schedule();
// Setup the data for job #2
AddOneJob incJobData = new AddOneJob();
incJobData.result = result;
// Schedule job #2
JobHandle secondHandle = incJobData.Schedule(firstHandle);
// Wait for job #2 to complete
secondHandle.Complete();
// All copies of the NativeArray point to the same memory, you can access the result in "your" copy of the NativeArray
float aPlusB = result[0];
// Free the memory allocated by the result array
result.Dispose();
并行化job
当调度Jobs时,只能有一个job来进行一项任务。在游戏中,非常常见的情况是在一个庞大数量的对象上执行一个相同的操作。这里有一个独立的job类型叫做IJobParallelFor来处理此类问题。ParallelFor jobs当调度Jobs时,只能有一个job来进行一项任务。在游戏中,非常常见的情况是在一个庞大数量的对象上执行一个相同的操作。这里有一个独立的job类型叫做IJobParallelFor来处理此类问题。
注意:“并行化”job是Unity中所有实现了 IJobParallelFor 接口的结构的总称。
一个并行化job使用一个NativeArray存放数据来作为它的数据源。并行化job横跨多个核心执行。每个核心上有一个job,每个job处理一部分工作量。IJobParallelFor的行为很类似于IJob,但是不同于只执行一个Execute方法,它会在数据源的每一项上执行Execute方法。Execute方法中有一个整数型的参数。这个索引是为了在job的具体操作实现中访问和操作数据源上的单个元素。
一个定义并行化Job的例子:
struct IncrementByDeltaTimeJob: IJobParallelFor
{
public NativeArray<float> values;
public float deltaTime;
public void Execute (int index)
{
float temp = values[index];
temp += deltaTime;
values[index] = temp;
}
}
调度并行化job
当调度并行化job时,你必须指定你分割NativeArray数据源的长度。在结构中同时存在多个NativeArrayUnity时,C# Job System不知道你要使用哪一个NativeArray作为数据源。这个长度同时会告知C# Job System有多少个Execute方法会被执行。
在这个场景中,并行化job的调度会更复杂。当调度并行化任务时,C# Job System会将工作分成多个批次,分发给不同的核心来处理。每一个批次都包含一部分的Execute方法。随后C# Job System会在每个CPU核心的Unity原生Job System上调度最多一个job,并传递给这个job一些批次的工作来完成。
当一个原生job提前完成了分配给它的工作批次后,它会从其他原生job那里获取其剩余的工作批次。它每次只获取那个原生job剩余批次的一半,为了确保缓存局部性(cache locality)。
为了优化这个过程,你需要指定一个每批次数量(batch count)。这个每批次数量控制了你会生成多少job和线程中进行任务分发的粒度。使用一个较低的每批次数量,比如1,会使你在线程之间的工作分配更平均。它会带来一些额外的开销,所以有时增加每批次数量会是更好的选择。从每批次数量为1开始,然后慢慢增加这个数量直到性能不再提升是一个合理的策略。
调度并行化job的例子:
// Job adding two floating point values together
public struct MyParallelJob : IJobParallelFor
{
[ReadOnly]
public NativeArray<float> a;
[ReadOnly]
public NativeArray<float> b;
public NativeArray<float> result;
public void Execute(int i)
{
result[i] = a[i] + b[i];
}
}
主线程代码:
NativeArray<float> a = new NativeArray<float>(2, Allocator.TempJob);
NativeArray<float> b = new NativeArray<float>(2, Allocator.TempJob);
NativeArray<float> result = new NativeArray<float>(2, Allocator.TempJob);
a[0] = 1.1;
b[0] = 2.2;
a[1] = 3.3;
b[1] = 4.4;
MyParallelJob jobData = new MyParallelJob();
jobData.a = a;
jobData.b = b;
jobData.result = result;
// Schedule the job with one Execute per index in the results array and only 1 item per processing batch
JobHandle handle = jobData.Schedule(result.Length, 1);
// Wait for the job to complete
handle.Complete();
// Free the memory allocated by the arrays
a.Dispose();
b.Dispose();
result.Dispose();
Job System建议和故障排除
当你使用Unity C# Job System时,确保你遵守以下几点:C# Job System tips and troubleshooting当你使用Unity C# Job System时,确保你遵守以下几点:
1. 不要从一个job中访问静态的数据
在所有的安全性系统中你都应当避免从一个job中访问静态数据。如果你访问了错误的数据,你可能会使Unity崩溃,通常是以意想不到的方式。举例来说,访问一个MonoBehaviour可以导致域重新加载时崩溃。
注意:因为这个风险,未来版本的Unity会通过静态分析来阻止全局变量在job中的访问。如果你确实在job中访问了静态数据,你应当预见到你的代码会在Unity未来的版本中报错。
2. 刷新已调度的批次
当你希望你的job开始执行时,你可以通
过JobHandle.ScheduleBatchedJobs来刷新已调度的批次。注意调用这个接口时会对性能产生负面的影响。不刷新批次将会延迟调度job,直到主线程开始等待job的结果。在任何其他情况中,你应当调用JobHandle.Complete来开始执行过程。
注意:在Entity Component System(ECS)中批次会暗中为你进行刷新,所以调用JobHandle.ScheduleBatchedJobs是不必要的。
3. 不要试图去更新NativeContainer的内容
由于缺乏引用返回值,不可能去直接修改一个NativeContainer的内容。例如,nativeArray[0]++ ;和 var temp = nativeArray[0]; temp++;一样,都没有更新nativeArray中的值。
你必须从一个index将数据拷贝到一个局部临时副本,修改这个副本,并将它保存回去,像这样:
MyStruct temp = myNativeArray[i];
temp.memberVariable = 0;
myNativeArray[i] = temp;
4. 调用JobHandle.Complete来重新获得归属权
在主线程重新使用数据前,追踪数据的所有权需要依赖项都完成。只检查JobHandle.IsCompleted是不够的。你必须调用JobHandle.Complete来在主线程中重新获取NaitveContainer类型的所有权。调用Complete同时会清理安全性系统中的状态。不这样做的话会造成内存泄漏。这个过程也在你每一帧都调度依赖于上一帧job的新job时被采用。
5. 在主线程中调用Schedule和Complete
你只能在主线程中调用Schedule和Complete方法。如果一个job需要依赖于另一个,使用JobHandle来处理依赖关系而不是尝试在job中调度新的job。
6. 在正确的时间调用Schedule和Complete
一旦你拥有了一个job所需的数据,尽可能快地在job上调用Schedule,在你需要它的执行结果之前不要调用Complete。一个良好的实践是调度一个你不需要等待的job,同时它不会与当前正在运行的其他job产生竞争。举例来说,如果你在一帧结束和下一帧开始之前拥有一段没有其他job在运行的时间,并且可以接受一帧的延迟,你可以在一帧结束的时候调度一个job,在下一帧中使用它的结果。或者,如果这个转换时间已经被其他job占满了,但是在一帧中有一大段未充分利用的时段,在这里调度你的job会更有效率。
7. 将NativeContainer标记为只读的
记住job在默认情况下拥有NativeContainer的读写权限。在合适的NativeContainer上使用[ReadOnly]属性可以提升性能。
8. 检查数据的依赖
在Unity的Profiler窗口中,主线程中的”WaitForJobGroup”标签表明了Unity在等待一个工人线程上的job结束。这个标签可能意味着你以某种方式引入了一个资源依赖,你需要去解决它。查找JobHandle.Complete来追踪你在什么地方有资源依赖,导致主线程必须等待。
9. 调试job
job拥有一个Run方法,你可以用它来替代Schedule从而让主线程立刻执行这个job。你可以使用它来达到调试目的。
10. 不要在job中开辟托管内存
在job中开辟托管内存会难以置信得慢,并且这个job不能利用Unity的Burst编译器来提升性能。Burst是一个新的基于LLVM的后端编译器技术,它会使事情对于你更加简单。它获取C# job并利用你平台的特定功能产生高度优化的机器码。
更多信息: