Barracuda AI网络推理
Unity实验室致力于改进一项最先进的研究,并开发出一个高效的神经系统推理引擎——Barracuda。深度学习长期以来一直局被限于超级计算机和离线计算之中,但由于计算能力的不断提高,它们在消费者级硬件上的实时可用性也在快速提升。有了Barracuda,Unity实验室希望Barracuda能快速的进入到创作者手中。得益于ML-Agents,神经网络已经被用于一些游戏开发中的人工智能应用中,但还有许多应用需要在实时游戏引擎中演示。比如:深度学习超采样,环境遮挡,全局光照,风格变换等等。
目前网络上看到基于 Barracuda 实现的效果有 画面风格迁移(类似后处理), 人脸识别, 面部捕捉,手势识别等, 更多相关的案例参考网页。
1. ONNX
1.1 简介
Open Neural Network Exchange(ONNX,开放神经网络交换)格式,是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移。
ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互。 ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,以开放源代码的方式托管在Github上。
目前官方支持加载ONNX模型并进行推理的深度学习框架有: Caffe2, PyTorch, MXNet,ML.NET,TensorRT 和 Microsoft CNTK,并且 TensorFlow 也非官方的支持ONNX。例如 Pytorch 导出onnx:
torch.onnx.export(
model,
(input1,input2),
"./trynet.onnx",
verbose=True,
input_names=input_names,
output_names=output_names
)
ONNX中的一些信息都被可视化展示了出来,例如文件格式ONNX v7,该文件的导出方pytorch1.10等等,这些信息都保存在ONNX格式的文件中。 如下面是使用 Netron 打开模型:
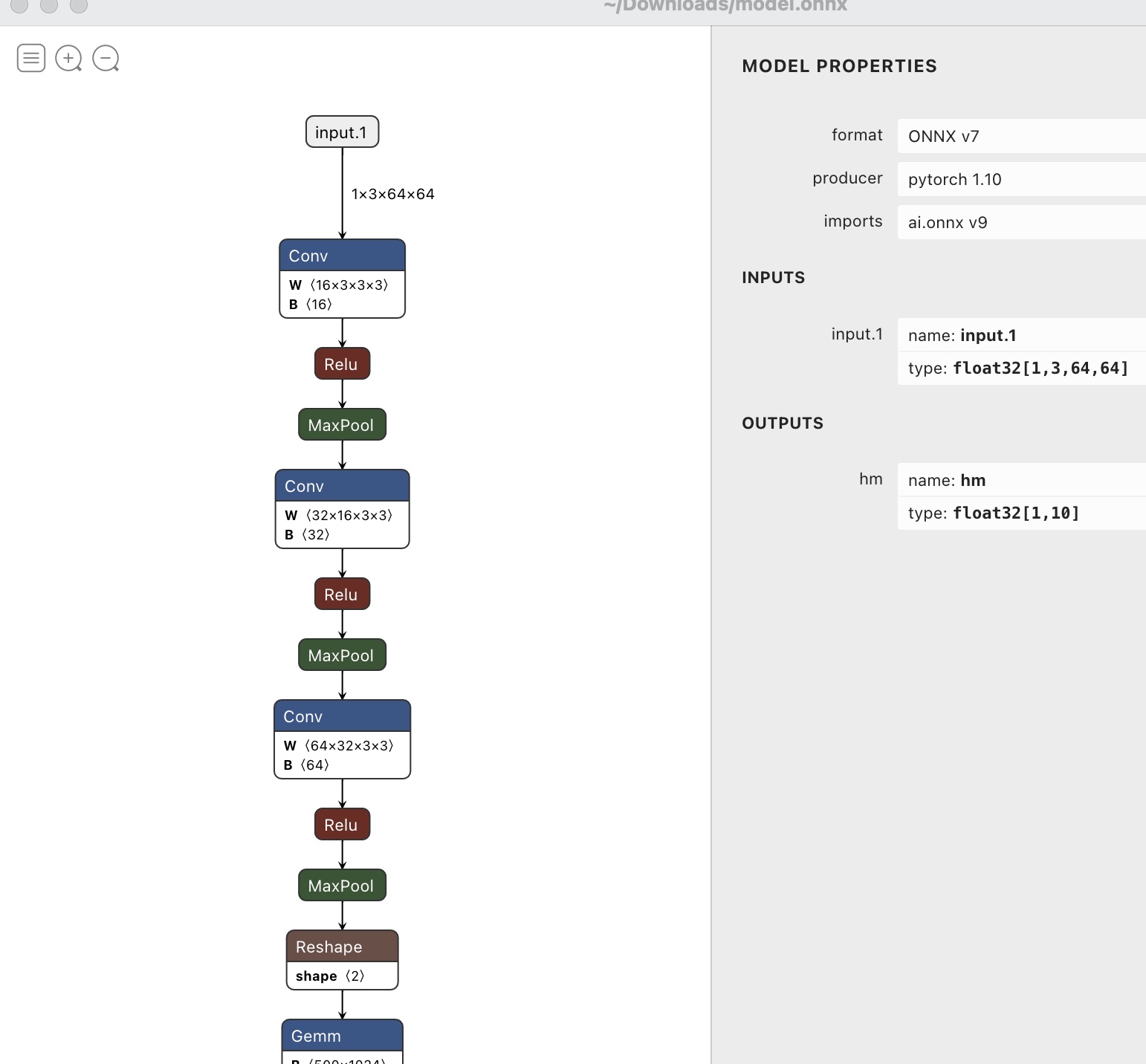
ONNX 文件内部是以Protobuf记录节点信息的, 当加载了一个ONNX之后,我们获得的就是一个ModelProto,它包含了一些版本信息,生产者信息和一个GraphProto。在GraphProto里面又包含了四个repeated数组,它们分别是node(NodeProto类型),input(ValueInfoProto类型),output(ValueInfoProto类型)和initializer(TensorProto类型),其中node中存放了模型中所有的计算节点,input存放了模型的输入节点,output存放了模型中所有的输出节点,initializer存放了模型的所有权重参数。
- ModelProto
- GraphProto
- NodeProto
- ValueInfoProto
- TensorProto
- AttributeProto
2.1 Barracuda 处理 onnx
Barracuda 内置了ONNX的解析, 并可以为之预览信息。 当在Unity中选中一个.onnx或者.nn后缀的一个模型文件之后, 会首先调用onnx convert的接口解析出onnx的内部结构, 然后在 ONNXModelImporterEditor 类里进行EditorGUI的绘制。
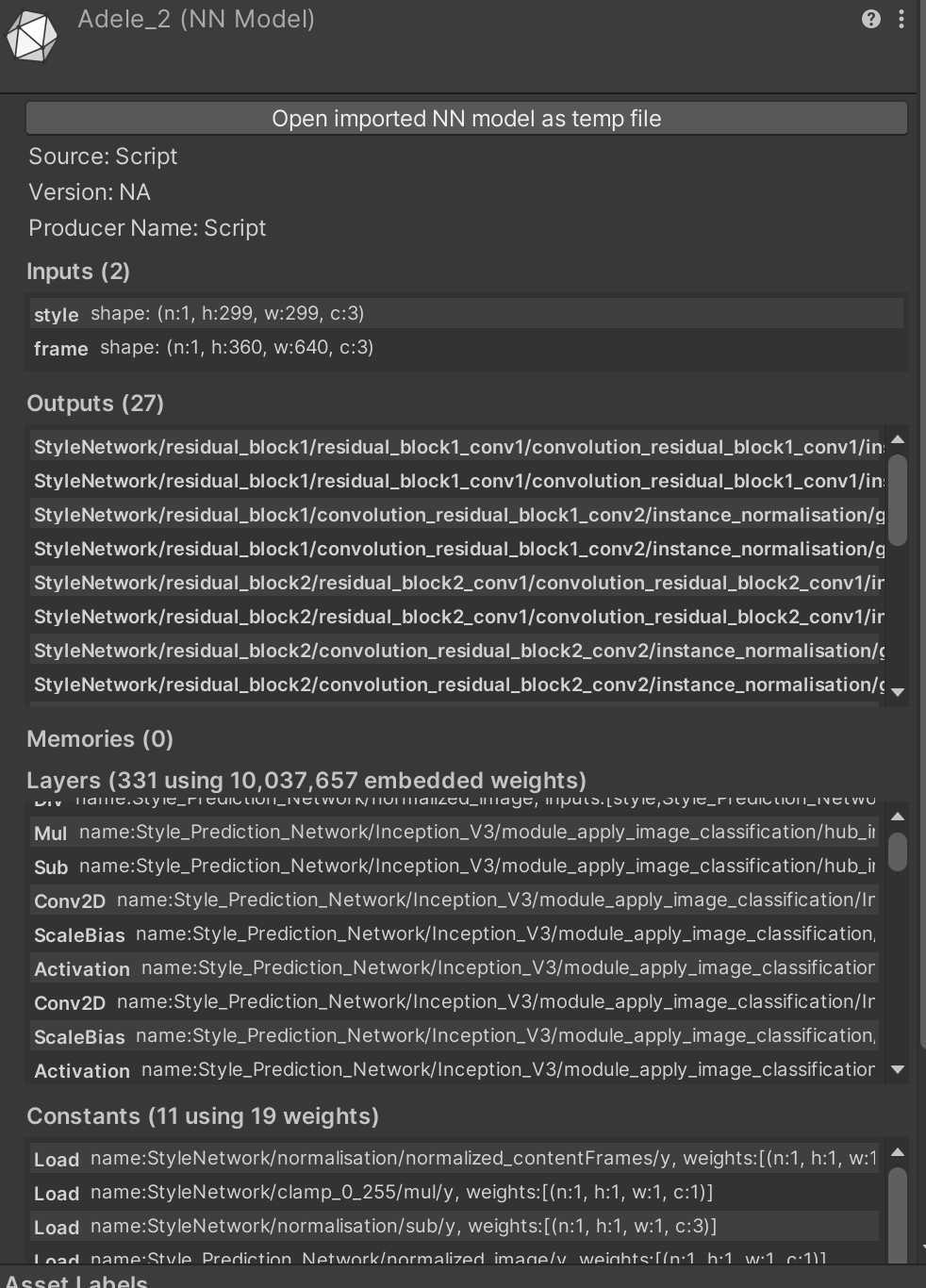
此界面可以清晰看出网络的输入、输出、版本以及内存开销等信息。
算子扩展
遍历 Barracuda对算子的支持, 像主流的 Dense, Conv, Upsample, MaxPool, Normalization, LSTM都得到了支持。 详细的支持列表如下:
public enum Type
{
/// <summary>
/// Dense layer
/// </summary>
Dense = 1,
/// <summary>
/// Matrix multiplication layer
/// </summary>
MatMul = 2,
/// <summary>
/// Rank-3 Dense Layer
/// </summary>
Dense3 = 3,
/// <summary>
/// 2D Convolution layer
/// </summary>
Conv2D = 20,
/// <summary>
/// Depthwise Convolution layer
/// </summary>
DepthwiseConv2D = 21,
/// <summary>
/// Transpose 2D Convolution layer
/// </summary>
Conv2DTrans = 22,
/// <summary>
/// Upsampling layer
/// </summary>
Upsample2D = 23,
/// <summary>
/// Max Pool layer
/// </summary>
MaxPool2D = 25,
/// <summary>
/// Average Pool layer
/// </summary>
AvgPool2D = 26,
/// <summary>
/// Global Max Pool layer
/// </summary>
GlobalMaxPool2D = 27,
/// <summary>
/// Global Average Pool layer
/// </summary>
GlobalAvgPool2D = 28,
/// <summary>
/// Border / Padding layer
/// </summary>
Border2D = 29,
/// <summary>
/// 3D Convolution layer
/// </summary>
Conv3D = 30,
/// <summary>
/// Transpose 3D Convolution layer (not yet implemented)
/// </summary>
Conv3DTrans = 32, // TODO: NOT IMPLEMENTED
/// <summary>
/// 3D Upsampling layer
/// </summary>
Upsample3D = 33,
/// <summary>
/// 3D Max Pool layer (not yet implemented)
/// </summary>
MaxPool3D = 35, // TODO: NOT IMPLEMENTED
/// <summary>
/// 3D Average Pool layer (not yet implemented)
/// </summary>
AvgPool3D = 36, // TODO: NOT IMPLEMENTED
/// <summary>
/// 3D Global Max Pool layer (not yet implemented)
/// </summary>
GlobalMaxPool3D = 37, // TODO: NOT IMPLEMENTED
/// <summary>
/// 3D Global Average Pool layer (not yet implemented)
/// </summary>
GlobalAvgPool3D = 38, // TODO: NOT IMPLEMENTED
/// <summary>
/// 3D Border / Padding layer
/// </summary>
Border3D = 39,
/// <summary>
/// Activation layer, see `Activation` enum for activation types
/// </summary>
Activation = 50,
/// <summary>
/// Scale + Bias layer
/// </summary>
ScaleBias = 51,
/// <summary>
/// Normalization layer
/// </summary>
Normalization = 52,
/// <summary>
/// LRN (Local Response Normalization) layer
/// </summary>
LRN = 53,
/// <summary>
/// Dropout layer (does nothing in inference)
/// </summary>
Dropout = 60,
/// <summary>
/// Random sampling from normal distribution layer
/// </summary>
RandomNormal = 64,
/// <summary>
/// Random sampling from uniform distribution layer
/// </summary>
RandomUniform = 65,
/// <summary>
/// Random sampling from multinomial distribution layer
/// </summary>
Multinomial = 66,
/// <summary>
/// OneHot layer
/// </summary>
OneHot = 67,
/// <summary>
/// TopK indices layer
/// </summary>
TopKIndices = 68,
/// <summary>
/// TopK values layer
/// </summary>
TopKValues = 69,
/// <summary>
/// NonZero layer
/// </summary>
NonZero = 70,
/// <summary>
/// Range layer
/// </summary>
Range = 71,
/// <summary>
/// Addition layer
/// </summary>
Add = 100,
/// <summary>
/// Subtraction layer
/// </summary>
Sub = 101,
/// <summary>
/// Multiplication layer
/// </summary>
Mul = 102,
/// <summary>
/// Division layer
/// </summary>
Div = 103,
/// <summary>
/// Power layer
/// </summary>
Pow = 104,
/// <summary>
/// Min layer
/// </summary>
Min = 110,
/// <summary>
/// Max layer
/// </summary>
Max = 111,
/// <summary>
/// Mean layer
/// </summary>
Mean = 112,
/// <summary>
/// Reduce L1 layer (not yet implemented)
/// </summary>
ReduceL1 = 120, // TODO: NOT IMPLEMENTED
/// <summary>
/// Reduce L2 layer (not yet implemented)
/// </summary>
ReduceL2 = 121, // TODO: NOT IMPLEMENTED
/// <summary>
/// Reduce LogSum layer (not yet implemented)
/// </summary>
ReduceLogSum = 122, // TODO: NOT IMPLEMENTED
/// <summary>
/// Reduce LogSumExp layer (not yet implemented)
/// </summary>
ReduceLogSumExp = 123, // TODO: NOT IMPLEMENTED
/// <summary>
/// Reduce with Max layer
/// </summary>
ReduceMax = 124,
/// <summary>
/// Reduce with Mean layer
/// </summary>
ReduceMean = 125,
/// <summary>
/// Reduce with Min layer
/// </summary>
ReduceMin = 126,
/// <summary>
/// Reduce with Prod layer
/// </summary>
ReduceProd = 127,
/// <summary>
/// Reduce with Sum layer
/// </summary>
ReduceSum = 128,
/// <summary>
/// Reduce with SumSquare layer (not yet implemented)
/// </summary>
ReduceSumSquare = 129, // TODO: NOT IMPLEMENTED
/// <summary>
/// Logic operation: Greater layer
/// </summary>
Greater = 140,
/// <summary>
/// Logic operation: GreaterEqual layer
/// </summary>
GreaterEqual = 141,
/// <summary>
/// Logic operation: Less layer
/// </summary>
Less = 142,
/// <summary>
/// Logic operation: LessEqual layer
/// </summary>
LessEqual = 143,
/// <summary>
/// Logic operation: Equal layer
/// </summary>
Equal = 144,
/// <summary>
/// Logic operation: LogicalOr layer
/// </summary>
LogicalOr = 145,
/// <summary>
/// Logic operation: LogicalAnd layer
/// </summary>
LogicalAnd = 146,
/// <summary>
/// Logic operation: LogicalNot layer
/// </summary>
LogicalNot = 147,
/// <summary>
/// Logic operation: LogicalXor layer
/// </summary>
LogicalXor = 148,
/// <summary>
/// Logic operation: Where layer
/// </summary>
Where = 149,
/// <summary>
/// Logic operation: Sign layer
/// </summary>
Sign = 150,
/// <summary>
/// Reflection padding layer
/// </summary>
Pad2DReflect = 160,
/// <summary>
/// Symmetric padding layer
/// </summary>
Pad2DSymmetric = 161,
/// <summary>
/// Edge padding layer
/// </summary>
Pad2DEdge = 162,
/// <summary>
/// ArgMax layer
/// </summary>
ArgMax = 163,
/// <summary>
/// ArgMin layer
/// </summary>
ArgMin = 164,
/// <summary>
/// ConstantOfShape layer
/// </summary>
ConstantOfShape = 199,
/// <summary>
/// Flatten layer
/// </summary>
Flatten = 200,
/// <summary>
/// Reshape layer
/// </summary>
Reshape = 201,
/// <summary>
/// Transpose layer
/// </summary>
Transpose = 202,
/// <summary>
/// Squeeze layer (not fully supported)
/// </summary>
Squeeze = 203, // TODO: NOT IMPLEMENTED
/// <summary>
/// Unsqueeze layer (not fully supported)
/// </summary>
Unsqueeze = 204, // TODO: NOT IMPLEMENTED
/// <summary>
/// Gather layer
/// </summary>
Gather = 205,
/// <summary>
/// Depth to space layer
/// </summary>
DepthToSpace = 206,
/// <summary>
/// Space to depth layer
/// </summary>
SpaceToDepth = 207,
/// <summary>
/// Expand layer
/// </summary>
Expand = 208,
/// <summary>
/// 2D Resample layer
/// </summary>
Resample2D = 209,
/// <summary>
/// Concat layer
/// </summary>
Concat = 210,
/// <summary>
/// Strided slice layer
/// </summary>
StridedSlice = 211,
/// <summary>
/// Tile layer
/// </summary>
Tile = 212,
/// <summary>
/// Shape layer
/// </summary>
Shape = 213,
/// <summary>
/// Non max suppression layer
/// </summary>
NonMaxSuppression = 214,
/// <summary>
/// LSTM
/// </summary>
LSTM = 215,
/// <summary>
/// Constant load layer (for internal use)
/// </summary>
Load = 255
}
Barracuda 对每个算子提供了不同版本的实现, 有的基于 CPU 也有基于GPU的, cpu还有基于 Burst的版本, Gpu 基于 Compute Shader去实现。 比如说 Conv2D 这个算子, 这里可以看到一共九种实现方式:
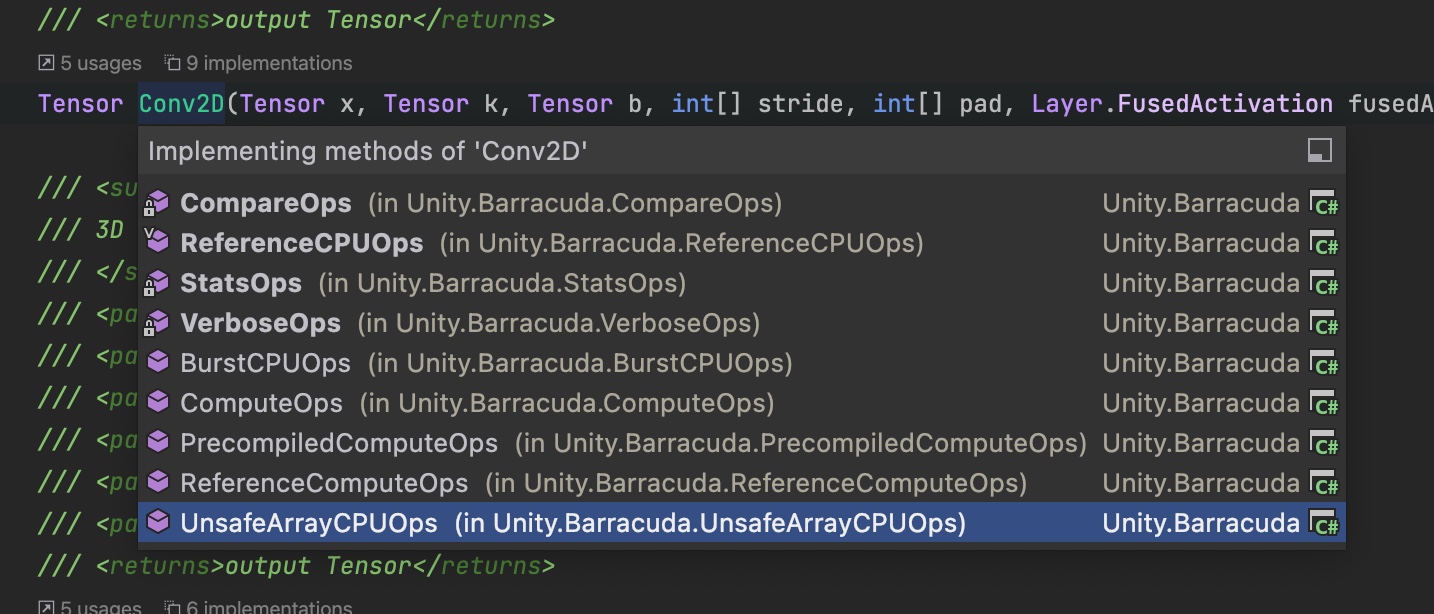
注意: VerboseOps并不是实现, 里面只是打印Layer的信息, 比如说 Weights/权重 和 bias/偏移 这些参数。 也许为了更好的调式<打印>吧。
枚举值里也并不是所有的都实现了, 比如说: ReduceL1, ReduceL2, ReduceLogSum等
if (l.type == Layer.Type.ReduceL1 ||
l.type == Layer.Type.ReduceL2 ||
l.type == Layer.Type.ReduceLogSum ||
l.type == Layer.Type.ReduceLogSumExp ||
l.type == Layer.Type.ReduceSumSquare)
{
throw new NotImplementedException("This reduction operation is not implemented yet!");
}
如果想要扩展想要的算子, 可以在IOps.cs 定义相关的接口, 然后在不同的类中实现,比如使用Burst, 就在 bURSTCPUOps类中实现该接口, 如果在GPU上运行,就不妨再 ComputeOps 类中实现。 然后添加对应的枚举值, 在GenericWorker类中根据对应的枚举值, 创建对应算子的Layer。
网络模型
Barracuda 更擅长处理的图像, 模型的输入一般 RenderTexture 或者 RenderTextureArray,barracuda提供了一个接口 去实现RT和Tensor之间的相互转换。
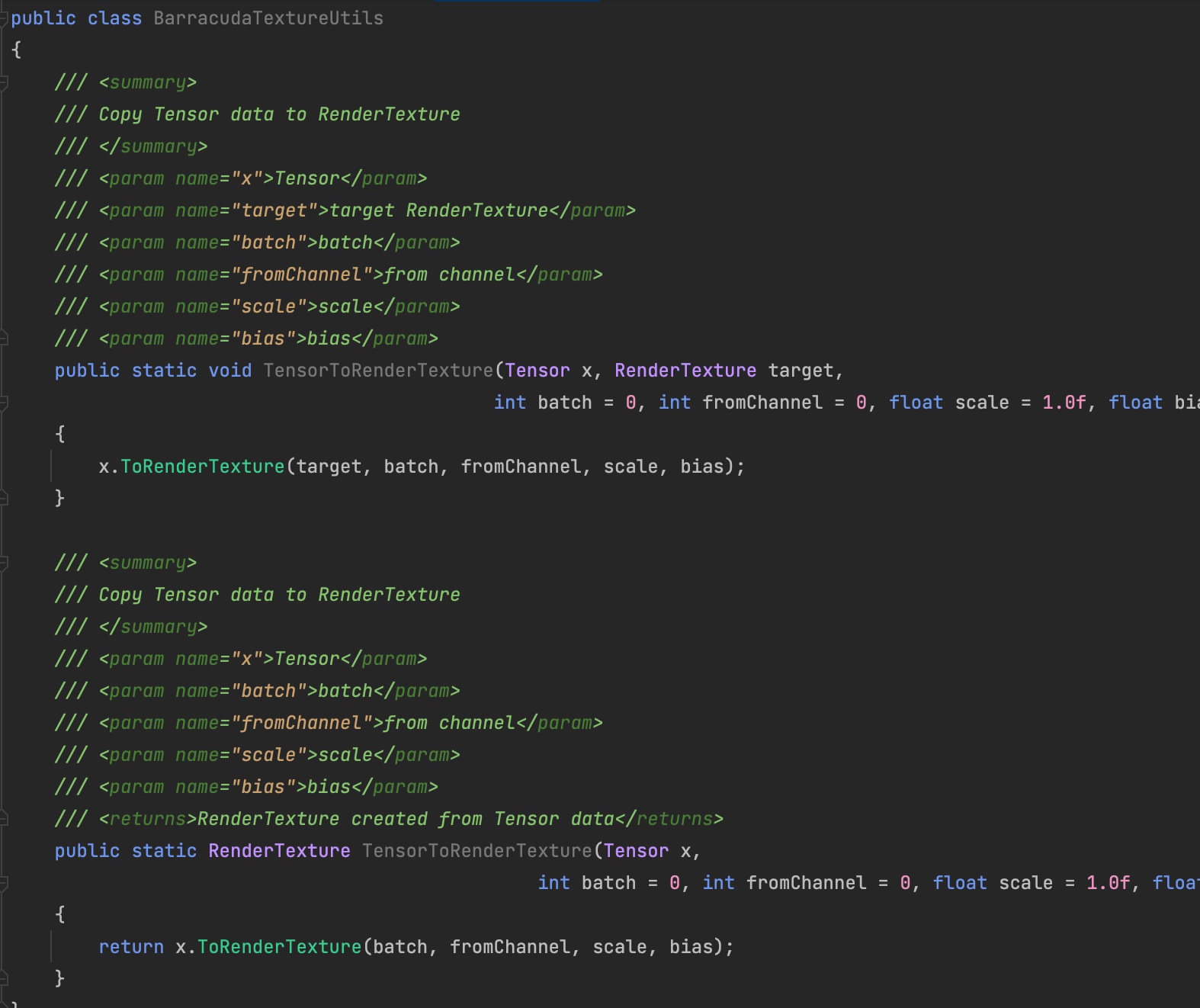
网络的执行
使用WorkerFactory创建一个网络, 调用 Execute 执行就可以了。
model.layers = layerList;
Model.Input input = model.inputs[1];
input.shape[0] = 0;
input.shape[1] = 1080;//TODO get framebuffer size rather than hardcoded value
input.shape[2] = 1920;
input.shape[3] = 3;
model.inputs = new List<Model.Input> { model.inputs[1] };
// 创建网络, model里包含了所有Layer参数
worker = WorkerFactory.CreateWorker(WorkerFactory.ValidateType(internalSetup.workerType), model, verbose);
Dictionary<string, Tensor> temp = new Dictionary<string, Tensor>();
var inputTensor = new Tensor(input.shape, input.name);
temp.Add("frame", inputTensor);
// 执行
worker.Execute(temp);
获取结果:
如果知道layer的名字的话, 每个Layer执行的结果都可以获取到, 这也包含了网络的最后一层的输出:
var tensors = worker.PeekConstants(layerNameToPatch[i]);
这里拿到的是Tensor类型, 如果用来显示获取计算的话, 还需要转换成Texture/RT。
结语
Barracuda可以看成unity版本的 Tensorflow, Pytorch 框架, 并且由于unity引擎的跨平台特性, 所以天生对多个平台的支持, 特别是手机(Android\IOS)平台。 但与其他tensorflow等不同的是, tf维护一个session, 直接在gpu上跑整个网络, 不像barracuda这样每个layer 都存在cpu和gpu交互, 一定程度降低了运行效率。