强化学习-游戏AI Trainning (一)
强化学习是一类算法, 是让计算机实现从一开始什么都不懂, 脑袋里没有一点想法, 通过不断地尝试, 从错误中学习, 最后找到规律, 学会了达到目的的方法. 这就是一个完整的强化学习过程. 实际中的强化学习例子有很多. 比如近期最有名的 Alpha go, 机器头一次在围棋场上战胜人类高手, 让计算机自己学着玩经典游戏 Atari, 这些都是让计算机在不断的尝试中更新自己的行为准则, 从而一步步学会如何下好围棋, 如何操控游戏得到高分. 既然要让计算机自己学, 那计算机通过什么来学习呢?
记得之前转载过一篇 Unity 官方的文章,就是关于在 Unity 中应用强化学习(Q-Q_Learning)学习的例子,不过那篇文章过多的讲述环境配置,而本节将重点讲述强化学习的实现原理。
目前强化学习的算法很多,诸如说 Q_Learning, Sarsa, DQN, OpenAI gym。等。 今天我们主要讲述 q_learning的实现,并简要介绍其他算法的实现。本节用到的代码都上传到 github 网站, 欢迎点击下载。
Q_learing
q-learning的伪代码先看这部分,很重要

简单的算法语言描述就是
开始执行任务,随机选择一个初始动作,执行这些动作。若未达到目标状态,则执行一下几步:
- 在当前状态s所有可能的行为中选择一个a
- 利用a得到下一个状态s_
- 计算Q(s,a) (对当前的行为进行学习)
- 下一个状态等于当前状态
- 开始下一个循环
公式描述:
GAMMA(gamma 是对未来 reward(分数) 的衰减值),ALPHA(学习率),EPSILON(策略)
GAMMA是什么意思呢,就是对获取过的奖励为了防止再次获取后得到的分数一样,于是对reward进行一个衰减,这样就会有长远的眼光,机器人就不只专注于眼前的奖励了
EPSILON 是一种策略,0.8代表的意思就是我们有80%的概率来选择之前的经验剩下的20%的概率来进行新的探索。
如果你还不很理解强化学习,下面通过一段小视频来学习下吧。
游戏应用
我们将第次增加难度,来增加难度。
难度一:
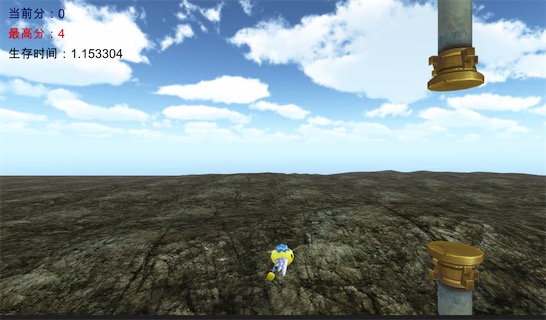
游戏过程是这样的,一只刚出生的雏鸟还不会飞。现在妈妈教它飞行。小鸟拍一下翅膀,它将可以向上飞行一段时间,但飞得过高,会消耗太多的能量,最终累死;如果没有拍翅膀,它将滑翔降落,最终跌到地上摔死。小鸟死亡,游戏结束。通过训练,小鸟掌握了拍翅膀的节奏,我们每15帧替小鸟做一次决策,看是否拍打翅膀,通过训练,我们将使小鸟能一直在天空中平衡地飞行。

本节中演示的内容代码你需要在unity做如下设置, GameManager中的istrainning需要勾上,mode选择internal。
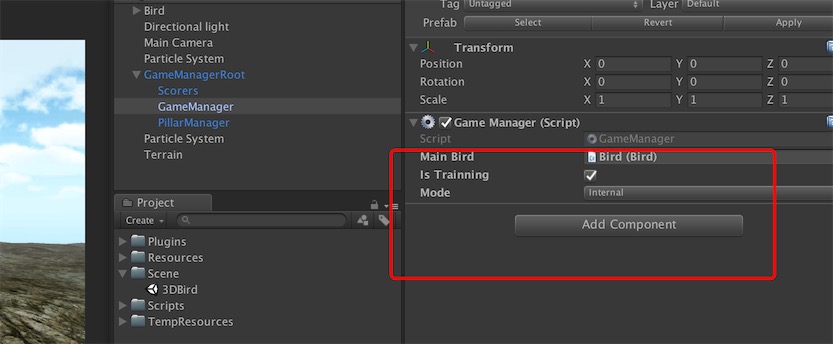
首先呢,我们在 Unity 实现 q_learning算法。在后面的章节中,我们将导出包,在 python 中训练,并且通过 Tensorboard,我们观察模型的学习率(alpha),衰减(gamma)以及生存时间的变化。
// greedy police
float epsilon = 0.9f;
// learning rate
float alpha = 0.1f;
//discount factor
float gamma = 0.9f;
首先我们定义 q_learning里面的几个变量值,如上所示,接着我们定义 Q_Table:
/// <summary>
/// Dictionary做二维表,key 是代表的状态,
/// Row 存储对应的 action 的 Q值
/// </summary>
Dictionary<int, Row> q_table;
public class Row
{
/// <summary>
/// 拍翅膀
/// </summary>
public float pad;
/// <summary>
/// 继续滑翔
/// </summary>
public float stay;
}
首先呢,我们把鸟position 的 y 坐标取值范围是[-5,5]分为十种种状态,我们定义鸟的状态1-10,由鸟的坐标转换状态。
int v = (int)transform.position.y + 5;
return Mathf.Clamp(v, 0, 10);我们更新 q表通过如下方法实现:
/**
更新 Q_TABLE
*/
public void UpdateState(int state, int state_, int rewd, bool action)
{
if (q_table != null)
{
Row row = q_table[state_];
float max = row.pad > row.stay ? row.pad : row.stay;
float q_target = rewd + gamma * max;
float q_predict = action ? q_table[state].pad : q_table[state].stay;
float add = alpha * (q_target - q_predict);
if (rewd != 0) Debug.Log("state:" + state + " rewd:" + rewd + " add:" + add);
if (action)
{
q_table[state].pad += add;
}
else
{
q_table[state].stay += add;
}
Debug.Log("state:" + state + " rewd:" + rewd + " action:" + action);
}
}我们以每15帧一个心跳(Tick), 根据 q_table 做出相应的动作,并且根据公式和 Reward 更新 q_table。
/*
comment: tick time is 15f
*/
public void OnTick()
{
int state = GetCurrentState();
if (last_state != -1)
{
//cul last loop
UpdateState(last_state, state, last_r, last_action);
}
//do next loop
bool action = choose_action(state);
GameManager.S.RespondByDecision(action);
last_r = 1;
last_state = state;
last_action = action;
}
在训练完成后,我们导出 q_table,在下次加载的时候再导入,我们就可以迁移到别的设备上了。导出的时候,为了方便观察,现在我们到处 csv 结构的,可以直接在 Excel 里看每个状态的 q 值。 由于当前难度较低,我们的状态(state)比较有限, 所以我们存成 csv 这样的。后面随着状态的急速增加,我们考虑使用 protobuff (二进制)的格式来导出。
/// <summary>
/// 导出q_table
/// </summary>
public void exportQTable()
{
Debug.Log(save_path);
FileStream fs = new FileStream(save_path, FileMode.OpenOrCreate, FileAccess.Write);
StreamWriter sw = new StreamWriter(fs);
foreach (var item in q_table)
{
string line = item.Key + "," + item.Value.pad + "," + item.Value.stay;
sw.WriteLine(line);
}
sw.Close();
fs.Close();
}
/// <summary>
/// 游戏进入时 加载q_table
/// </summary>
private void loadQTable()
{
if (q_table == null) q_table = new Dictionary<int, Row>();
if (File.Exists(save_path))
{
FileStream fs = new FileStream(save_path, FileMode.Open, FileAccess.Read);
StreamReader sr = new StreamReader(fs);
while (true)
{
string line = sr.ReadLine();
if (string.IsNullOrEmpty(line)) break;
string[] ch = line.Split(':');
if (ch.Length >= 3)
{
int key = int.Parse(ch[0]);
float pad = float.Parse(ch[1]);
float stay = float.Parse(ch[2]);
Row row = new Row() { stay = stay, pad = pad };
if (!q_table.ContainsKey(key)) q_table.Add(key, row);
else q_table[key] = row;
}
}
sr.Dispose();
fs.Dispose();
}
}
难度二:
在难度一的基础上,我们增加一块柱子。 通过训练,使小鸟不但能够平衡飞行,而且可以穿越过柱子。使用github 工程展示的时候,你需要在设置中添加宏ENABLE_PILLAR,如下图所示:
我们把 Pillar(柱子)的状态(state)也计算在内,Pillar 一共有五个状态,即我们根据和鸟的相对位置划分五个状态(state),Bird 的 position x坐标始终为0,移动的是 Pillar, Bird和 Pillar 运动是相对的。如下代码:
public int GetPillarMiniState()
{
int ret = 0;
if (pillars.Count > 0)
{
float _dis = pillars[0].transform.position.x;
if (_dis < 0) ret = 0;
else if (_dis <= 2) ret = 1;
else if (_dis <= 4) ret = 2;
else if (_dis <= 6) ret = 3;
else ret = 4;
}
return ret * 10;
}
Pillar 和Bird 一共组合了9X5=45种状态, 我们在构建 q_table的时候,代码如下:
/// <summary>
/// Bird [0-9)一共九个状态
/// Pillar [0-5) 一共5个状态
/// 状态统计 9x5=45个状态
/// </summary>
public void Build_Q_Table()
{
q_table = new Dictionary<int, Row>();
for (int i = 0; i < 9; i++)
{
#if ENABLE_PILLAR
for (int j = 0; j < 5; j++)
{
Row row = new Row() { pad = 0f, stay = 0f };
Debug.Log("i:" + i + " j:" + j + " val:" + (i + 10 * j));
q_table.Add(i + 10 * j, row);
}
#else
Row row = new Row() { pad = 0f, stay = 0f };
q_table.Add(i, row);
#endif
}
}
public int GetCurrentState()
{
#if ENABLE_PILLAR
int p_st = PillarManager.S.GetPillarMiniState();
int b_st = GameManager.S.mainBird.GetState();
return p_st + b_st;
#else
return GameManager.S.mainBird.GetState();
#endif
}
Reinforcement做选择还是和之前一样,由 epsilon概率来由 q_table 来决定,1-epsilon概率随机决定。
通过训练我们发现,小鸟很大概率可以穿过 pillar。
难度三:
循环增加柱子,且缺口不固定。通过训练,使小鸟能够穿越所有的柱子。所下图 所示:

这样柱子的状态就多了,还要考虑 pillar 缺口的情况,为了优化算法,我们只考虑小鸟前方的三个单元(1个单元的长度为2)所有柱子的情况,每一个 tick状态都会发生改变。
一个柱子由4个状态(缺口位置3个状态和是否存在柱子),考虑三个单元一共4X3=12种 state, 再组合 bird 的状态12x9=108种状态,随着state 的增加,q_table的方式记忆库来存 state 已经显得不合适了,后期我们还会引入神经网络,使用 DQN 的方式来优化算法。
还有就是我们所有的代码目前都是在 Unity 中实现的,后面我们还会把Tranning 提取出来在 Python中,Unity 只负责表现的东西。期待作者后续的更新吧。